
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 论文提出了T2T-ViT模型,引入tokens-to-token(T2T)模块有效地融合图像的结构信息,同时借鉴CNN结果设计了deep-narrow的ViT主干网络,增强特征的丰富性。在ImageNet上从零训练时,T2T-ViT取得了优于ResNets的性能MobileNets性能相当
来源:晓飞的算法工程笔记 公众号
论文: Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet

尽管ViT证明了纯Transformer架构对于视觉任务很有前景,但在中型数据集(例如ImageNet)上从零训练时,其性能仍然不如大小类似的CNN网络(例如 ResNets)。
论文认为这种性能差距源于ViT的两个主要限制:

为了验证,论文对ViTL/16和ResNet50学习到的特征进行可视化对比。如图2所示,ResNet逐层捕获所需的局部结构信息(边缘、线条、纹理等),而ViT特征的结构信息建模不佳,所有注意力块都捕获全局关系(例如,整只狗)。这表明,ViT将图像拆分为具有固定长度的token时忽略了局部结构。此外,论文发现ViT中的许多通道的值为零,这意味着ViT的主干网络不如ResNets高效。如果训练样本不足,则只能提供特征的丰富度有限。
基于上面的观察,论文设计了一个新的Vision Transformer模型来克服上述限制:
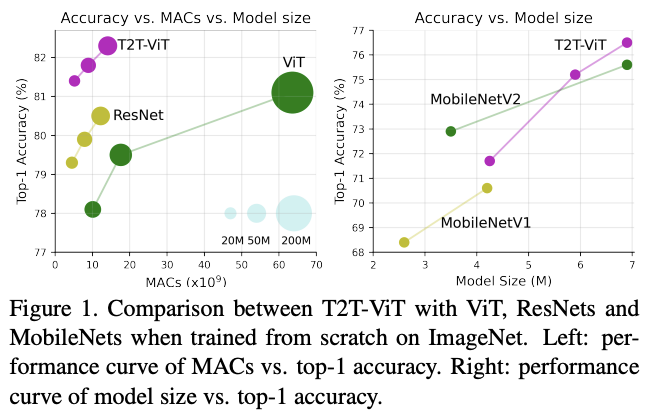
