
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版
#define宏定义是个演技非常高超的替身演员,但也会经常耍大牌的,所以我们用它要慎之又慎。它可以出现在代码的任何地方,从本行宏定义开始,以后的代码就都认识这个宏了;也可以把任何东西定义成宏。因为编译器会在预编译的时候用真身替换替身,而在我们的代码里面却又用常常用替身来帮忙。看例子:
#define PI 3.141592654在此后的代码中尽可以使用 PI 来代替 3.141592654,而且你最好就这么做。不然的话,如果我要把PI的精度再提高一些,你是否愿意一个一个的去修改这串数呢?你能保证不漏不出错?而使用 PI 的话,我们却只需要修改一次。这种情况还不是最要命的,我们再看一个例子:
#define ERROR_POWEROFF -1如果你在代码里不用 ERROR_POWEROFF 这个宏而将-1硬编码进代码里,尤其在函数返回错误代码的时候(往往一个开发一个系统需要定义很多错误代码)。肯怕上帝都无法知道-1 表示的是什么意思吧。这个-1,我们一般称为“魔鬼数”,上帝遇到它也会发狂的。所以,我奉劝代码里一定不要出现“魔鬼数”。
关键字篇我们讨论了 const 这个关键字,我们知道const 修饰的数据是有类型的,而 define 宏定义的数据没有类型。为了安全,我建议以后在定义一些宏常数的时候用 const 代替,编译器会给 const 修饰的只读变量做类型校验,减少错误的可能。但一定要注意const修饰的不是常量而是readonly的变量,const 修饰的只读变量不能用来作为定义数组的维数,也不能放在 case 关键字后面。
举例:
#define ENG_PATH_4 "E:\\English\\listen_to_this\\listen_to_this_3"
能否使用宏定义的注释来注释代码?
#define COMMENT //
int main()
{
COMMENT puts("hello");
}
第一眼看这个代码可能会搞不清程序是否执行打印,这个问题的解决我们需要知道预处理过程各步骤的执行顺序,
先看看程序预处理过程做了什么.
预处理: 预处理指令,头文件展开,去掉注释,宏替换,条件编译 (顺序是怎样的?)
编译: C语言翻译成汇编语言
汇编: 将汇编代码转化成可重定向目标文件(可被链接)
链接: 自身程序+库文件进行关联,形成可执行程序
生成的预处理结果如图:
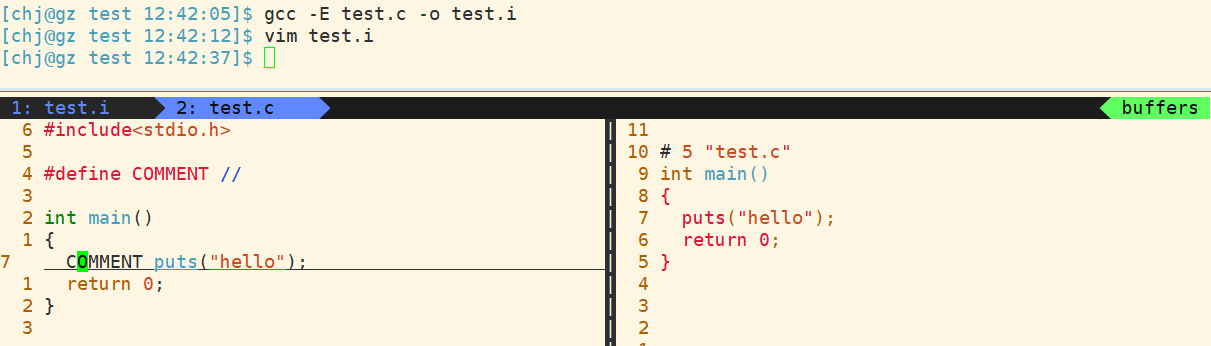
观察结果,如果宏替换先于去注释,则puts代码一定是被去掉的,显然puts还在,说明 先去注释,再宏替换 ;
既然是先去注释再宏替换,那为什么预处理后却没有发现puts前面带双斜杠呢? 这就很尴尬了,其实在
#define COMMENT //
处的双斜杠在
编译前就被识别成注释
了,去掉注释后代码就变成了
#define COMMET
这样子,是一个仅仅用于标识的宏.
