
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 最近,我花了一些时间用Docusaurus对博客进行了重构。根据Docusaurus的文档,我申请了Algolia,希望能够一劳永逸地解决博客的搜索问题。然而,事与愿违,Algolia一直没有给我回复,我只能对着申请页面长叹。
按照Docusaurus官方文档的说法,我们只需打开https://docsearch.algolia.com/apply/,填写申请表格并提交即可。然而,我多次填写并点击“join the program”按钮,却没有得到任何回应。
根据Docusaurus官方文档,申请Algolia搜索功能只需要在https://docsearch.algolia.com/apply/填写申请表格并提交即可。

然而,我多次填写并点击“join the program”按钮,却没有得到任何回应。
我仔细检查了官方文档,发现需要等待两个星期才能得到回复。但是在当今竞争激烈的时代,两个星期实在太长了。幸运的是,我发现还有一种手动上传的方法,虽然有些麻烦,但总比没有好。
首先,我们需要在Algolia上注册一个账号,并创建一个应用:

在应用旁边,需要创建一个用于存储搜索数据的索引:
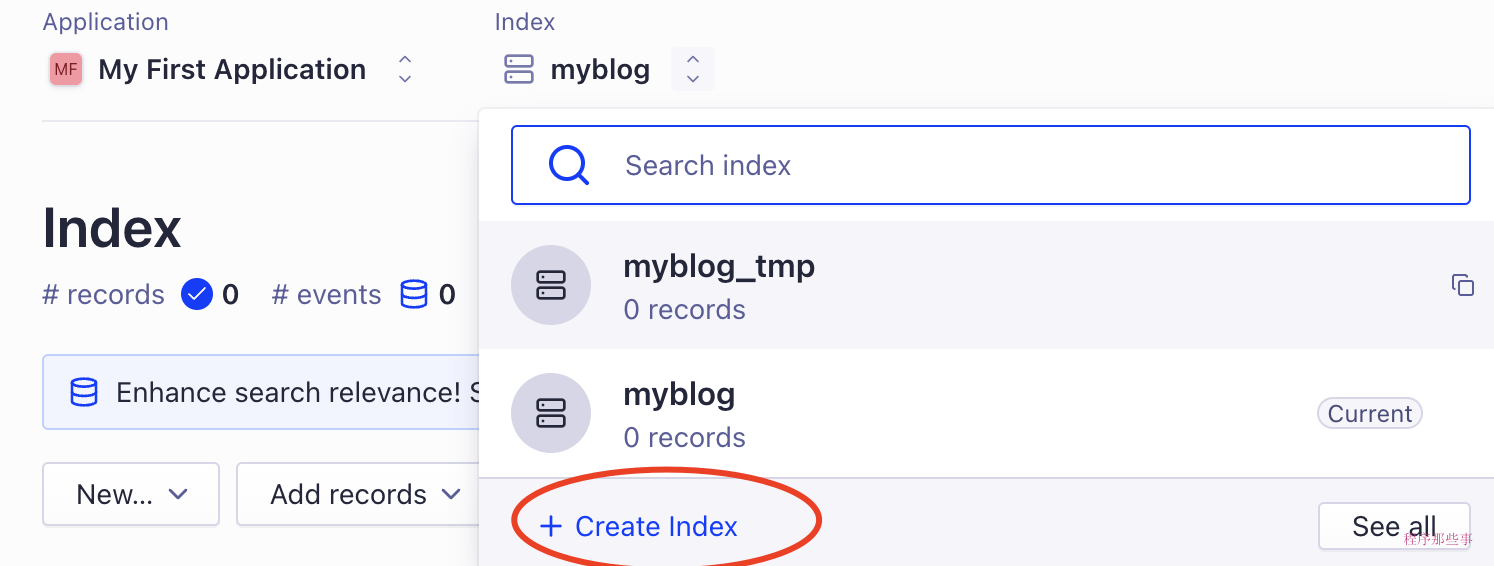
接下来,我们需要在API设置中找到APPLICATION_ID和API_KEY,并将它们保存到.env文件中:
APPLICATION_ID=YOUR_APP_ID
API_KEY=YOUR_API_KEY
需要注意的是,API_KEY最好是Admin API Key,因为它具有一些必要的权限。
如果使用Admin API Key,切记不要分享给他人,因为该密钥具有较高的权限,可以删除和更新索引数据。
接下来,我们需要一个配置文件来配置爬虫信息。以下是一个最基本的配置信息:
{
"index_name": "example",
"start_urls": ["https://www.example.com/docs"],
"selectors": {
"lvl0": "#content header h1",
"lvl1": "#content article h1",
"lvl2": "#content section h3",
"lvl3": "#content section h4",
"lvl4": "#content section h5",
"lvl5": "#content section h6",
"text": "#content header p,#content section p,#content section ol"
}
}