基于T2T模块和deep-narrow主干架构,论文设计了Tokens-to-Token Vision Transformer (T2T-ViT)。对比原生的ViT,在ImageNet上从零开始训练的性能有显着的提高,与CNN网络相当甚至更好。
总体言之,论文的贡献有三方面:
为了克服ViT的简单token生成和低效主干网络的局限性,论文提出了Tokens-to-Token Vision Transformer(T2T-ViT),可以逐步将图像转换为token并且主干网络更高效。因此,T2T-ViT由两个主要组件组成:
Token-to-Token(T2T)模块主要为了克服ViT中简单token生成的限制,逐步将图像结构化为token以及对局部结构信息进行建模,并且可以迭代地减少token数量。每个T2T操作都包含两个步骤:Re-structurization和Soft Split(SS)。
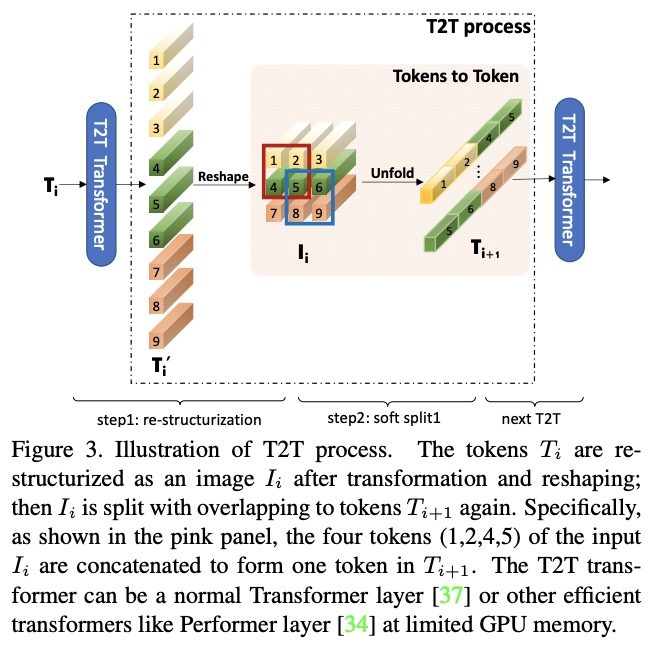
如图 3 所示,给定token序列 \(T\) ,先通过自注意模块(T2T Transformer)进行变换:
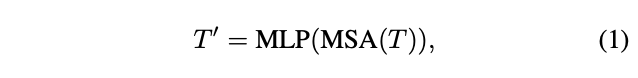
其中MSA为具有层归一化的多头自注意操作,MLP是标准Transformer中具有层归一化的多层感知器。MSA输出的 \(T^{'}\) 将被重塑为空间维度上的图像:
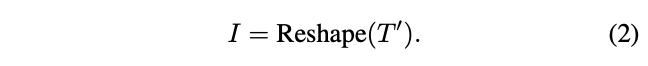