预处理指令和宏谁先处理是不可预期的.
总之,通过这点我们知道了预处理过程去注释是先于宏替换的.
上面说的是C++风格的注释,那C风格的注释呢
#define BSC //
#define BMC /*
#define EMC */
BSC: Begin Single-line Comment
BMC: Begin Multi-line Comment
EMC: End Multi-line Comment

这就很明显了,如果有语法提示则很容易看出来,和上面所说的C++风格注释的情况是一样的原理.
我们知道,一般的宏函数是很容易出现问题的,比如说少加了括号,因为结合性问题导致代码逻辑没有按照预期来执行...,那怎样写出一个健壮性很高的宏函数呢? 先看一个例子:

如果我定义这样一个宏函数,并且按照一般函数的方式运用,显然不是能通过语法检查的.看一下预处理后的代码
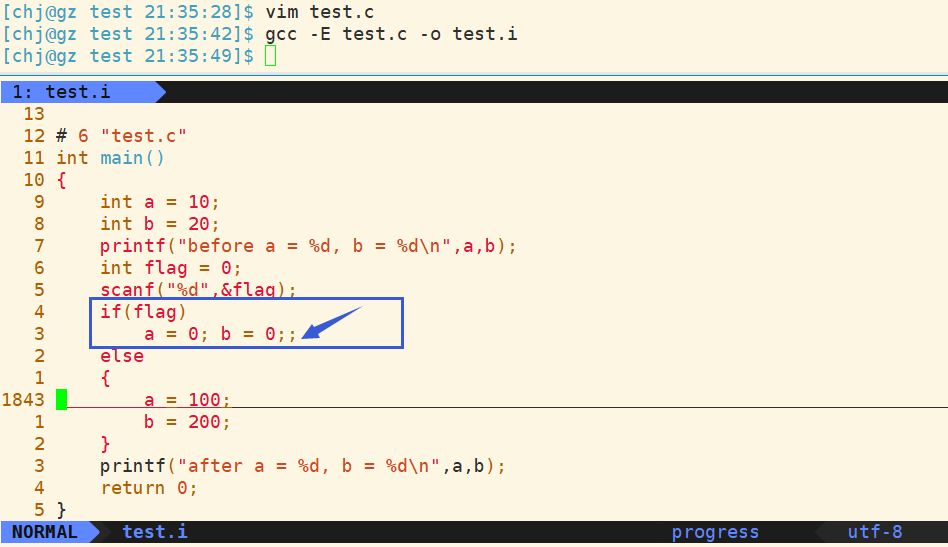
可以发现
a = 0;
已经算一条语句了,后面
b = 0;;
多出来,不符合语法,因此报错.
if在不带花括号的条件下只能且必须带一条语句.如果想用这条宏函数,只能将它写进if的花括号中.但是,这样的代码是不友好的,它变相的强迫用户必须带上花括号,显然不是一种很好的方式.
既然要求if分支有多条语句需要执行时必须加上花括号,那能不能直接在宏函数中加上花括号? 看一下效果
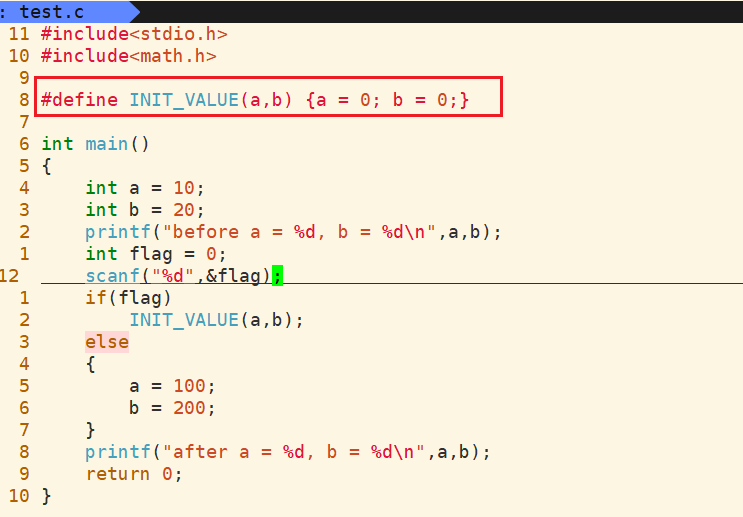
再看一下预处理后的代码
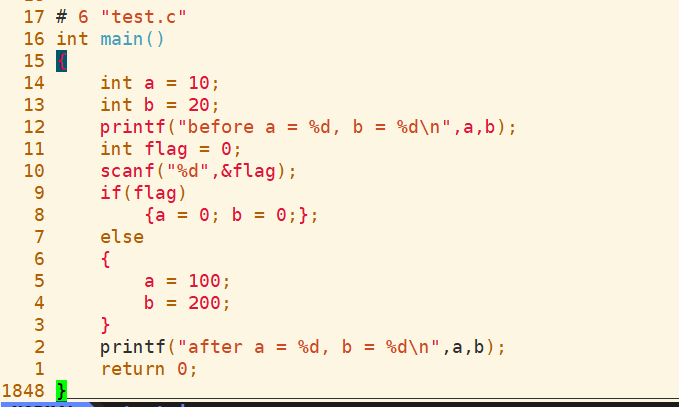
可以发现if花括号后面还带上了分号,这显然也不够好.
