
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 论文设计了用于密集预测任务的纯Transformer主干网络PVT,包含渐进收缩的特征金字塔结构和spatial-reduction attention层,能够在有限的计算资源和内存资源下获得高分辨率和多尺度的特征图。从物体检测和语义分割的实验可以看到,PVT在相同的参数数量下比CNN主干网络更强大
来源:晓飞的算法工程笔记 公众号
论文: Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions

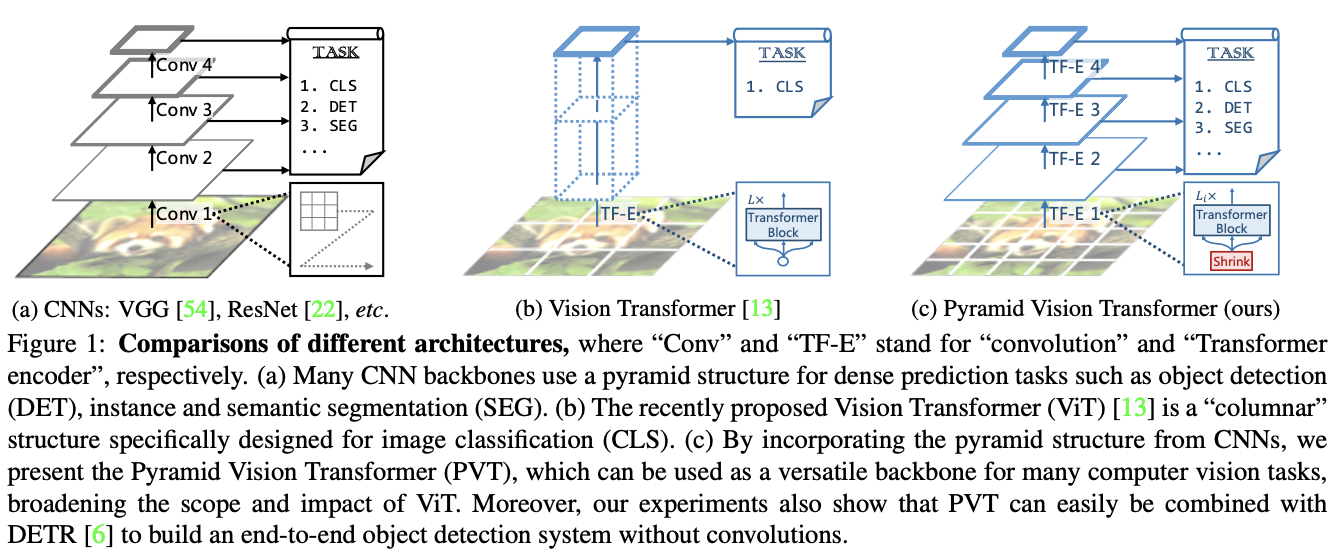
ViT用无卷积的纯Transformer模型替换CNN主干网络,在图像分类任务上取得了不错的结果。虽然ViT适用于图像分类,但直接将其用于像素级密集预测(如对象检测和分割)具有一定难度,主要原因有两点:
为了解决上述问题,论文提出了一个纯Transformer主干网络Pyramid Vision Transformer(PVT),能够在许多下游任务中作为CNN的替代品,包括图像级预测以及像素级密集预测。如图1c所示,PVT通过以下几点来达成目的:
总体而言,论文提出的的PVT具有以下优点:
