
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 代码 kubernetes 1.26.15
混部机子批量节点NotReady(十几个,丫的重大故障),报错为:
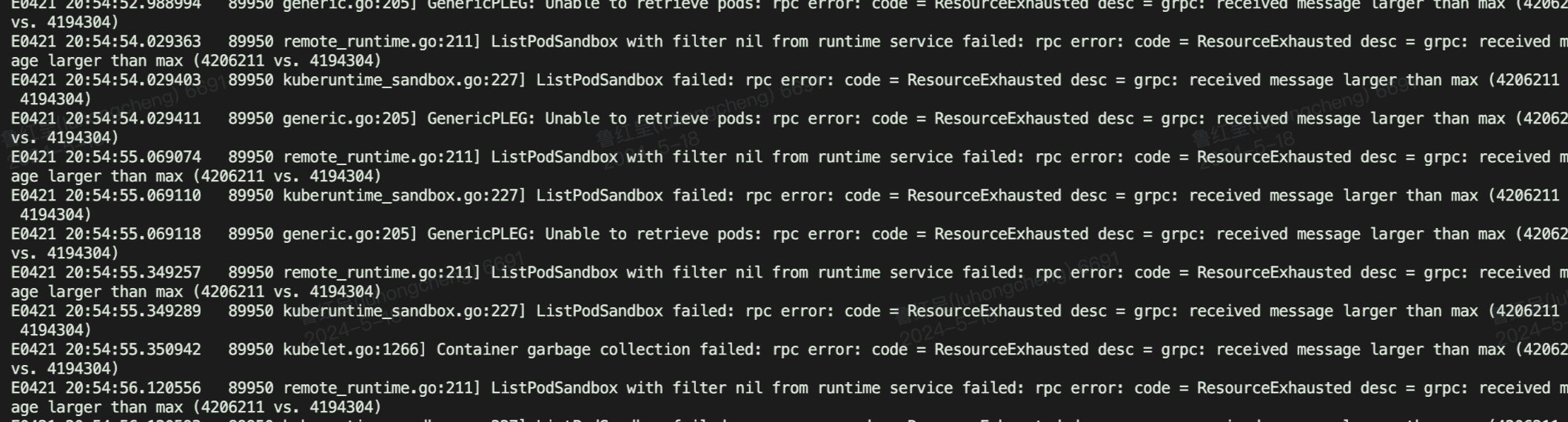
意思就是 rpc 超了,节点下有太多 PodSandBox,crictl ps -a 一看有1400多个。。。大量exited的容器没有被删掉,累积起来超过了rpc限制。
PodSandBox 泄漏,crictl pods 可以看到大量同名但是 pod id不同的sanbox,几个月了kubelet并不主动删除
crictl pods
crictl inspectp
crictl ps -a | grep
crictl logs
kubelet通过cri和containerd进行交互。crictl也可以通过cri规范和containerd交互
crictl 是 CRI(规范) 兼容的容器运行时命令行接口,可以使用它来检查和调试 k8s node节点上的容器运行时和应用程序。
kubernetes 垃圾回收(Garbage Collection)机制由kubelet完成,kubelet定期清理不再使用的容器和镜像,每分钟进行一次容器的GC,每五分钟进行一次镜像的GC
pkg/kubelet/kubelet.go:1352,开始GC
func (kl *Kubelet) StartGarbageCollection()
pkg/kubelet/kuberuntime/kuberuntime_gc.go:409
// GarbageCollect removes dead containers using the specified container gc policy.
// Note that gc policy is not applied to sandboxes. Sandboxes are only removed when they are
// not ready and containing no containers.
//
// GarbageCollect consists of the following steps:
// * gets evictable containers which are not active and created more than gcPolicy.MinAge ago.
// * removes oldest dead containers for each pod by enforcing gcPolicy.MaxPerPodContainer.
// * removes oldest dead containers by enforcing gcPolicy.MaxContainers.
// * gets evictable sandboxes which are not ready and contains no containers.