上面各种方式都是有大大小小的缺陷. 那还有没有更好的方案? 有的,最终解决方案:使用 do-while-zero结构

看预处理后的代码:
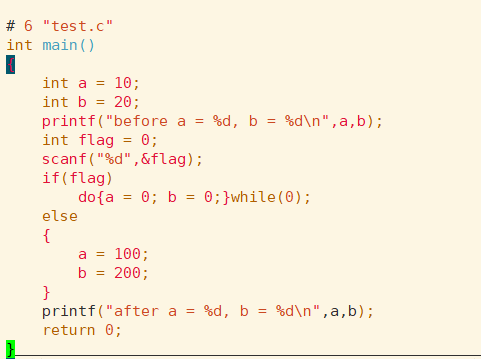
可以发现,在do-while-zero结构中,do后面有花括号,可以封装任意多条语句.while(0)后可以接上分号,并且while(0)是条件判定为假,结束执行循环,整体上只执行一次且必须执行一次.用法上和普通函数有类似的效果,因此具有普适性.
do-while-zero结构是一个编码技巧,作为一个宏函数技巧,我们可以了解一下,虽然不一定会使用它.在早些年的项目中也有很多使用的,掌握它后至少我们在看源码时可以在遇到这样子的宏函数时可以知道写的是什么...
#include
#define INC(a) ((a)++) //定义宏函数不能带空格
int main()
{
int i = 0;
INC (i); //使用可以带空格,但是严重不推荐
printf("%d\n", i);
}
先说结论: 宏可以在源文件的任何地方定义 .
验证,在main函数中定义:
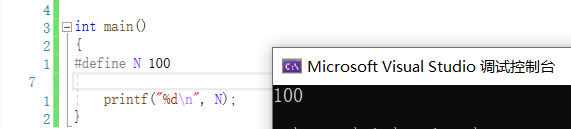
在普通函数中定义:
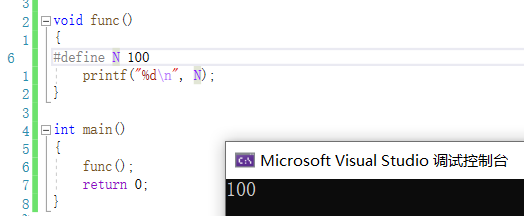
在普通函数中定义,在main函数中使用:
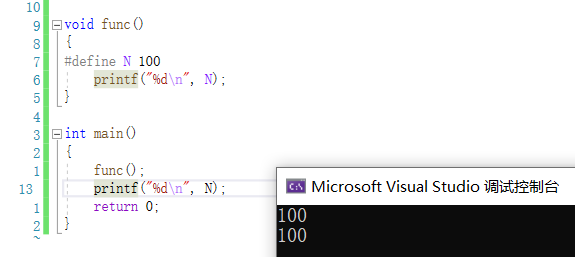
说明:宏定义与是否在函数体外内没有任何关系
结论:源文件的任何地方,宏都可以定义,与是否在函数内外无关 .
注意:宏只在从它定义的位置开始生效.从定义开始,往后都是有效的.