论文的主要贡献如下:
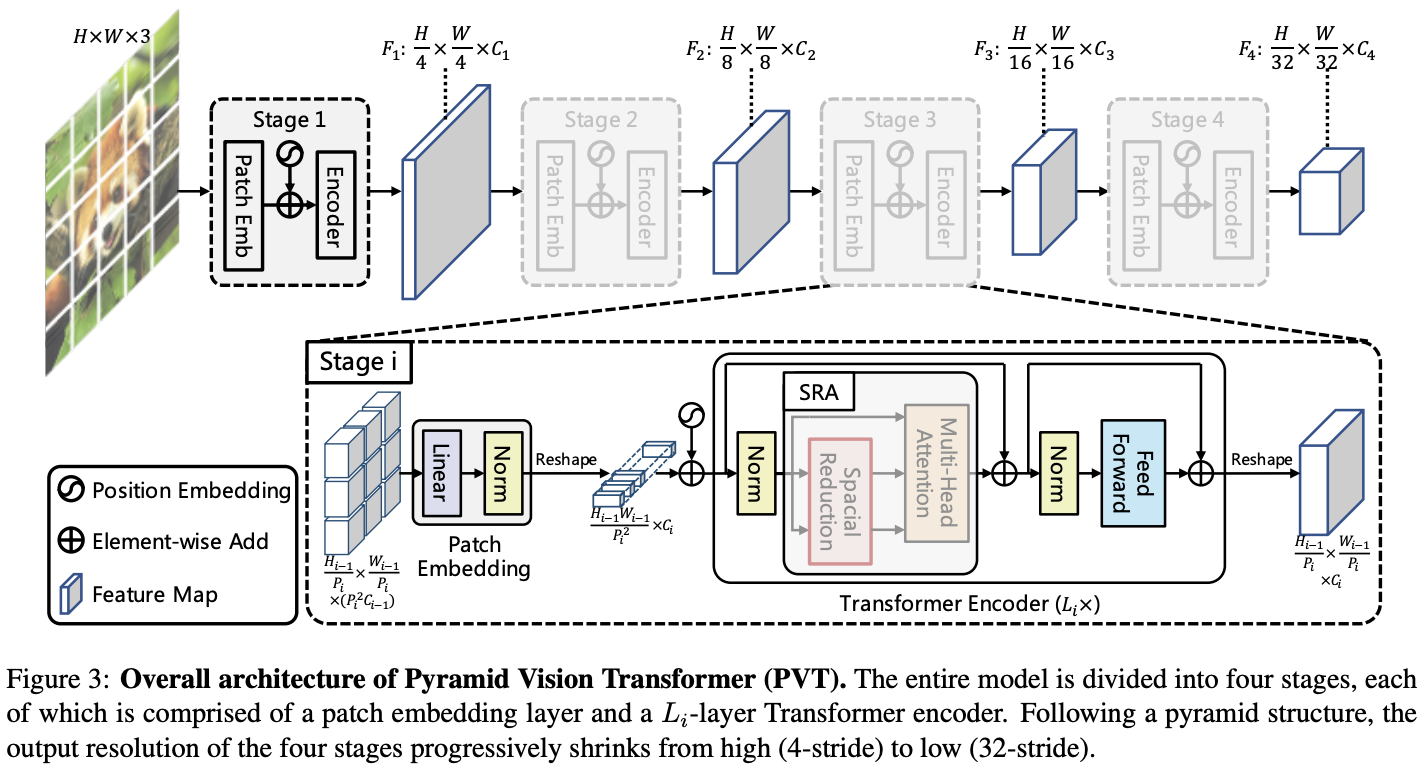
论文的核心是将特征金字塔结构加入到Transformer框架中,以便在密集预测任务中生成多尺度特征图。PVT的整体结构如图3所示,与CNN主干网络类似,包含四个生成不同尺寸特征图的Stage。所有Stage都具有类似的结构,由Patch Embedding层和
\(L_i\)
个Transformer encdoer层组成。
在Stage 1,给定
\(H\times W\times 3\)
的输入图像,先将其划分为
\(\frac{HW}{4^2}\)
个大小为
\(4\times 4\times 3\)
的图像块,将其输入到Patch Embedding层后展开为
\(\frac{HW}{4^2}\times C_1\)
的特征序列。然后将特征序列和Position embedding相加输入到
\(L_i\)
层的Transformer encdoer,最终输出大小为
\(\frac{H}{4}\times \frac{W}{4}\times C_1\)
的特征图
\(F_1\)
。
后续的Stage将前一阶段的特征输出作为输入进行同样的操作,分别输出特征图:
\(F_2\)
、
\(F_3\)
和
