
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 本来不是很想写这一篇,因为网上的文章真的烂大街了,我写的真的很有可能没别人写得好。但是想了想,创建这个博客就是想通过对外输出知识的方式来提高自身水平,而不是说我每篇都能写得有多好多好然后吸引别人来看。那作为对整个合集内容的完善,这篇博客会解析现在最火的LLaMA3的模型架构,搞清楚现在的LLM都是啥样的。
事先说明,LlaMA 3 相较于LLaMA 2 在网络架构上没有改进。用知乎网友的话说,“llama3的发布,更强调了数据工程的重要:模型架构不变,更多的数据量和更高数据质量能够带来明显模型效果提升”。但是仔细看看一个LLM的源码,对于我这种初学者,还是非常有必要的。
https://zhuanlan.zhihu.com/p/693428105
还有就是,这个博客解析的源码是 d6e09315954d1a547bf45e37269978c049e73d33 这个版本的。如果后面Meta更新的部分代码导致和这篇博客内容对不上,你可以先翻阅这个版本的源码。如果还有什么解决不了的,可以在这篇博客下面给我留言,我们共同学习共同进步。
Llama
类:起步
Llama.build
与如何看源码
我们通过llama3的ReadMe,找到了 这个demo ,demo通过
from llama import Dialog, Llama
generator = (ckpt_dir, tokenizer_path, max_seq_len, max_batch_size)
results = generator.chat_completion(dialogs, max_gen_len, temperature, top_p)
完成对话。它先调用了
Llama.build
,再对返回的对象调用了
generator.chat_completion
完成对话的功能;导入的库是
llama
。 进而关注到repo下面的
llama
文件夹,所以会先看一看文件夹下面的
__init__.py
:
from .generation import Llama
from .model import ModelArgs, Transformer
from .tokenizer import Dialog, Tokenizer
所以demo调用的
Llama.build
在
.generation
里面。顺藤摸瓜找到:
class Llama:
@staticmethod
def build(
ckpt_dir: str,
tokenizer_path: str,
max_seq_len: int,
max_batch_size: int,
model_parallel_size: Optional[int] = None,
seed: int = 1,
) -> "Llama":
"""
Build a Llama instance by initializing and loading a model checkpoint.
Args:
ckpt_dir (str): 模型检查点文件的路径
tokenizer_path (str): 模型tokenizer文件路径.
max_seq_len (int): Maximum sequence length for input text.
max_batch_size (int): Maximum batch size for inference.
model_parallel_size (Optional[int], optional): Number of model parallel processes.
If not provided, it's determined from the environment. Defaults to None.
Returns:
Llama: An instance of the Llama class with the loaded model and tokenizer.
"""
# 这里首先是一些模型并行设置
if not torch.distributed.is_initialized():
torch.distributed.init_process_group("nccl")
if not model_parallel_is_initialized():
if model_parallel_size is None:
model_parallel_size = int(os.environ.get("WORLD_SIZE", 1))
initialize_model_parallel(model_parallel_size)
# 多机训练/推理一个模型的话,每个机器都会有个rank。这里就是配置这个rank的。
local_rank = int(os.environ.get("LOCAL_RANK", 0))
torch.cuda.set_device(local_rank)
# 随机种子
torch.manual_seed(seed)
# 设置输出只在一台设备上进行
if local_rank > 0:
sys.stdout = open(os.devnull, "w")
# 终于到加载模型相关的代码了
start_time = time.time()
checkpoints = sorted(Path(ckpt_dir).glob("*.pth"))
# 检查模型检查点文件的数量是否合乎要求
assert len(checkpoints) > 0, f"no checkpoint files found in {ckpt_dir}"
assert model_parallel_size == len(
checkpoints
), f"Loading a checkpoint for MP={len(checkpoints)} but world size is {model_parallel_size}"
# 加载模型。多机运行时`get_model_parallel_rank()`返回的结果不一样,所以不需要写for循环。这里的思想有cuda编程那味了
ckpt_path = checkpoints[get_model_parallel_rank()]
checkpoint = torch.load(ckpt_path, map_location="cpu")
# TODO: 读取`params.json`并通过类`ModelArgs`加载进变量`model_args`。这个类我们待会讲
with open(Path(ckpt_dir) / "params.json", "r") as f:
params = json.loads(f.read())
model_args: ModelArgs = ModelArgs(
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
**params,
)
# TODO: 加载Tokenizer。Tokenizer我们待会讲
tokenizer = Tokenizer(model_path=tokenizer_path)
assert model_args.vocab_size == tokenizer.n_words
# 半精度相关
if torch.cuda.is_bf16_supported():