Reshape表示将 \(T^{'}\in \mathbb{R}^{l\times c}\) 重新组织为 \(I\in \mathbb{R}^{h\times w\times c}\) ,其中 \(l\) 是 \(T^{'}\) 的长度,h、w、c 分别是高度、宽度和通道数,并且 \(l=h\times w\) 。
如图3所示,在获得重构图像 \(I\) 后,使用Soft Split来建模局部结构信息并减少token的长度。为了避免信息丢失,将图像拆分为重叠的分割区域,每个区域都与周围的区域相关。这样就建立了一个先验,即相邻分割区域生成的token之间应该有更强的相关性。随后将每个分割区域中的token拼接为一个token,从周围的像素或token中聚合局部信息。
进行Soft Split时,每个分割区域的大小为 \(k\times k\) ,区域重叠为 \(s\) ,图像边界填充为 \(p\) ,其中 \(k-s\) 类似于卷积操作中的步长。对于重建图像 \(I\in \mathbb{R}^{h\times w\times c}\) ,Soft Split后输出的token \(T_{o}\) 的长度为:
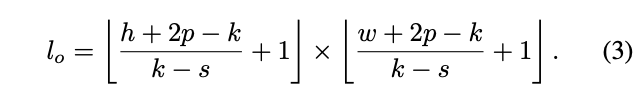
每个分割区域的大小为 \(k\times k\times c\) ,将所有分割区域展平后得到token序列 \(T_{o}\in \mathbb{R}^{l_{o}\times ck^2}\) 。在Soft Split之后,输出token可进行下一轮T2T操作。
通过反复进行Re-structurization和Soft Split,T2T模块可以逐步减少token的长度以及变换图像的空间结构。T2T模块的迭代过程可以表述为:
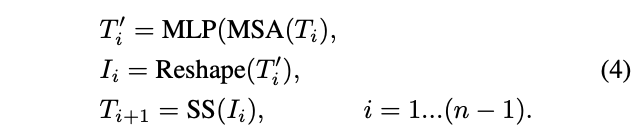