\(F_4\)
,相对于输入图像的缩小比例为8、16和32倍。通过特征金字塔{
\(F_1\)
,
\(F_2\)
,
\(F_3\)
,
\(F_4\)
},PVT可以很容易地应用于大多数下游任务,包括图像分类、目标检测和语义分割。
与使用不同步长卷积构造多尺度特征图的CNN主干网络不同,PVT使用渐进收缩的策略,由Patch Embedding层控制特征图的尺寸。
设定Stage
\(i\)
的单个特征块的大小为
\(P_i\)
。在Stage开始时,将输入特征图
\(F_{i-1}\in \mathbb{R}^{H_{i-1}\times W_{i-1}\times C_{i-1}}\)
平均划分为
\(\frac{H_{i-1}W_{i-1}}{P^2_i}\)
个特征块。按特征块线性映射成
\(C_i\)
维并展平成特征序列,经过Transofrmer encdoer处理后reshape为
\(\frac{H_{i−1}}{P_i}\times \frac{W_{i−1}}{P_i}\times C_i\)
的特征图,其中高度和宽度是输入的
\(\frac{1}{P_i}\)
倍。
这样,每个Stage都可以通过调整
\(P_i\)
来灵活地调整特征图的比例,从而为Transformer构建一个特征金字塔。