torch.set_default_tensor_type(torch.cuda.BFloat16Tensor)
else:
torch.set_default_tensor_type(torch.cuda.HalfTensor)
# TODO: 是的,llama3的模型主体就是这里的Transformer类。直接model.load_state_dict就能加载好权重。这个也待会讲
model = Transformer(model_args)
model.load_state_dict(checkpoint, strict=False)
print(f"Loaded in {time.time() - start_time:.2f} seconds")
# TODO: 到这里其实啥都加载完了,这里返回了个Llama类。
return Llama(model, tokenizer)
这段代码看下来逻辑很清晰,就是给我们留下了几个TODO,这些我们都会讲到。
ModelArgs
类
我们首先看到
ModelArgs
类,这个类只用于保存一些参数,
@dataclass
装饰器就已经说明了一切:
@dataclass
class ModelArgs:
dim: int = 4096 # 模型维度
n_layers: int = 32 # 层数
n_heads: int = 32 # 头数
n_kv_heads: Optional[int] = None
vocab_size: int = -1 # 词汇表大小
multiple_of: int = 256 # make SwiGLU hidden layer size multiple of large power of 2
ffn_dim_multiplier: Optional[float] = None
norm_eps: float = 1e-5
rope_theta: float = 500000
max_batch_size: int = 32
max_seq_len: int = 2048 # 序列长度
llama.__init__()
最后这一句
return Llama(model, tokenizer)
,它实际上会调用
Llama.__init__()
,代码如下:
from llama.tokenizer import ChatFormat, Dialog, Message, Tokenizer
def __init__(self, model: Transformer, tokenizer: Tokenizer):
self.model = model
self.tokenizer = tokenizer
# TODO: ChatFormat类解析
self.formatter = ChatFormat(tokenizer)
是的,简单赋值就结束了。
formatter
这里用到的
ChatFormat
类我们一会随tokenizer一起解析。
Transformer
类:Llama3模型架构详解
这一部分应该是被人关心得最多的部分了。
Transformer.__init__()
首先看模型初始化,这里就是设置了一堆类的属性。我们直接上代码,解析见代码注释:
from fairscale.nn.model_parallel.layers import (
ColumnParallelLinear,
RowParallelLinear,
VocabParallelEmbedding,
) # FairScale库的模块都是用于实现模型并行化的,不需要深究
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
# VocabParallelEmbedding类导入自fairscale,功能同`torch.nn.embedding`
self.tok_embeddings = VocabParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
# TODO: TransformerBlock
self.layers.append(TransformerBlock(layer_id, params))
# TODO: RMSNorm
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
# ColumnParallelLinear 相当于 `torch.nn.linear`
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
# TODO: precompute_freqs_cis
self.freqs_cis = precompute_freqs_cis(
params.dim // params.n_heads,
params.max_seq_len * 2,
params.rope_theta,
)
RMSNorm是均值为0的LayerNorm:
注:layerNorm为
用代码实现出来是这个样子的:
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim)) # 初始化为1的可学习参数
def _norm(self, x):
# torch.rsqrt: 平方根的倒数,这里用于计算标准差的倒数
# x.pow(2).mean(-1, keepdim=True): 沿着倒数第一维计算平方并求平均
# a_i * 元素平方的均值取平方根后再取倒数 + 无穷小量
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight
作者认为这种模式在简化了Layer Norm的同时,可以在各个模型上减少约 7%∼64% 的计算时间
该部分内容参考了 苏剑成的博客 。苏剑成是RoPE的发明者。
旋转位置编码通过绝对位置编码的方式实现相对位置编码。假设通过下述运算来给 \(q,k\) 添加绝对位置信息:
分别为 \(q,k\) 设计操作 \(\boldsymbol{f}(\cdot, m),\boldsymbol{f}(\cdot, n)\) ,使得经过该操作后, \(\tilde{\boldsymbol{q}}_m,\tilde{\boldsymbol{k}}_n\) 就带有了位置 \(m,n\) 的绝对位置信息。Attention的核心运算是内积,所以我们希望的内积的结果带有相对位置信息,因此假设存在恒等关系:
解得:
可以写成:
由于内积满足线性叠加性,因此任意偶数维的RoPE,我们都可以表示为二维情形的拼接,即:
我们便可以通过以下方式实现RoPE:
precompute_freqs_cis
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
# 计算词向量元素两两分组以后,每组元素对应的旋转角度
# torch.arange(0, dim, 2): 生成 [0,2,4...126]
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device, dtype=torch.float32) # t = [0,....end]
# torch.outer: torch.outer(a, b) = a^T * b
freqs = torch.outer(t, freqs) # freqs.shape = (t.len(),freqs.len()) #shape (end,dim//2)