不正确例子:

#undef
#undef的作用是取消宏,限定宏的范围.

看下面一段代码:

#undef
在函数调用的上边,这样的代码看着会有些绕.看一下运行结果:
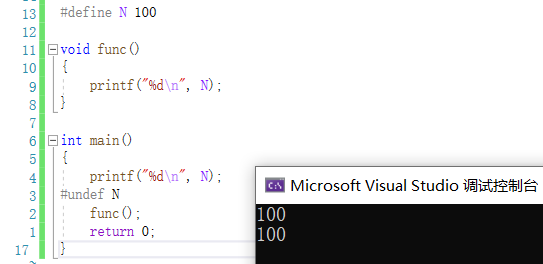
这是可以通过的,因为宏替换是在函数调用之前进行.这样的代码需要熟悉预编译指令的执行顺序才容易阅读.
C语言中,尽管在代码文件中的任何位置放置#define或者#undef是合法的,但把它们放在块中会使人误解为它们只存在于块作用域,给人一种只在函数内有效的错觉.
也不排除我们只想让它在局部范围内有效,因此使用时需要慎重考虑.
条件编译主要是用于代码裁剪,通过代码裁剪,能够快速实现某种目的,如版本维护(free版本,pro版本等,功能裁剪,跨平台性等.
举个例子
我们经常听说过,某某版程序是完全版/精简版,某某版应用是商用版/校园版,某某软件是基础版/扩展版等。
其实这些软件在公司内部都是同一个项目,是多个源文件构成的。所以,所谓的不同版本,其实就是那些功能的有无;在技术层面上,公司为了好维护,可以维护多种版本;如果是使用条件编译,想使用哪个版本,就使用哪种条件进行裁剪就行。
如著名的Linux内核,功能上也是使用条件编译进行功能裁剪的,来满足不同平台的软件。
int main()
{
#ifndef DEBUG
printf("hello debug\n");
#elif RELEASE
printf("hello release\n");
#else
printf("hello unknow\n");
#endif
return 0;
}
#define DEBUG // 宏被定义
#define DEBUG 1 // 宏被定义,且值为真
#define DEBUG 0 // 宏被定义,且值为假
宏为真假是在宏被定义之上的.
语法:gcc 源文件 -D 宏=值
# gcc test.c -D MACRO=1
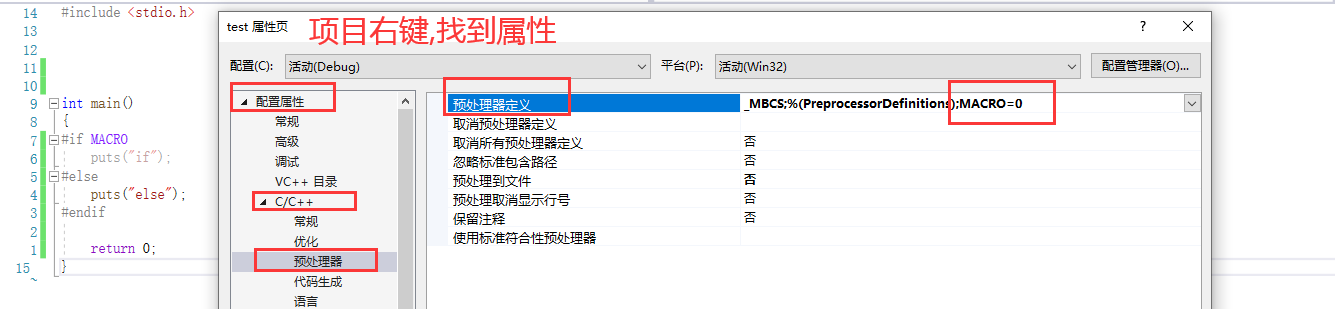
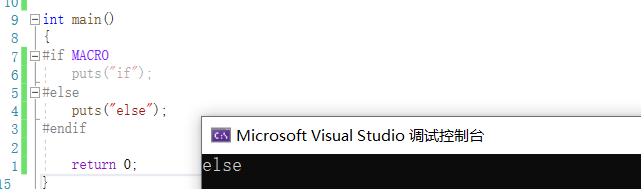
在vs平台上用的不多.