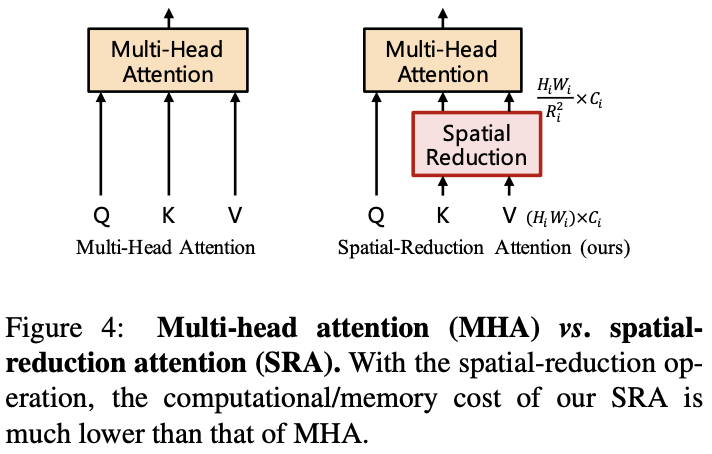
Stage
\(i\)
中的Transformer encoder具有
\(L_i\)
个encoder层,每层由一个attention层和feed-forward层组成。由于PVT需要处理高分辨率的特征图,论文提出了spatial-reduction attention(SRA)层来取代encoder中的multi-head attention(MHA)层。
SRA与MHA一样接收query
Q
、key
K
和value
V
作为输入,不同之处在于SRA在attention操作之前降低了
K
和
V
的特征维度,这可以在很大程度上减少计算和内存的开销。Stage
\(i\)
的SRA可公式化为:
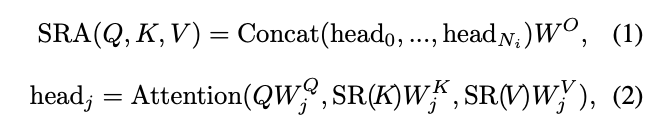
其中,
\(Concat(\cdot)\)
是特征拼接操作。
\(W^Q_j\in \mathbb{R}^{C_i\times d_{head}}\)
,
\(W^K_j\in \mathbb{R}^{C_i\times d_{head}}\)
,
\(W^V_j\in \mathbb{R}^{C_i\times d_{head}}\)
和