其中,index_name是我们刚刚在网站上创建的索引名称。当DocSearch爬虫程序运行时,你会发现一个临时的index_name_tmp索引被创建。
别担心,程序执行完毕后,这个临时索引会被替换为最终的索引。
start_urls包含要开始爬取的链接地址。爬虫会循环爬取链接中的a标签,除非遇到stop_urls。此外,爬虫不会爬取其他域名的链接。
selectors用于创建记录层次结构的所有CSS选择器。其中,text是强制必须要有的。
如果对不同的URL有不同的选择器方案,可以为不同的URL配置不同的selectors_key,如下所示:
{
"start_urls": [
{
"url": "http://www.example.com/docs/faq/",
"selectors_key": "faq"
},
{
"url": "http://www.example.com/docs/"
}
],
[…],
"selectors": {
"default": {
"lvl0": ".docs h1",
"lvl1": ".docs h2",
"lvl2": ".docs h3",
"lvl3": ".docs h4",
"lvl4": ".docs h5",
"text": ".docs p, .docs li"
},
"faq": {
"lvl0": ".faq h1",
"lvl1": ".faq h2",
"lvl2": ".faq h3",
"lvl3": ".faq h4",
"lvl4": ".faq h5",
"text": ".faq p, .faq li"
}
}
}
好了,基本的配置就这些了。
现在可以运行爬虫脚本了。这里有两个选择,一是使用docker,方便快捷。二是从源代码运行,这个就比较麻烦了。
由于我只是希望博客能够具备搜索功能,所以源码什么的就算了吧,我们直接使用docker命令:
run -it --env-file=.env -e "CONFIG=$(cat flydean.conf | jq -r tostring)" algolia/docsearch-scraper
过一会儿就可以运行起来了。但是我们来看看日志:
DocSearch: http://www.flydean.com/07-python-module/ 0 records)
DocSearch: http://www.flydean.com/08-python-io/ 0 records)
DocSearch: http://www.flydean.com/09-python-error-exception/ 0 records)
DocSearch: http://www.flydean.com/06-python-data-structure/ 0 records)Crawling issue: nbHits 0 for myblog