# 根据角坐标生成复数向量
# torch.polar(abs,angle): abs*cos(angle) + abs*sin(angle)*j
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # freqs_cis.shape = (end,dim//2)
return freqs_cis
reshape_for_broadcast
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
# ndim为x的维度数, 此时应该为4
ndim = x.ndim
assert 0 <= 1 < ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
# (1, x.shape[1], 1, x.shape[-1])
return freqs_cis.view(*shape)
apply_rotary_emb
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""将xq和xk的最后一个维度进行复数运算,得到新的xq和xk"""
# xq.shape = [bsz, seqlen, self.n_local_heads, self.head_dim]
# xq_.shape = [bsz, seqlen, self.n_local_heads, self.head_dim//2 , 2]
# torch.view_as_complex用于将二维向量转换为复数域 torch.view_as_complex即([x,y]) -> (x+yj)
# 所以经过view_as_complex变换后xq_.shape = [bsz, seqlen, self.n_local_heads, self.head_dim//2]
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_) # freqs_cis.shape = (1,x.shape[1],1,x.shape[-1])
# xq_ 与freqs_cis广播哈达玛积
# [bsz, seqlen, self.n_local_heads, self.head_dim//2] * [1,seqlen,1,self.head_dim//2]
# torch.view_as_real用于将复数再转换回实数向量, 再经过flatten展平第4个维度
# [bsz, seqlen, self.n_local_heads, self.head_dim//2] ->[bsz, seqlen, self.n_local_heads, self.head_dim//2,2 ] ->[bsz, seqlen, self.n_local_heads, self.head_dim]
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
TransformerBlock
类
这个类比较简单,只是一个transformer block。
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
"""初始化函数主要就是定义了transformer block的各个组件,包括自注意力机制和前馈神经网络。"""
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
# TODO: Attention
self.attention = Attention(args)
# TODO: FeedForward
self.feed_forward = FeedForward(
dim=args.dim, hidden_dim=4 * args.dim, multiple_of=args.multiple_of, ffn_dim_multiplier=args.ffn_dim_multiplier,
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
"""这个函数是transformer block的前向传播函数,输入是x,start_pos,freqs_cis,mask,输出是out"""
# 这个函数的实现比较简单,首先对输入张量x进行自注意力机制计算,然后对计算结果进行残差连接和归一化,再通过前馈神经网络计算,最后再次进行残差连接和归一化。
h = x + self.attention(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward(self.ffn_norm(h))
return out
Attention
类
为了实现Group Query Attention,这里用到了一个函数
repeat_kv
,它的作用是将key和value的head维度重复n_rep次,以匹配query的head数。
repeat_kv
函数使用
expand
方法将输入张量在第四个维度上扩展 n_rep 次,并使用
reshape
方法将其调整为适当的形状
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
x[:, :, :, None, :]
.expand(bs, slen, n_kv_heads, n_rep, head_dim)
.reshape(bs, slen, n_kv_heads * n_rep, head_dim)
)
# 精简版Attention
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.wq = Linear(...)
self.wk = Linear(...)
self.wv = Linear(...)
self.freqs_cis = precompute_freqs_cis(dim, max_seq_len * 2)
def forward(self, x: torch.Tensor):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
# attention 操作之前,应用旋转位置编码
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
#...
# 进行后续Attention计算
scores = torch.matmul(xq, xk.transpose(1, 2)) / math.sqrt(dim)
scores = F.softmax(scores.float(), dim=-1)
output = torch.matmul(scores, xv) # (batch_size, seq_len, dim)
FeedForward
类与SwiGLU激活函数
FeedForward
类实现的是:
使用的激活函数是SwiGLU,这里有:
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
ffn_dim_multiplier: Optional[float],
): # 我们不妨跳过这个函数,太无聊了
...
