
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版
论文提出CeiT混合网络,结合了CNN在提取低维特征方面的局部性优势以及Transformer在建立长距离依赖关系方面的优势。CeiT在ImageNet和各种下游任务中达到了SOTA,收敛速度更快,而且不需要大量的预训练数据和额外的CNN蒸馏监督,值得借鉴
来源:晓飞的算法工程笔记 公众号
论文: Incorporating Convolution Designs into Visual Transformers

在视觉领域中,纯Transformer架构往往需要大量的训练数据或额外的监督来达到与CNN相当的性能。为了克服这些限制,论文对直接使用Transformer架构的潜在缺点进行了分析,发现Transformer主要缺乏了CNN的平移不变性以及局部性。于是,论文将CNN在提取低维特征方面的局部性优势以及Transformer在建立长距离依赖关系方面的优势进行结合,提出了Convolution-enhanced image Transformer(CeiT)混合网络。
论文对原生Transformer做了三处修改:
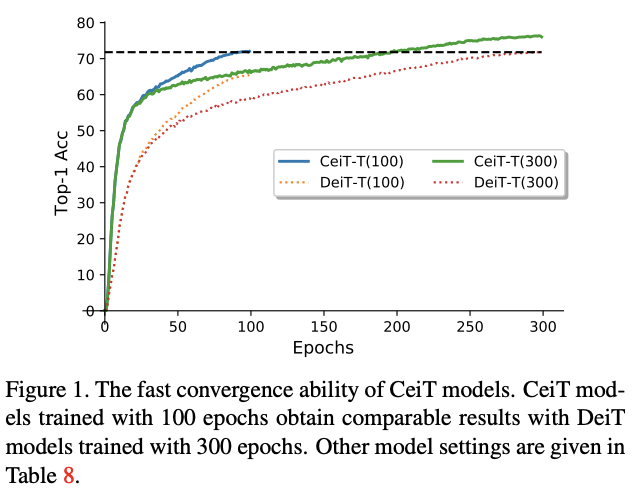
在ImageNet和七个下游任务的实验结果表明,CeiT的性能和泛化能力比之前的Transformer和CNN更优,而且不需要大量的训练数据和额外的CNN蒸馏。此外,CeiT模型的收敛性更好,训练迭代次数减少了3倍,极大地降低了训练成本。
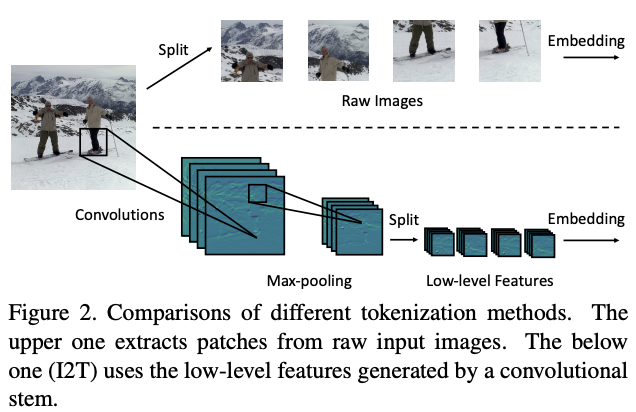
为了优化初始token序列的生成,论文提出了简单而有效的Imageto-Tokens(I2T)模块,从生成的低维特征中提取token序列,而不是将原始输入图像直接分割。如图2所示,I2T模块是由卷积层和最大池化层组成的轻量级stem结构,卷积层后面会进行BN操作。整个模块可表示为:
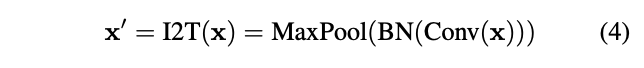
其中 \(x^{'}\in \mathbb{R}^{\frac{H}{S}\times \frac{W}{S}\times D}\) , \(S\) 为卷积的stride参数, \(D\) 为卷积输出的通道数。
在得到输出特征图后,根据空间维度从中切割图像块序列。为了保持生成的标记数量与ViT一致,论文将图像块的分辨率缩减为 \((\frac{P}{S} ,\frac{P}{S})\) ,在实践中设定 \(S = 4\) 。最后,通过embedding操作将图像块序列转换为token序列。
I2T模块能够充分发挥CNN在提取低层次特征方面的优势,并且能够通过缩小图像块的大小来降低embedding的训练难度。与用ResNet-50来提取后两个阶段的高层特征的混合类型Transformer对比,I2T模块要轻量得多。
热门资讯