\(W^O\in \mathbb{R}^{C_i\times d_{head}}\)
是线性变换的参数,
\(N_i\)
是attention层的head数量。因此,每个head的特征维度等于
\(\frac{C_i}{N_i}\)
。
\(SR(\cdot)\)
是用于降低输入特征序列(即
K
或
V
)的特征维度的操作,公式为:
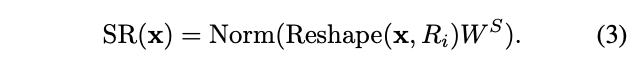
\(x\in \mathbb{R}^{(H_i W_i)\times C_i}\) 表示输入特征序列, \(R_i\) 表示Stage \(i\) 中attention层的缩减比例。 \(Reshape(x, R_i)\) 用于将输入序列 \(x\) reshape成大小为 \(\frac{H_i W_i}{R^2_i}\times(R^2_i C_i)\) 的序列。 \(W_S\in \mathbb{R}^{(R^2_i C_i)\times C_i}\) 为线性映射参数,将reshape后的输入序列的维度降至 \(C_i\) 。 \(Norm(\cdot)\) 为层归一化。attention操作 \(Attention(\cdot)\) 与原始Transformer一样,计算公式如下:
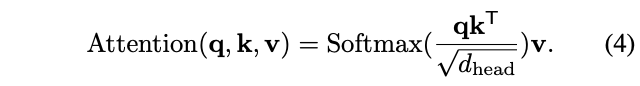
通过这些公式可以看到,SRA的计算和内存成本比MHA低 \(R^2_i\) 倍,可以用有限的资源处理较大的输入特征图或特征序列。
总体而言,PVT的超参数如下所示:
根据ResNet的设计规则,PVT在浅层使用较小输出通道数,在中间层集中主要计算资源。
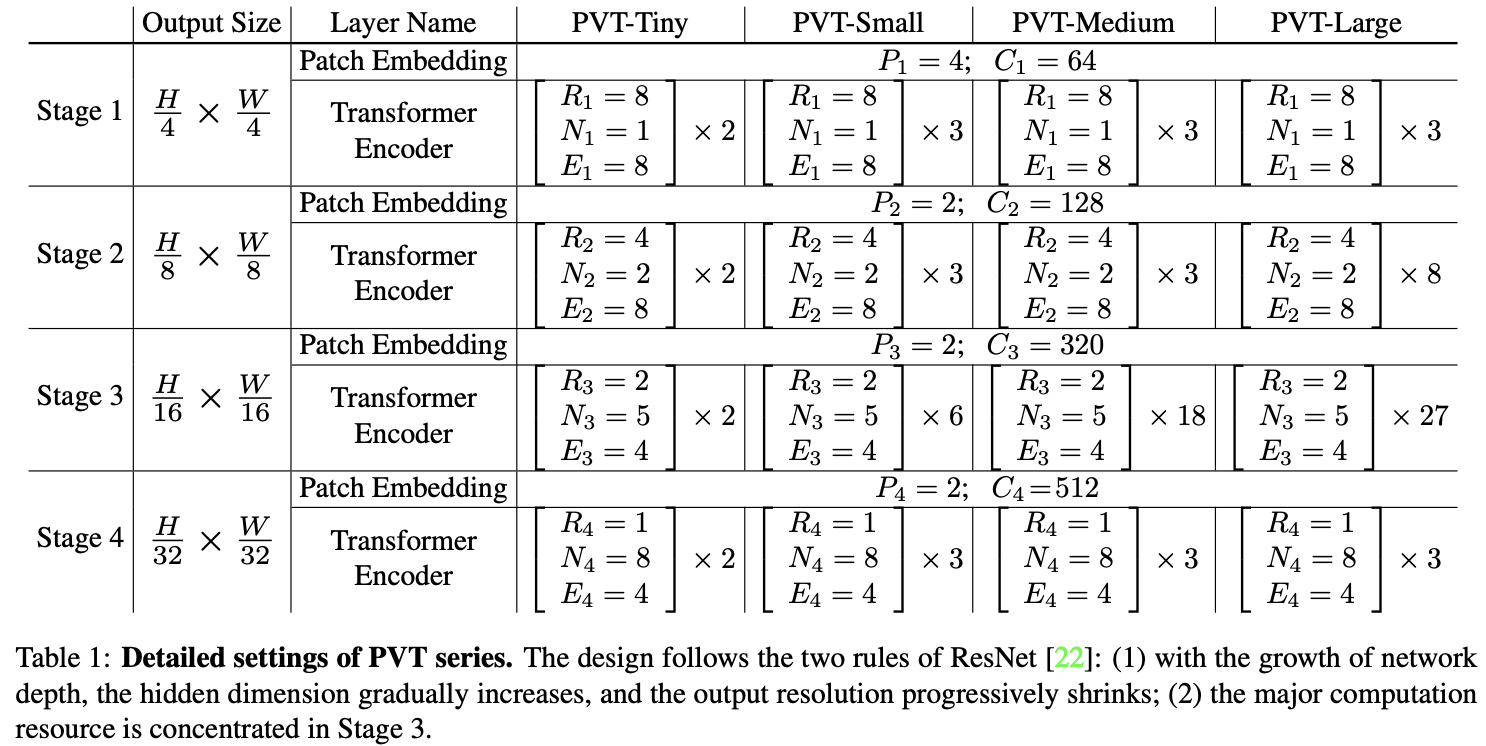
如表1所示,为了方便对比,论文设计了一系列不同尺度的PVT模型PVT Tiny、Small、Medium和Large,参数量分别对标ResNet18、50、101和152。
ViT是与PVT最相关的研究,论文特意对它们之间的关系和区别进行了说明:
PVT加入了渐进收缩的特征金字塔,可以像传统的CNN主干网络一样生成多尺度特征图。此外,PVT还加入了一种简单但高效的attention层SRA,能够处理高分辨率特征地图并减少计算/内存消耗。得益于上述设计,PVT与ViT相比具有以下优点:
图像分类是图像级预测中最经典的任务,论文设计了一系列不同尺度的PVT模型PVT Tiny、Small、Medium和Large,其参数量分别对标ResNet18、50、101和152。
在进行图像分类时,遵循ViT和DeiT的做法将可学习的分类token附加到最后的阶段的输入,然后使用FC层对token对应的输出进行分类。