对于输入图像 \(I_{0}\) ,先应用Soft Split将其拆分为token序列 \(T_{1} = SS(I_{0})\) 。在最后一次迭代之后,T2T模块的输出固定长度的token序列 \(T_{f}\) 。因此,T2T-ViT 的主干网络可以在 \(T_{f}\) 上建模全局关系。
此外,由于T2T模块中的token长度大于ViT中的一般设置(16 × 16),MAC和内存使用量都很大。为了解决这个问题,将T2T层的通道维度设置为较小的值(32或64)来减少 MAC,也可以采用高效的Transformer层变种,例如 Performer层,从而在有限的GPU内存下减少内存使用。
由于ViT主干网络中许多通道是无效的,论文打算为T2T-ViT重新设计一个高效的主干网络,减少冗余并提高特征丰富度。论文借鉴了CNN的一些设计,探索不同的ViT架构设计。由于每个Transformer层都具有ResNets的短路连接,可以参考DenseNet增加特征复用和特征丰富程度,或者参考Wide-ResNets和ResNeXt调整通道维度和head数。
论文在ViT上探索了以下五种CNN的架构设计:
论文对以上结构移植进行了实验,有以下两点发现:
基于这些发现,论文为T2T-ViT主干网络设计了一个 deep-narrow的架构,具有较小的通道数和隐藏维度 \(d\) ,但层数 \(b\) 更多。对于T2T模块输出的固定长度的token序列 \(T_{f}\) ,为其添加一个class token,然后加入Sinusoidal Position Embedding(PE),最后与ViT一样进行分类:
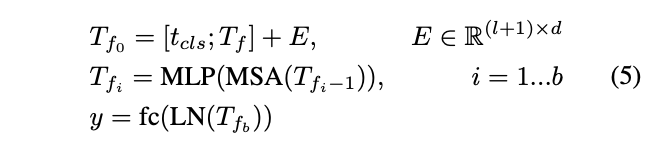
其中, \(E\) 是Sinusoidal Position Embedding,LN是层归一化,fc是用于分类的全连接层, \(y\) 是输出预测。
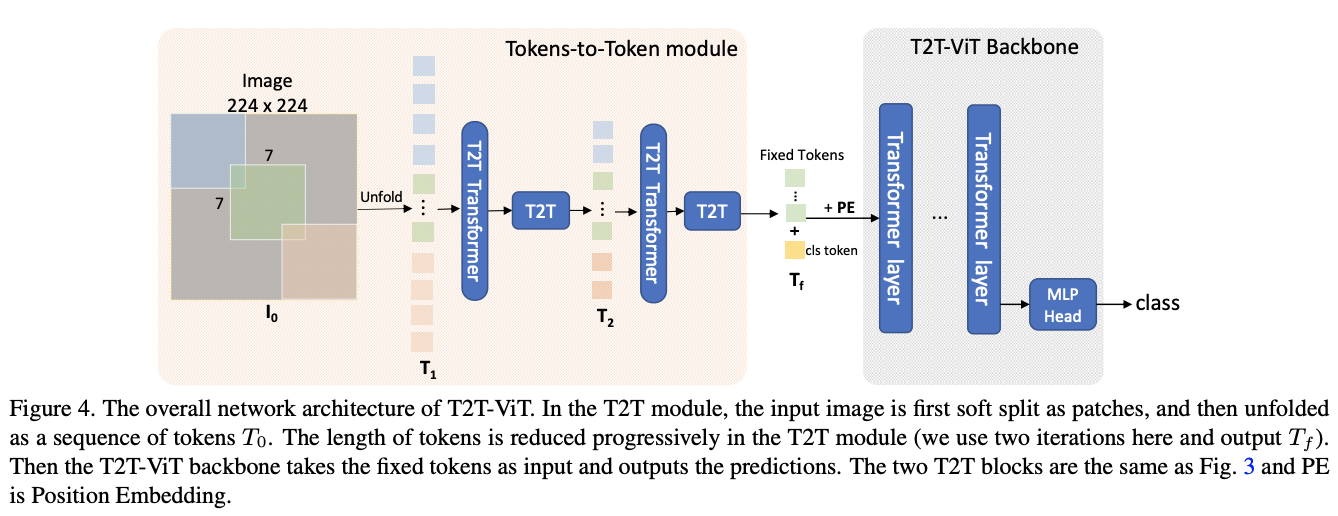
T2T-ViT包含两部分:Tokens-to-Token(T2T)模块和T2T-ViT主干网络。T2T模块有多种设计选择,论文设置 \(n = 2\) ,T2T模块中有 \(n+1=3\) 次Soft Split和 \(n=2\) 次Re-structurization。三次Soft Split的分区区域设置为 \(P = [7, 3, 3]\) ,重叠区域设置为 \(S=[3, 1, 1]\) ,可以将 \(224\times 224\) 的输入图片压缩为 \(14\times 14\) 的token序列。
T2T-ViT主干网络从T2T模块中取固定长度token序列作为输入,基于deep-narrow架构设计,中间特征维度(256-512)和MLP大小(512-1536)比ViT小很多。例如,T2T-ViT-14的主干网络中有14个Transofmer层,中间特征维度为384,而ViT-B/16有12个Transformer层,中间特征维度为768,参数量和MACs是T2T-ViT-14的3倍。
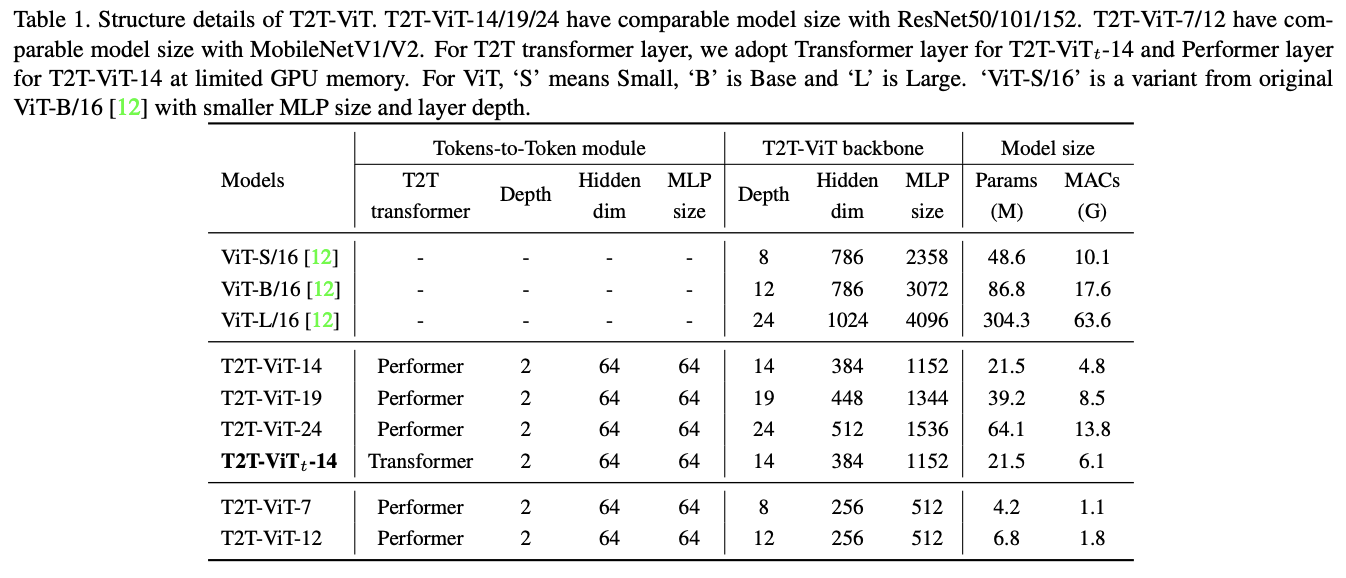