def forward(self, x):
# w2 * silu(w1 * x) * w3
return self.w2(F.silu(self.w1(x)) * self.w3(x))
以下内容参考 知乎
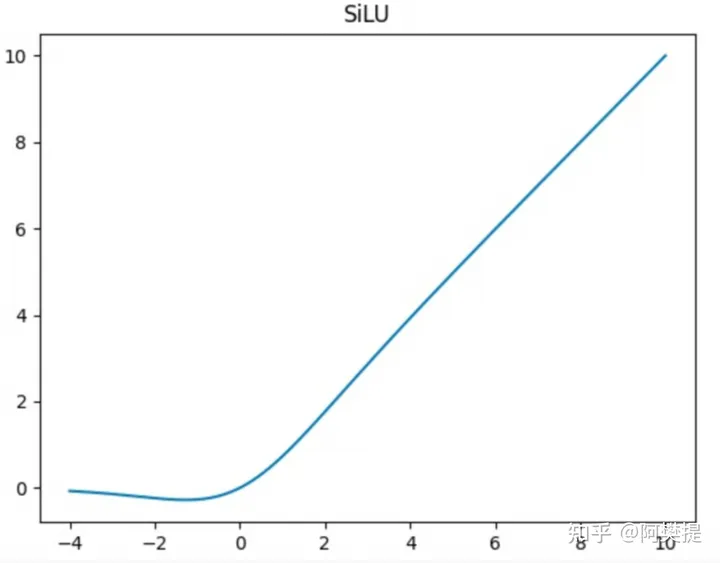
\(\beta = 1\) 时 \(swish(x)\) 就是$silu(x) $
函数图像如下:
Transformer.forward()
前向传播就是我们熟悉的 Transformer 前向传播了。
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape # 批大小和序列长度
h = self.tok_embeddings(tokens) # 词嵌入层进行嵌入,得到表示输入序列的张量h
self.freqs_cis = self.freqs_cis.to(h.device) # 将频率转换为与输入张量相同的设备
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen] # 从预计算的频率张量中提取频率
mask = None # 用于在自注意力机制中屏蔽不必要的位置的mask
if seqlen > 1:
mask = torch.full((seqlen, seqlen), float("-inf"), device=tokens.device) # 创建一个形状为(seqlen, seqlen)的张量,填充为负无穷
mask = torch.triu(mask, diagonal=1) # 上三角矩阵
mask = torch.hstack(
[torch.zeros((seqlen, start_pos), device=tokens.device), mask]
).type_as(h) # 将mask张量与全零张量水平拼接,以适应输入张量h的维度
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask) # 逐层进行transformer计算
h = self.norm(h) # 对输出张量进行归一化
output = self.output(h).float() # 输出层进行线性变换
return output
Tokenizer
类
Tokenizer
类主要调用
tiktoken
库,没啥好讲的。这里的函数大多是前面定义了一大堆东西,但是翻阅具体业务的时候发现其实还是在调库。
class Tokenizer:
"""
Tokenizing and encoding/decoding text using the Tiktoken tokenizer.
"""
special_tokens: Dict[str, int]
num_reserved_special_tokens = 256
pat_str = r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+" # noqa: E501
def __init__(self, model_path: str):
"""
Initializes the Tokenizer with a Tiktoken model.
Args:
model_path (str): The path to the Tiktoken model file.
"""
assert os.path.isfile(model_path), model_path
mergeable_ranks = load_tiktoken_bpe(model_path)
num_base_tokens = len(mergeable_ranks)
special_tokens = [
"<|begin_of_text|>", "<|end_of_text|>",
"<|start_header_id|>", "<|end_header_id|>", "<|eot_id|>", # end of turn
"<|reserved_special_token_0|>", "<|reserved_special_token_1|>",
"<|reserved_special_token_2|>", "<|reserved_special_token_3|>", "<|reserved_special_token_4|>",
] + [
f"<|reserved_special_token_{i}|>"
for i in range(5, self.num_reserved_special_tokens - 5)
]
self.special_tokens = {
token: num_base_tokens + i for i, token in enumerate(special_tokens)
}
self.model = tiktoken.Encoding(
name=Path(model_path).name, pat_str=self.pat_str,
mergeable_ranks=mergeable_ranks, special_tokens=self.special_tokens,
)
self.n_words: int = self.model.n_vocab
# BOS / EOS token IDs
self.bos_id: int = self.special_tokens["<|begin_of_text|>"]
self.eos_id: int = self.special_tokens["<|end_of_text|>"]
self.pad_id: int = -1
self.stop_tokens = {
self.special_tokens["<|end_of_text|>"],
self.special_tokens["<|eot_id|>"],
}
def encode(
self, s: str, *, bos: bool, eos: bool,
allowed_special: Union[Literal["all"], AbstractSet[str]] = set(),
disallowed_special: Union[Literal["all"], Collection[str]] = (),
) -> List[int]:
"""
Encodes a string into a list of token IDs.