在下游任务中,经常需要在特征图上执行像素级分类或回归的密集预测,比如目标检测和语义分割。将PVT模型应用于三种具有代表性的密集预测方法:RetinaNet、Mask RCNN和Semantic FPN,基于这些方法来对比不同主干网络的有效性,实现细节如下:
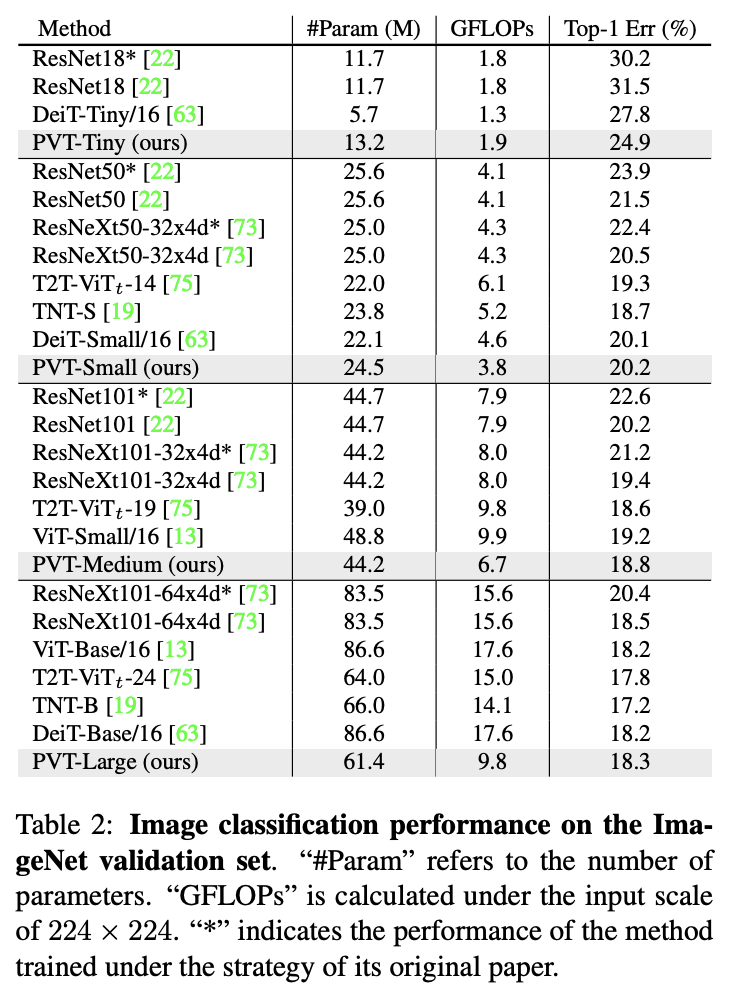
ImageNet上的性能对比。
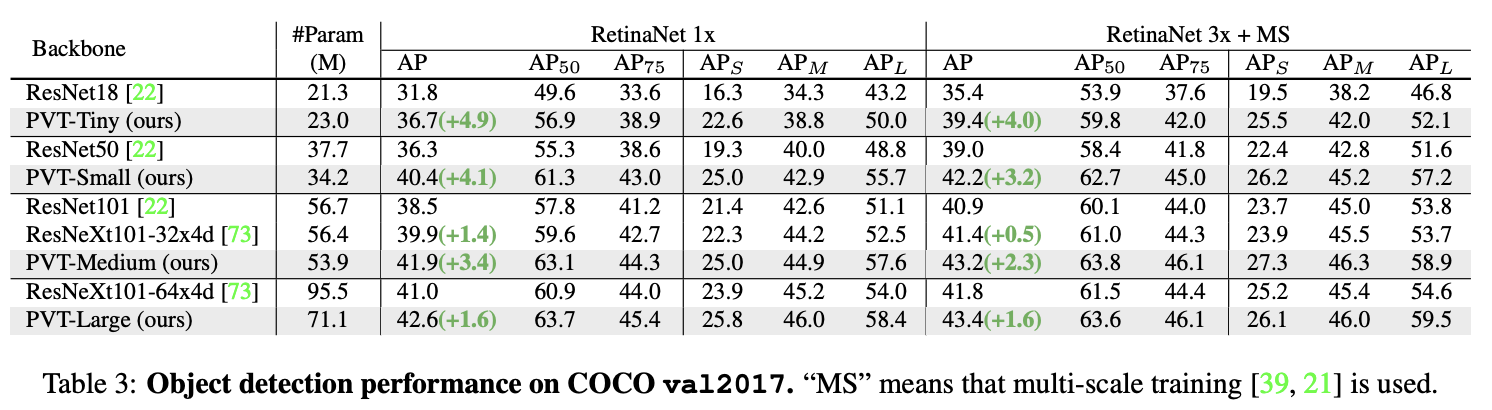
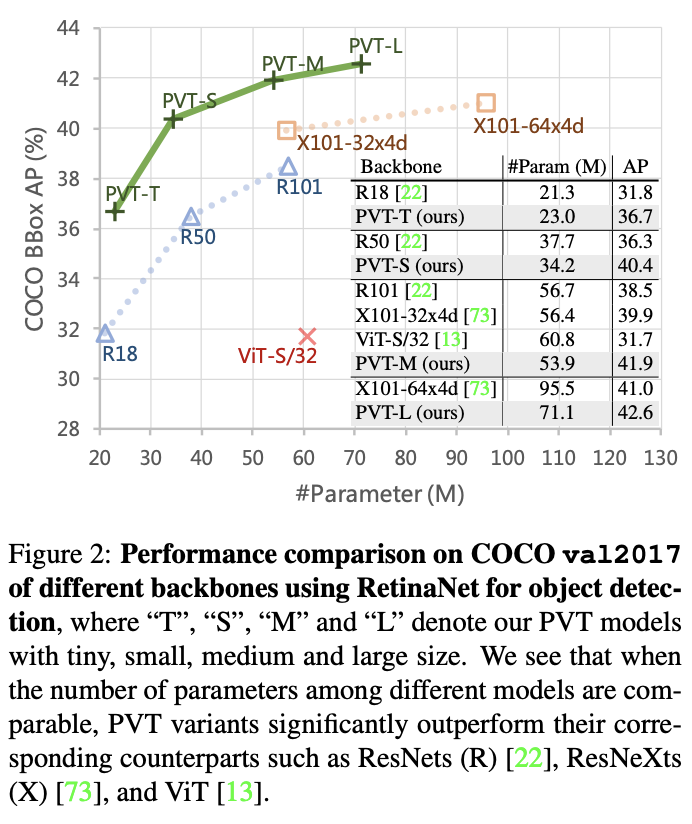
COCO val2017上的目标检测性能。
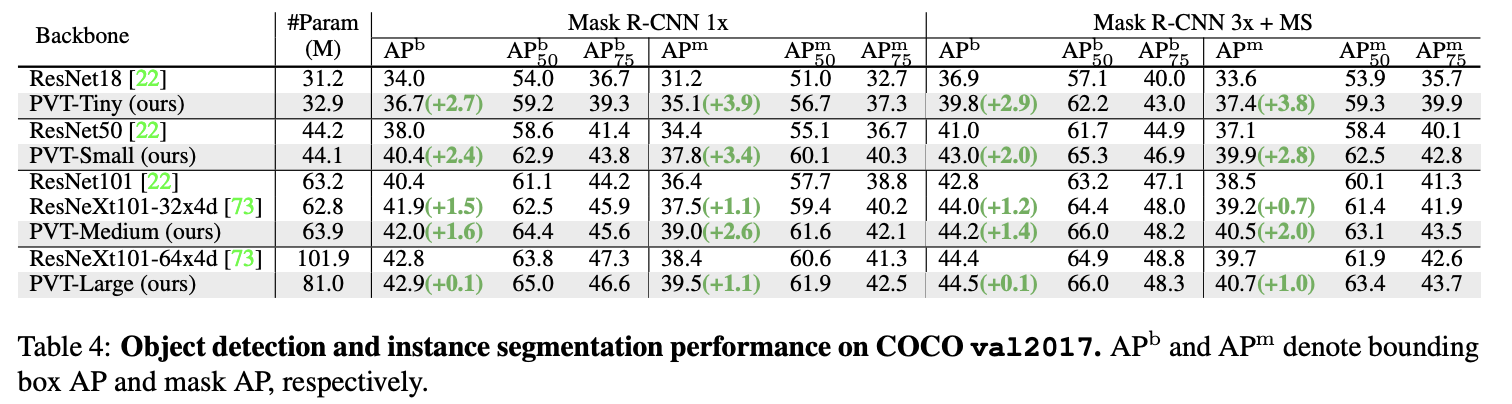
COCO val2017上的实例分割性能。
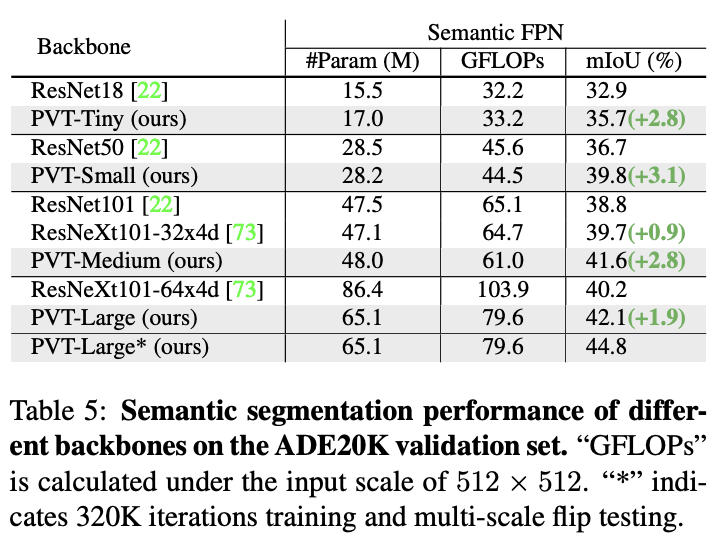
ADE20K上的语义分割性能。

与DETR结合的纯Transformer目标检测性能。
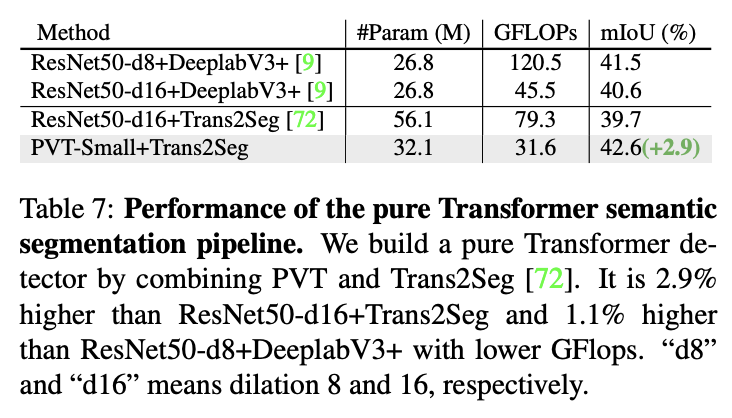
与Trans2Seg结合的纯Transformer语义分割性能。
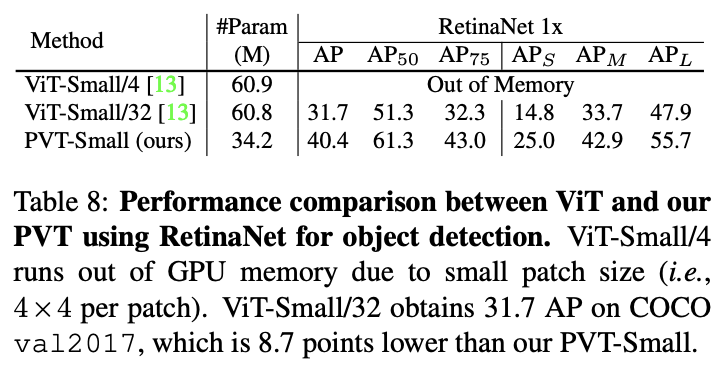