#ifdef/#ifndef
#ifdef/#ifndef
用于检测宏是否被定义,有没有值,是真是假不重要
#ifdef
检测宏是否已经定义,是则保留,否则裁剪;#ifndef则相反
用法举例:
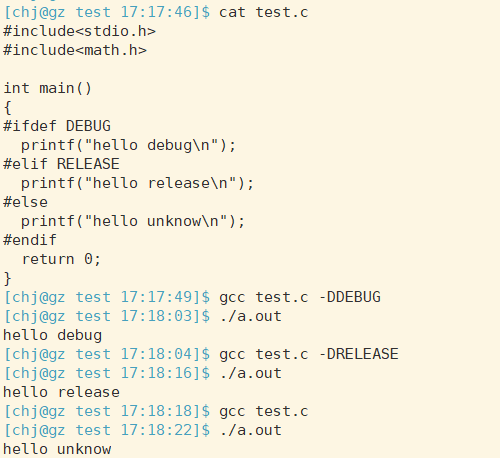
#ifdef/#ifndef
一般只在头文件中使用
#if
#if
的默认用法和#ifdef有一定区别,其他用法差不多,#if使用更频繁.
区别是#if如果定义了宏则要求必须要有值,没定义则当作假或者else.
使用#if或#ifdef时,很容易会忘记写#endif.因为我们平常写if-else没有这个end,很容易会类比忘记掉#endif.所以在使用条件编译时,先把#if - #endif写上,后面就不再容易遗漏了.
#if
模拟#ifdef:
#define MACRO
int main()
{
#if defined(MACRO)
puts("MACRO defined!");
#else
puts("MACRO undefined!");
#endif
return 0;
}
程序运行结果:
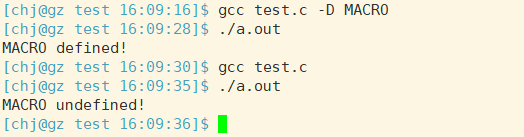
如果是未定义呢? 没有别的名词,加个逻辑反就好啦
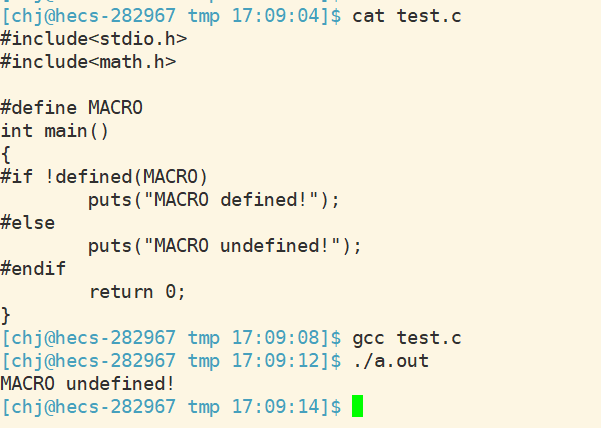
#include
#include
#define C
#define CPP
int main()
{
#if defined(C)
#if defined(CPP)
puts("hello CPP");
#endif
puts("hello C");
#else
puts("hello other");
#endif
return 0;
}

注释掉
#define C
后

可以证明,条件编译是支持嵌套的.
不过,使用嵌套的代码阅读体验是比较差的,一般不建议使用嵌套,下面还有其他更好的代码写法推荐.
[引用]( C语言#if defined高级用法-CSDN博客 )
在一个需要完成“多个宏定义来共同控制同一代码分支”的情况下,例如
#ifndef TEST_1
#define TEST_1
#endif
#ifdef TEST_1
puts("1");
#else
#ifdef TEST_2
puts("1");
#else
puts("2");
#endif
#endif
#ifndef TEST_1
puts("1");
#else
#ifndef TEST_2
puts("1");
#else
puts("2");
#endif
#endif
这样的代码看起来是比较冗余的,不好阅读,因为#ifdef是没有对应的"else if",我们只能采用这样的方式写.对比到一般使用的if-else, if()内可以是一个表达式 ,那#ifdef能否也能将宏定义组织成表达式呢?
看一下代码
#ifdef TEST_1 || TEST_2
puts("1");
#else
puts("2");
#endif
这样的代码看起来是更简洁,更优雅.但它是错误的.