Args:
s (str): The input string to be encoded.
bos (bool): Whether to prepend the beginning-of-sequence token.
eos (bool): Whether to append the end-of-sequence token.
allowed_tokens ("all"|set[str]): allowed special tokens in string
disallowed_tokens ("all"|set[str]): special tokens that raise an error when in string
Returns:
list[int]: A list of token IDs.
By default, setting disallowed_special=() encodes a string by ignoring
special tokens. Specifically:
- Setting `disallowed_special` to () will cause all text corresponding
to special tokens to be encoded as natural text (insteading of raising
an error).
- Setting `allowed_special` to "all" will treat all text corresponding
to special tokens to be encoded as special tokens.
"""
assert type(s) is str
# The tiktoken tokenizer can handle <=400k chars without pyo3_runtime.PanicException.
TIKTOKEN_MAX_ENCODE_CHARS = 400_000
# Here we iterate over subsequences and split if we exceed the limit of max consecutive non-whitespace or whitespace characters.
MAX_NO_WHITESPACES_CHARS = 25_000
substrs = (
substr
for i in range(0, len(s), TIKTOKEN_MAX_ENCODE_CHARS)
for substr in self._split_whitespaces_or_nonwhitespaces(
s[i : i + TIKTOKEN_MAX_ENCODE_CHARS], MAX_NO_WHITESPACES_CHARS
)
)
t: List[int] = []
for substr in substrs:
t.extend(
# 调用在这里
self.model.encode(
substr,
allowed_special=allowed_special,
disallowed_special=disallowed_special,
)
)
if bos:
t.insert(0, self.bos_id)
if eos:
t.append(self.eos_id)
return t
def decode(self, t: Sequence[int]) -> str:
"""
Decodes a list of token IDs into a string.
Args:
t (List[int]): The list of token IDs to be decoded.
Returns:
str: The decoded string.
"""
# Typecast is safe here. Tiktoken doesn't do anything list-related with the sequence.
return self.model.decode(cast(List[int], t))
@staticmethod
def _split_whitespaces_or_nonwhitespaces(
s: str, max_consecutive_slice_len: int
) -> Iterator[str]:
"""
Splits the string `s` so that each substring contains no more than `max_consecutive_slice_len`
consecutive whitespaces or consecutive non-whitespaces.
"""
current_slice_len = 0
current_slice_is_space = s[0].isspace() if len(s) > 0 else False
slice_start = 0
for i in range(len(s)):
is_now_space = s[i].isspace()
if current_slice_is_space ^ is_now_space:
current_slice_len = 1
current_slice_is_space = is_now_space
else:
current_slice_len += 1
if current_slice_len > max_consecutive_slice_len:
yield s[slice_start:i]
slice_start = i
current_slice_len = 1
yield s[slice_start:]
ChatFormat
类
ChatFormat
类借助
Tokenizer
类,对
Tokenizer
进行了进一步包装,提供了
encode_header
、
encode_message
、
encode_dialog_prompt
三种encode方式。
class ChatFormat:
def __init__(self, tokenizer: Tokenizer):
self.tokenizer = tokenizer
def encode_header(self, message: Message) -> List[int]:
tokens = []
tokens.append(self.tokenizer.special_tokens["<|start_header_id|>"])
tokens.extend(self.tokenizer.encode(message["role"], bos=False, eos=False))
tokens.append(self.tokenizer.special_tokens["<|end_header_id|>"])
tokens.extend(self.tokenizer.encode("\n\n", bos=False, eos=False))
return tokens
def encode_message(self, message: Message) -> List[int]:
tokens = self.encode_header(message)
tokens.extend(
self.tokenizer.encode(message["content"].strip(), bos=False, eos=False)
)
tokens.append(self.tokenizer.special_tokens["<|eot_id|>"])
return tokens
def encode_dialog_prompt(self, dialog: Dialog) -> List[int]:
tokens = []
tokens.append(self.tokenizer.special_tokens["<|begin_of_text|>"])
for message in dialog:
tokens.extend(self.encode_message(message))
# Add the start of an assistant message for the model to complete.
tokens.extend(self.encode_header({"role": "assistant", "content": ""}))
return tokens
以上就是全部的源码解读。如有疑问请留言。
热门资讯