与ViT作为主干网络的目标检测性能对比。
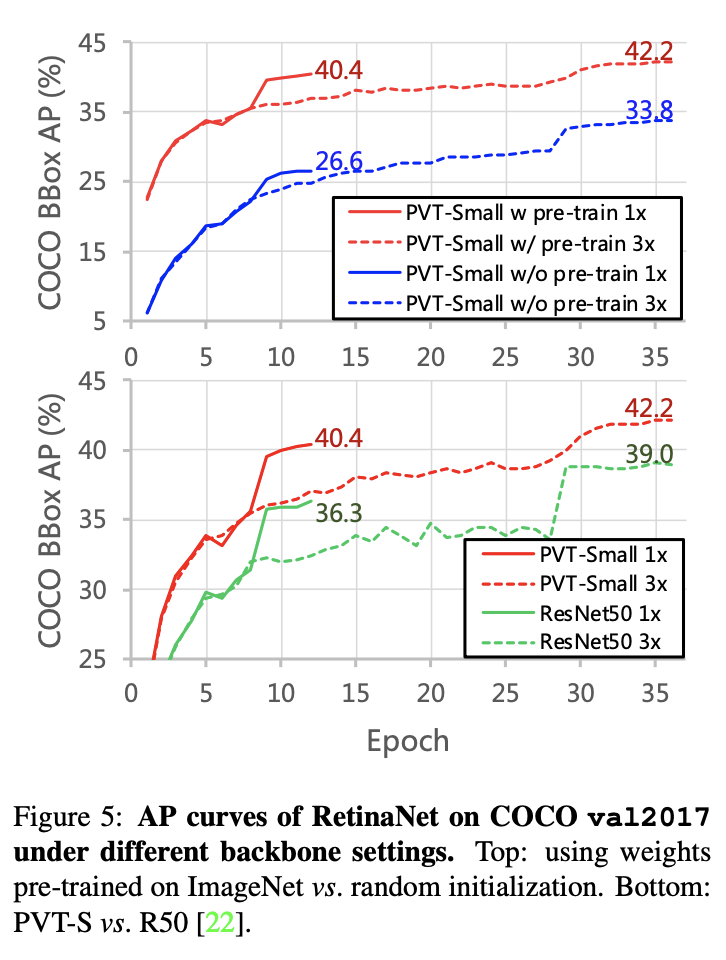
不同训练周期以及预训练对检测性能的影响
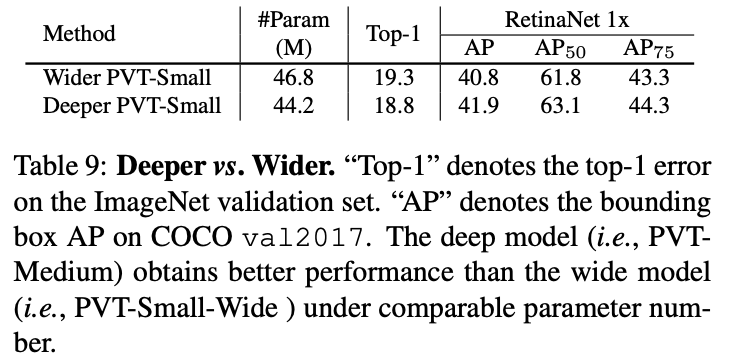
深度和参数对检测性能的影响。
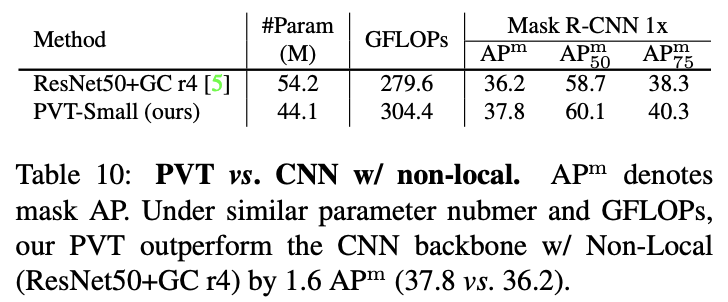
与加上non-local的CNN网络的性能对比。
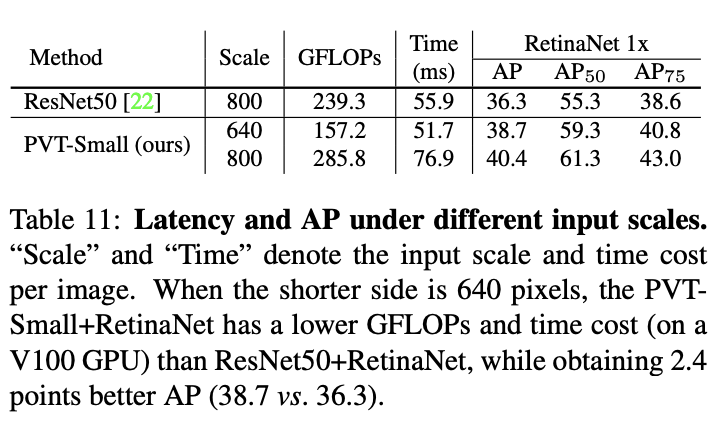
输入尺寸对性能的影响。
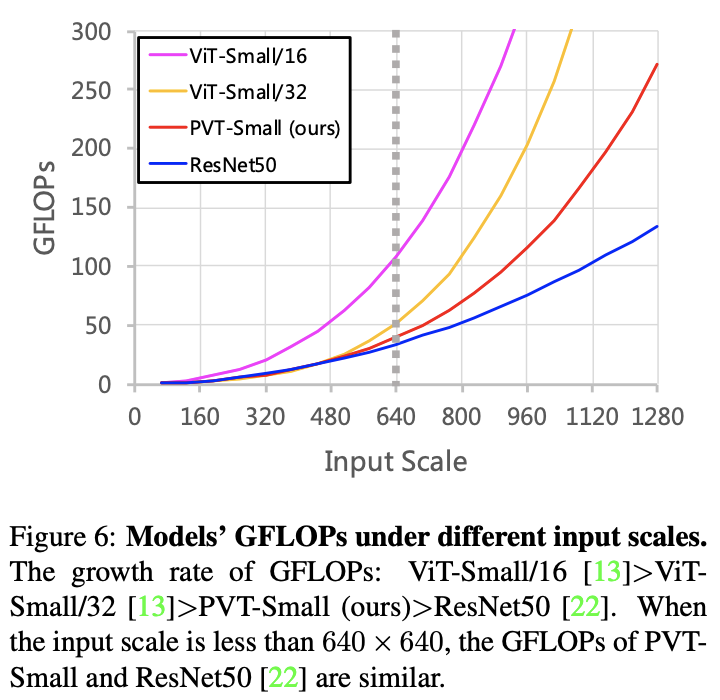
输入分辨率与参数量的关系。

目标检测、实例分割、语义分割的结果可视化。
论文设计了用于密集预测任务的纯Transformer主干网络PVT,包含渐进收缩的特征金字塔结构和spatial-reduction attention层,能够在有限的计算资源和内存资源下获得高分辨率和多尺度的特征图。从物体检测和语义分割的实验可以看到,PVT在相同的参数数量下比CNN主干网络更强大。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

热门资讯







