
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
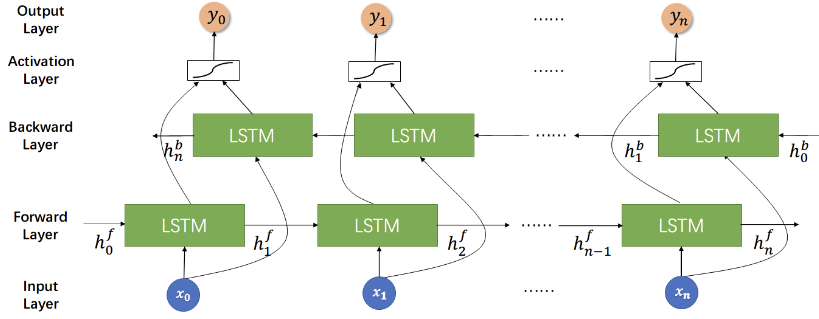
小丸子漫画 无广告版 BiLSTM(双向长短期记忆网络) 是一种循环神经网络(RNN)的变体,它在自然语言处理任务中非常有效,其中包括给定一个长句子预测下一个单词。
这种效果的主要原因包括以下几点:
长短期记忆网络(LSTM)结构:LSTM 是一种特殊的 RNN,专门设计用于解决长序列依赖问题。相比于普通的 RNN,LSTM 有能力更好地捕捉长距离的依赖关系,因此适用于处理长句子。
双向性:BiLSTM 通过在输入序列的两个方向上进行处理,即前向和后向,使得模型能够同时捕捉到当前位置前后的上下文信息。这样,模型就能够更全面地理解整个句子的语境,从而更准确地预测下一个单词。
上下文信息:BiLSTM 能够通过记忆单元和门控机制(如输入门、遗忘门、输出门)来记忆并使用之前的输入信息。这使得模型能够在预测下一个单词时考虑到句子中前面的所有单词,而不仅仅是最近的几个单词。
参数共享:由于 LSTM 的参数在整个序列上是共享的,模型能够利用整个序列的信息来进行预测,而不是仅仅依赖于当前时刻的输入。
端到端学习:BiLSTM 可以通过端到端的方式进行训练,这意味着模型可以直接从原始数据中学习输入和输出之间的映射关系,无需手工设计特征或规则。
总的来说,BiLSTM 结合了双向处理、长序列依赖建模和上下文信息的利用,使得它能够在给定一个长句子的情况下有效地预测下一个单词。
BiLSTM的代码相对而言比较难找,很多提供的也不准确。笔者找了几个运行成功的案例,针对案例中的BiLSTM算法部分进行分析。
案例一:给定一个长句子预测下一个单词
原文链接点击此
给定一个长句子预测下一个单词
class BiLSTM(nn.Module):
def __init__(self):
super(BiLSTM, self).__init__()
self.lstm = nn.LSTM(input_size=n_class, hidden_size=n_hidden, bidirectional=True)
# fc
self.fc = nn.Linear(n_hidden * 2, n_class)
def forward(self, X):
# X: [batch_size, max_len, n_class]
batch_size = X.shape[0]
input = X.transpose(0, 1) # input : [max_len, batch_size, n_class]
hidden_state = torch.randn(1*2, batch_size, n_hidden) # [num_layers(=1) * num_directions(=2), batch_size, n_hidden]
cell_state = torch.randn(1*2, batch_size, n_hidden) # [num_layers(=1) * num_directions(=2), batch_size, n_hidden]
outputs, (_, _) = self.lstm(input, (hidden_state, cell_state))
outputs = outputs[-1] # [batch_size, n_hidden * 2]
model = self.fc(outputs) # model : [batch_size, n_class]
return model
model = BiLSTM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
针对
def __init__(self)
:
这段代码定义了一个名为
BiLSTM
的模型类,它继承自
nn.Module
类。在
__init__
方法中,首先调用
super(BiLSTM, self).__init__()
来初始化父类
nn.Module
,然后创建了一个双向 LSTM 模型
self.lstm
。
input_size
参数指定了输入的特征维度,这里设置为
n_class
,即输入数据的特征数量。
hidden_size
参数指定了 LSTM 隐藏状态的维度,这里设置为
n_hidden
,即隐藏层的大小。
bidirectional=True
表示这是一个双向 LSTM,即包含前向和后向两个方向的信息。接着创建了一个全连接层
self.fc
,其中输入特征数量为
n_hidden * 2
,表示双向 LSTM 输出的隐藏状态的维度乘以 2,输出特征数量为
n_class
,表示分类的类别数量。
针对
def forward(self, X)
:
这段代码定义了模型的前向传播方法
forward
。在该方法中,首先接受输入
X
,其维度为
[batch_size,max_len, n_class]
,其中
batch_size
表示输入数据的批量大小,
max_len
表示序列的最大长度,
n_class
表示输入数据的特征数量。接着通过
transpose
方法将输入
X
的维度重新排列,以适应LSTM模型的输入要求,即将序列的维度放在第二维上,结果存储在
input
中。
然后,创建了LSTM模型所需的初始隐藏状态
hidden_state
和细胞状态
cell_state
。这里使用了随机初始化的状态,其维度为
[num_layers * num_directions, batch_size, n_hidden]
,其中
num_layers
表示 LSTM 的层数,默认为 1,
num_directions
表示 LSTM 的方向数,默认为 2(双向)。这里的 1*2 表示单层双向 LSTM。
接着,将输入数据
input
和初始状态传递给 LSTM 模型
self.lstm
,得到输出
outputs
。最后,取 LSTM 模型输出的最后一个时间步的隐藏状态作为模型输出,即
outputs[-1]
,其维度为
[batch_size, n_hidden * 2]
,然后通过全连接层
self.fc
进行分类,得到模型的输出
model
,其维度为
[batch_size, n_class]
,即表示每个类别的得分。
针对
model = BiLSTM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
:
这段代码实例化了一个 BiLSTM 模型,并定义了损失函数
CrossEntropyLoss
和优化器
Adam
。损失函数用于计算模型输出与目标标签之间的误差,优化器用于更新模型的参数,其中学习率
lr
设置为 0.001。
这个案例相对简单,便于理解BiLSTM的代码设计,如果想要改写为LSTM,则针对
def forward(self,X)
中的
num_directions
数值,由2->1,因为在单向 LSTM 中不需要考虑前向和后向两个方向的隐藏状态,其他部分保持不变。
class LSTM(nn.Module):
def __init__(self):
super(LSTM, self).__init__()
self.lstm = nn.LSTM(input_size=n_class, hidden_size=n_hidden)
# fc
self.fc = nn.Linear(n_hidden, n_class)
def forward(self, X):
# X: [batch_size, max_len, n_class]
batch_size = X.shape[0]
input = X.transpose(0, 1) # input : [max_len, batch_size, n_class]
hidden_state = torch.randn(1, batch_size, n_hidden) # [num_layers(=1), batch_size, n_hidden]
cell_state = torch.randn(1, batch_size, n_hidden) # [num_layers(=1), batch_size, n_hidden]
outputs, (_, _) = self.lstm(input, (hidden_state, cell_state))
outputs = outputs[-1] # [batch_size, n_hidden]
model = self.fc(outputs) # model : [batch_size, n_class]
return model
model = LSTM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
回顾一下LSTM的知识:
1. 三个门:输入门、输出门、遗忘门,通过这三个门来决定哪些信息需要被记忆,哪些需要被忘记。
2. cell state:中文翻译为细胞态。cell state变量存储的是当前时刻t及其前面所有时刻的混合信息,也就是说,在LSTM中,信息的记忆与维护都是通过cell state变量的。
3. hidden state:LSTM中的hidden_state其实就是cell state的一种过滤之后的信息,更关注当前时间点的输出结果。LSTM的hidden state其实就是当前时刻的output。
4. 输入xt:x_tx当前时间点的输入。不过,需要注意的是,在LSTM每一个时间步中,最终输入其实由xt与上一时刻隐状态ht−1组成。
热门资讯