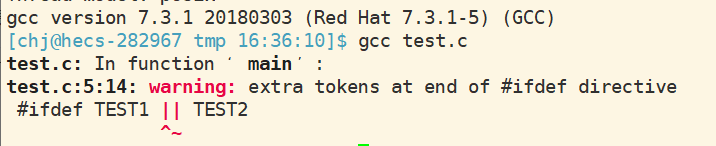
因为ifdef和ifndef仅能跟一个宏定义参数,而不能使用表达式 。
虽然在vs下可以运行
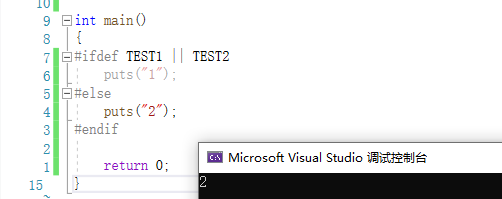
但是我们不推荐这样不能跨平台的代码.
因为#if需要判断真假而具有计算表达式的功能,
因此,使用
#if defined
和
#if !defined
是
更好的选择
.
#if defined TEST_1 || defined TEST_2
puts("1");
#else
puts("2");
#endif
#if !defined TEST_1 || !defined TEST_2
puts("1");
#else
puts("2");
#endif
ANSI标准的5个预定义宏
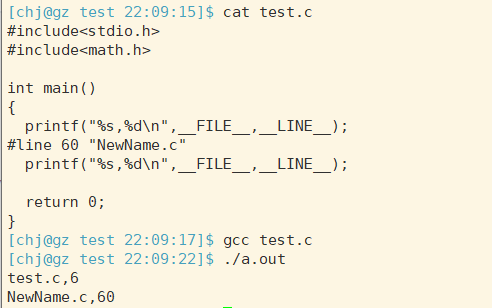
__FILE__
:当前文件名
__LINE__
:所在行号
__STDC__
:当编译器遵循ANSI C标准时该宏被定义为1。
__TIME__
:表示当前源代码被编译的时间字符串。
__DATE__
:表示当前源代码被编译的日期字符串。
可以定制化你的文件名称和代码行号,很少使用
#error命令是C/C++语言的预处理命令之一,当预处理器预处理到#error命令时将停止编译并输出用户自定义的错误消息。
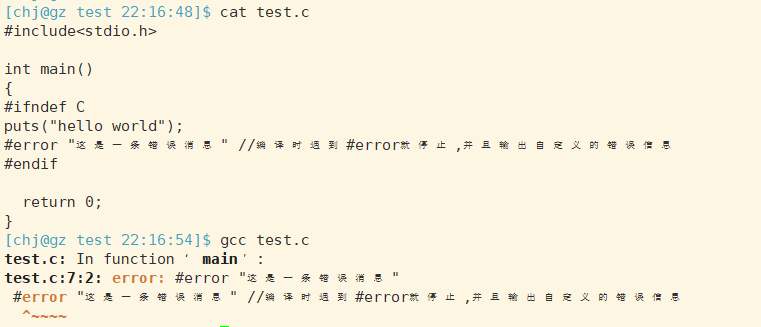
用于人为阻止编译,在某些情况下得知编译条件不满足时,可以使用#error让编译停止.
#pragma
#pragma
指令很复杂,需要使用的时候再查一下
#pragma_百度百科 (baidu.com)
.