// * removes evictable sandboxes.
func (cgc *containerGC) GarbageCollect(ctx context.Context, gcPolicy kubecontainer.GCPolicy, allSourcesReady bool, evictNonDeletedPods bool) error {
errors := []error{}
// Remove evictable containers
if err := cgc.evictContainers(ctx, gcPolicy, allSourcesReady, evictNonDeletedPods); err != nil {
errors = append(errors, err)
}
// Remove sandboxes with zero containers
if err := cgc.evictSandboxes(ctx, evictNonDeletedPods); err != nil {
errors = append(errors, err)
}
// Remove pod sandbox log directory
if err := cgc.evictPodLogsDirectories(ctx, allSourcesReady); err != nil {
errors = append(errors, err)
}
return utilerrors.NewAggregate(errors)
}
pkg/kubelet/kuberuntime/kuberuntime_gc.go:187
ContainerState_CONTAINER_RUNNING
和 container.CreatedAt 小于 minAge 直接跳过。
map[evictUnit][]containerGCInfo
// evictUnit is considered for eviction as units of (UID, container name) pair.
type evictUnit struct {
// UID of the pod.
uid types.UID
// Name of the container in the pod.
name string
}
// containerGCInfo is the internal information kept for containers being considered for GC.
type containerGCInfo struct {
// The ID of the container.
id string
// The name of the container.
name string
// Creation time for the container.
createTime time.Time
// If true, the container is in unknown state. Garbage collector should try
// to stop containers before removal.
unknown bool
}
// evict all containers that are evictable
func (cgc *containerGC) evictContainers(ctx context.Context, gcPolicy kubecontainer.GCPolicy, allSourcesReady bool, evictNonDeletedPods bool) error {
// Separate containers by evict units.
evictUnits, err := cgc.evictableContainers(ctx, gcPolicy.MinAge)
if err != nil {
return err
}
// Remove deleted pod containers if all sources are ready.
// 如果pod已经不存在了,那么就删除其中的所有容器。
if allSourcesReady {
for key, unit := range evictUnits {
if cgc.podStateProvider.ShouldPodContentBeRemoved(key.uid) || (evictNonDeletedPods && cgc.podStateProvider.ShouldPodRuntimeBeRemoved(key.uid)) {
cgc.removeOldestN(ctx, unit, len(unit)) // Remove all.
delete(evictUnits, key)
}
}
}
// Enforce max containers per evict unit.
// 执行 GC 策略,保证每个 POD 最多只能保存 MaxPerPodContainer 个已经退出的容器
if gcPolicy.MaxPerPodContainer >= 0 {
cgc.enforceMaxContainersPerEvictUnit(ctx, evictUnits, gcPolicy.MaxPerPodContainer)
}
// Enforce max total number of containers.
// 执行 GC 策略,保证节点上最多有 MaxContainers 个已经退出的容器
if gcPolicy.MaxContainers >= 0 && evictUnits.NumContainers() > gcPolicy.MaxContainers {
// Leave an equal number of containers per evict unit (min: 1).
numContainersPerEvictUnit := gcPolicy.MaxContainers / evictUnits.NumEvictUnits()
if numContainersPerEvictUnit < 1 {
numContainersPerEvictUnit = 1
}
cgc.enforceMaxContainersPerEvictUnit(ctx, evictUnits, numContainersPerEvictUnit)
// If we still need to evict, evict oldest first.
numContainers := evictUnits.NumContainers()
if numContainers > gcPolicy.MaxContainers {
flattened := make([]containerGCInfo, 0, numContainers)
for key := range evictUnits {
flattened = append(flattened, evictUnits[key]...)
}
sort.Sort(byCreated(flattened))
cgc.removeOldestN(ctx, flattened, numContainers-gcPolicy.MaxContainers)
}
}
return nil
}
// removeOldestN removes the oldest toRemove containers and returns the resulting slice.
func (cgc *containerGC) removeOldestN(ctx context.Context, containers []containerGCInfo, toRemove int) []containerGCInfo {
// Remove from oldest to newest (last to first).
numToKeep := len(containers) - toRemove
if numToKeep > 0 {
sort.Sort(byCreated(containers))
}
for i := len(containers) - 1; i >= numToKeep; i-- {
if containers[i].unknown {
// Containers in known state could be running, we should try
// to stop it before removal.
id := kubecontainer.ContainerID{
Type: cgc.manager.runtimeName,
ID: containers[i].id,
}
message := "Container is in unknown state, try killing it before removal"
if err := cgc.manager.killContainer(ctx, nil, id, containers[i].name, message, reasonUnknown, nil); err != nil {
klog.ErrorS(err, "Failed to stop container", "containerID", containers[i].id)
continue
}
}
if err := cgc.manager.removeContainer(ctx, containers[i].id); err != nil {
klog.ErrorS(err, "Failed to remove container", "containerID", containers[i].id)
}
}
// Assume we removed the containers so that we're not too aggressive.