为了方便与ResNet进行比较,论文设计了三个的T2T-ViT模型:T2T-ViT-14、T2T-ViT-19 和 T2T-ViT-24,参数量分别与ResNet50、ResNet101和ResNet152相当。而为了与MobileNets等小型模型进行比较,论文设计了两个lite模型:T2T-ViT-7、T2TViT-12,其模型大小与MibileNetV1和MibileNetV2相当。两个lite TiT-ViT没有使用特殊设计或技巧,只是简单地降低了层深度、中间特征维度以及MLP比例。
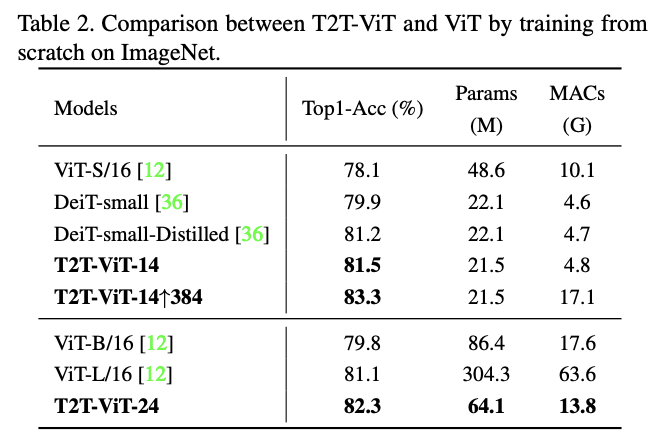
与ViT的从零训练对比。
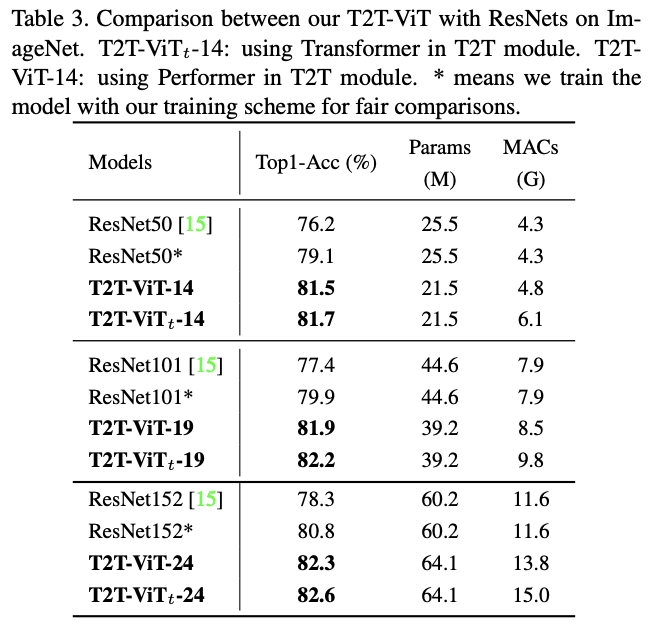
与ResNet对比。
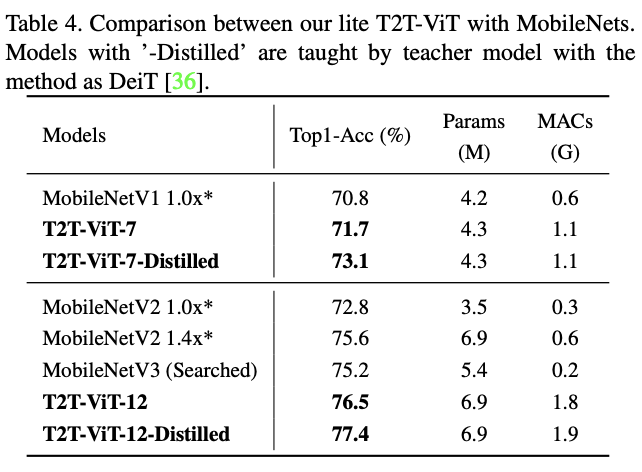
与MobileNet对比。

对预训练模型进行迁移至CIFAR进行finetune对比。
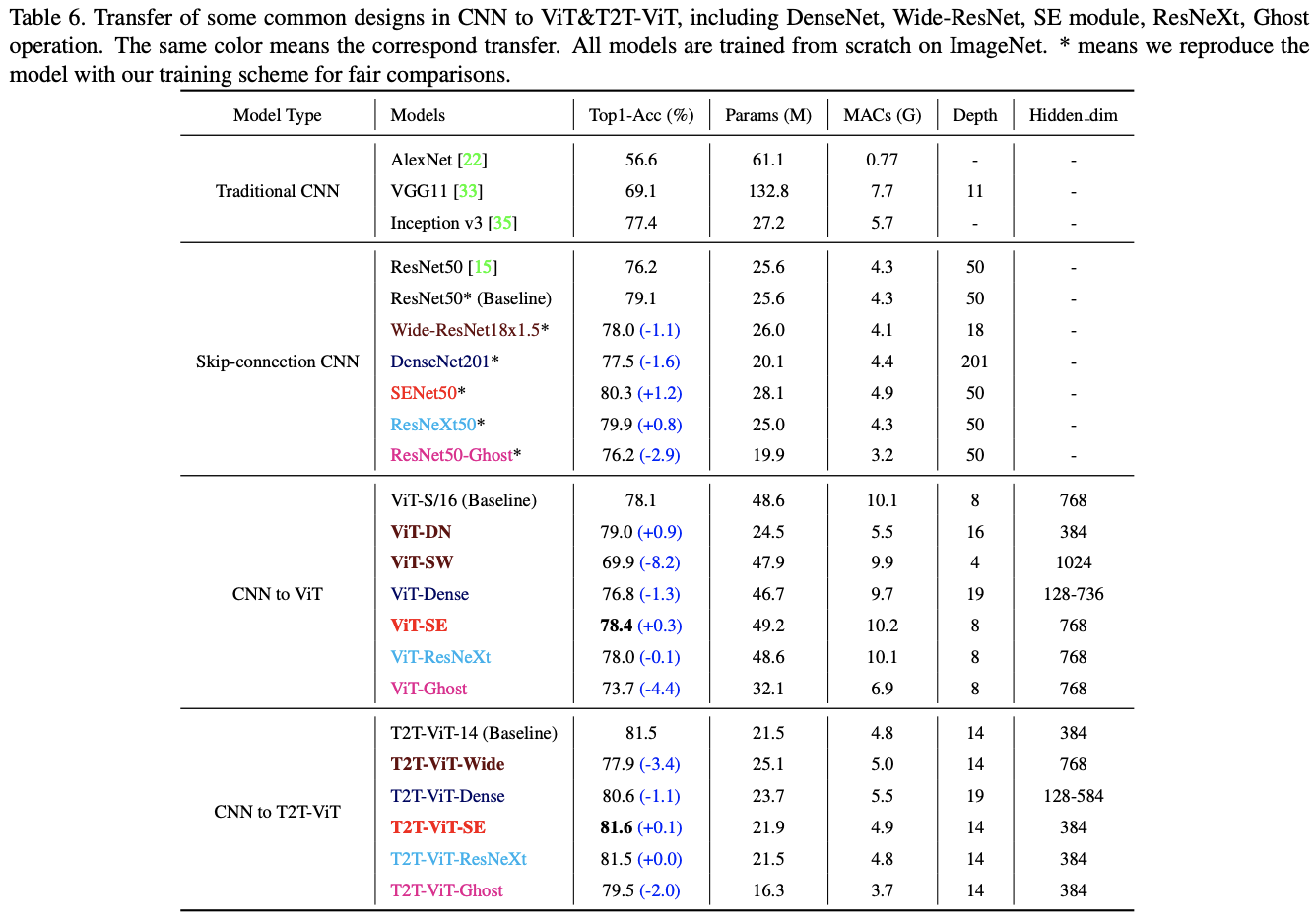
对比不同类型的网络以及对T2T-ViT的修改。
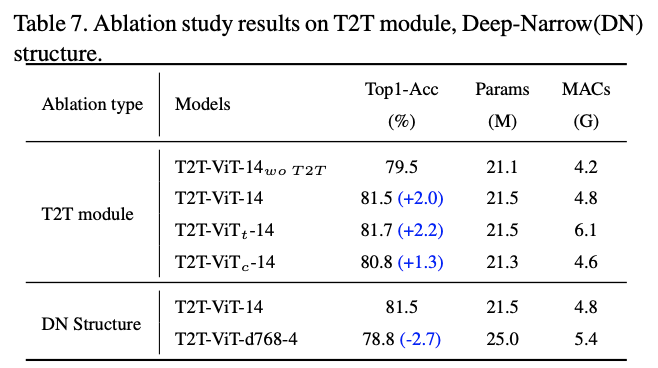
模块对比实验,c是用3个卷积代替T2T模块。
论文提出了T2T-ViT模型,引入tokens-to-token(T2T)模块有效地融合图像的结构信息,同时借鉴CNN结果设计了deep-narrow的ViT主干网络,增强特征的丰富性。在ImageNet上从零训练时,T2T-ViT取得了优于ResNets的性能MobileNets性能相当。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

热门资讯