nb_hits表示DocSearch提取和索引的记录数。
为什么是0 records?难道什么都没有爬到?
直觉告诉我,我的start_urls可能有问题,我们尝试将其更改为sitemap.xml再试一次:
{
"sitemap_urls": ["http://www.example.com/docs/sitemap.xml"]
}
但结果依然相同。
没办法,只好再仔细阅读配置文件的说明。
终于发现了问题,原来这里的selectors写得有问题。#content header h1表示在ID为content的元素内部,寻找所有属于header类的元素,并在这些元素内部寻找所有的
我们将其改写成如下形式:
"selectors": {
"lvl0": {
"selector": ".menu__link--sublist.menu__link--active",
"global": true,
"default_value": "Documentation"
},
"lvl1": "header h1",
"lvl2": "article h2",
"lvl3": "article h3",
"lvl4": "article h4",
"lvl5": "article h5",
"lvl6": "article h6",
"text": "article p, article li"
},
再次运行一次,这次终于有数据了。
回到网站上查看,已经有数据上传上来了:
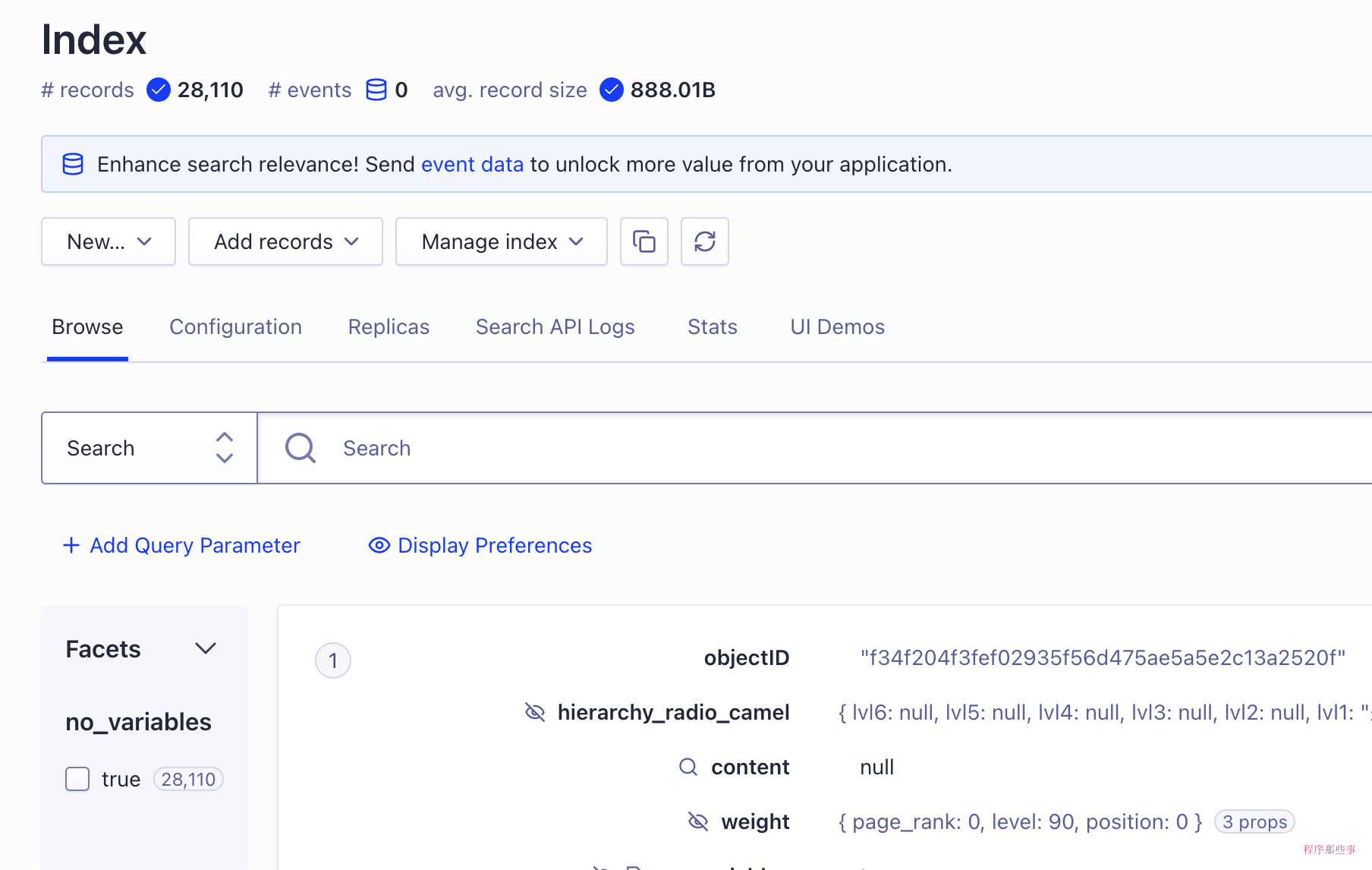
好了,我们在docusaurus.config.ts中配置一下,看看效果:
algolia: {
// The application ID provided by Algolia
appId: 'YOUR_APP_ID',
// Public API key: it is safe to commit it
apiKey: 'YOUR_SEARCH_API_KEY',
indexName: 'YOUR_INDEX_NAME',
// Optional: see doc section below
contextualSearch: true,
// Optional: Algolia search parameters
searchParameters: {},
// Optional: path for search page that enabled by default (`false` to disable it)
searchPagePath: 'search',
//... other Algolia params
},
我们在网站上试试效果:

完美,遇到问题的小伙伴可以私信我哟!
点我查看更多精彩内容:www.flydean.com
热门资讯