Message 参数能够在编译信息输出窗口中输出相应的信息,这对于源代码信息的控制是非常重要的。其使用方法为:
#pragma message("消息文本")
当编译器遇到这条指令时就在编译输出窗口中将消息文本打印出来。
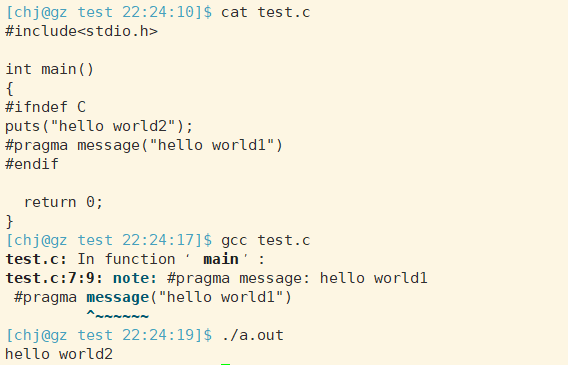
也可以用于在编译器检测某个宏是否被定义:
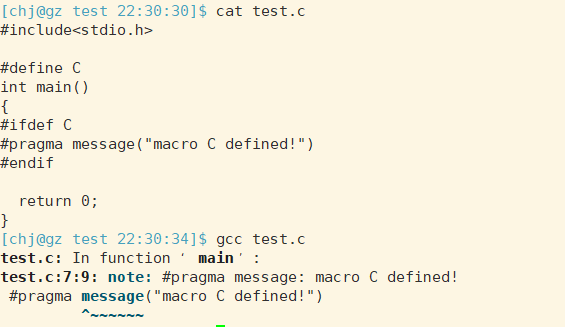
#pragma warning(disable:4996;once:4385;error:164)
等价于:
1#pragma warning(disable:4996)//不显示4996警告信息
2#pragma warning(once:4385)//4385号警告信息仅报告一次
3#pragma warning(error:164)//把164号警告信息作为一个错误。
还有很多用法..,可以查下文档
#pragma_百度百科 (baidu.com)
C语言两个相邻的字符串能够自动拼接成一个字符串.
int main()
{
puts("hello"" world");
const char *str = "hello"" world\n";
printf(str);
return 0;
}
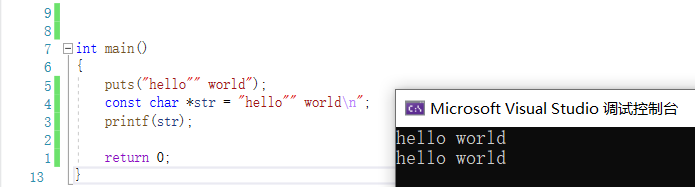
常搭配字符串连接特性一起使用
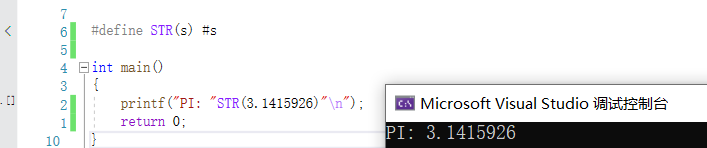
#define STR(s) #s
int main()
{
printf("PI: "STR(3.1415926)"\n");
return 0;
}
#define SQR(x) printf("The square of x is %d.\n", ((x)*(x)));
int main()
{
SQR(8);
return 0;
}
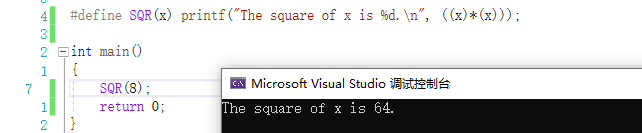
注意到没有,引号中的字符 x 被当作普通文本来处理,而不是被当作一个可以被替换的语言
符号。
假如你确实希望在字符串中包含宏参数,那我们就可以使用“#”,它可以把语言符号转
化为字符串。上面的例子改一改:
#define SQR(x) printf("The square of "#x" is %d.\n", ((x)*(x)));
再使用
SQR(8);
则输出的是:
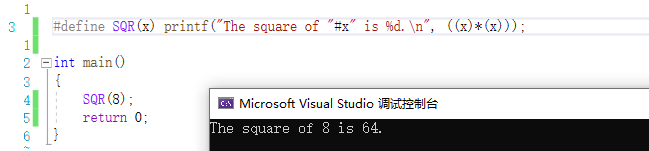
将宏参数与特定的符号组合成一个全新的符号
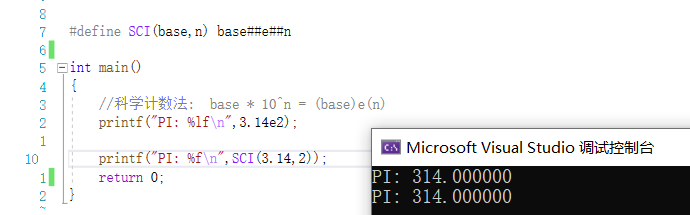
有不足的地方欢迎大家评论区留言指正。
热门资讯