return containers[:numToKeep]
}
pkg/kubelet/kuberuntime/kuberuntime_gc.go:276
移除所有可驱逐的沙箱。可驱逐的沙箱必须满足以下要求: 1.未处于就绪状态2.不包含任何容器。3.属于不存在的 (即,已经移除的) pod,或者不是该pod的最近创建的沙箱。
目前现象是 crictl pods 可以看到大量同名但是 pod id不同的sanbox。 根据 3 点要求
因此sandbox 删不掉的原因是 sandbox下的容器未被删除
容器异常退出后,根据重启策略
restartPolicy: Always
pod 会不断重启,直到 超过时限失败。
https://kubernetes.io/zh-cn/docs/concepts/workloads/pods/pod-lifecycle/#pod-garbage-collection
对于已失败的 Pod 而言,对应的 API 对象仍然会保留在集群的 API 服务器上, 直到用户或者 控制器 进程显式地将其删除。
Pod 的垃圾收集器(PodGC)是控制平面的控制器,它会在 Pod 个数超出所配置的阈值 (根据
kube-controller-manager
的
terminated-pod-gc-threshold
设置 默认值:12500)时删除已终止的 Pod(阶段值为
Succeeded
或
Failed
)。 这一行为会避免随着时间演进不断创建和终止 Pod 而引起的资源泄露问题。
上面是pod纬度,但是我们的现象是容器删不掉,所以并不是原因,继续看代码 ?
经过大佬的实验验证,对于失败的 容器,只会保留一个失败的现场,多余的会GC掉,和 问题现场一致
容器 GC 虽然有利于空间和性能,但是删除容器也会导致错误现场被清理,不利于 debug 和错误定位,因此不建议把所有退出的容器都删除。
cmd/kubelet/app/options/options.go:183
// Maximum number of old instances of containers to retain globally. Each container takes up some disk space. To disable, set to a negative number.
// 我们可以设置这个值兜底
MaxContainerCount: -1,
MinimumGCAge: metav1.Duration{Duration: 0},
// 每个 container 最终可以保存多少个已经结束的容器,默认是 1,设置为负数表示不做限制
MaxPerPodContainerCount: 1,
再看上面容器GC代码
// 如果pod已经不存在了,那么就删除其中的所有容器。
....
// 执行 GC 策略,保证每个 POD 最多只能保存 MaxPerPodContainerCount 个已经退出的容器
// MaxPerPodContainerCount 默认值为1,对应保留一个失败的现场
if gcPolicy.MaxPerPodContainer >= 0 {
cgc.enforceMaxContainersPerEvictUnit(ctx, evictUnits, gcPolicy.MaxPerPodContainer)
}
// 保证节点上最多有 MaxContainerCount 个已经退出的容器
// MaxContainerCount 默认值为 -1 不限制,我们可以设置一个兜底
if gcPolicy.MaxContainers >= 0 && evictUnits.NumContainers() > gcPolicy.MaxContainers {
......
}
总结,容器失败,会保留一个现场不GC,导致越来越多失败的容器存在,最后容器过多,导致rpc传输超过限制,整个节点崩掉
#!/bin/bash
# 列出所有在 k8s.io 命名空间下的容器
containers=$(ctr -n k8s.io c list -q)
# 遍历容器 ID 并删除每一个容器
for container in $containers; do
echo "Deleting container: $container"
ctr -n k8s.io c rm "$container"
done
echo "All containers have been removed."
systemctl restart containerd
systemctl restart kubelet
#!/bin/bash
# 获取所有Exited状态的容器ID
exited_containers=$(crictl ps -a | grep Exited | grep months | awk '{print $1}')
# 检查是否有Exited容器需要删除
if [ -z "$exited_containers" ]; then
echo "没有找到任何处于Exited状态的容器。"
else
# 遍历所有Exited状态的容器ID,并删除它们
for container in $exited_containers; do
echo "正在删除容器: $container"
crictl rm $container
if [ $? -eq 0 ]; then
echo "容器 $container 已成功删除。"
else
echo "删除容器 $container 失败。"
fi
done
fi
问题的本质是 grpc 超标,我们是否可以直接改 grpc 的 received message
larger than max (4198720 vs. 4194304)
让我们看一下 containerd 的源码
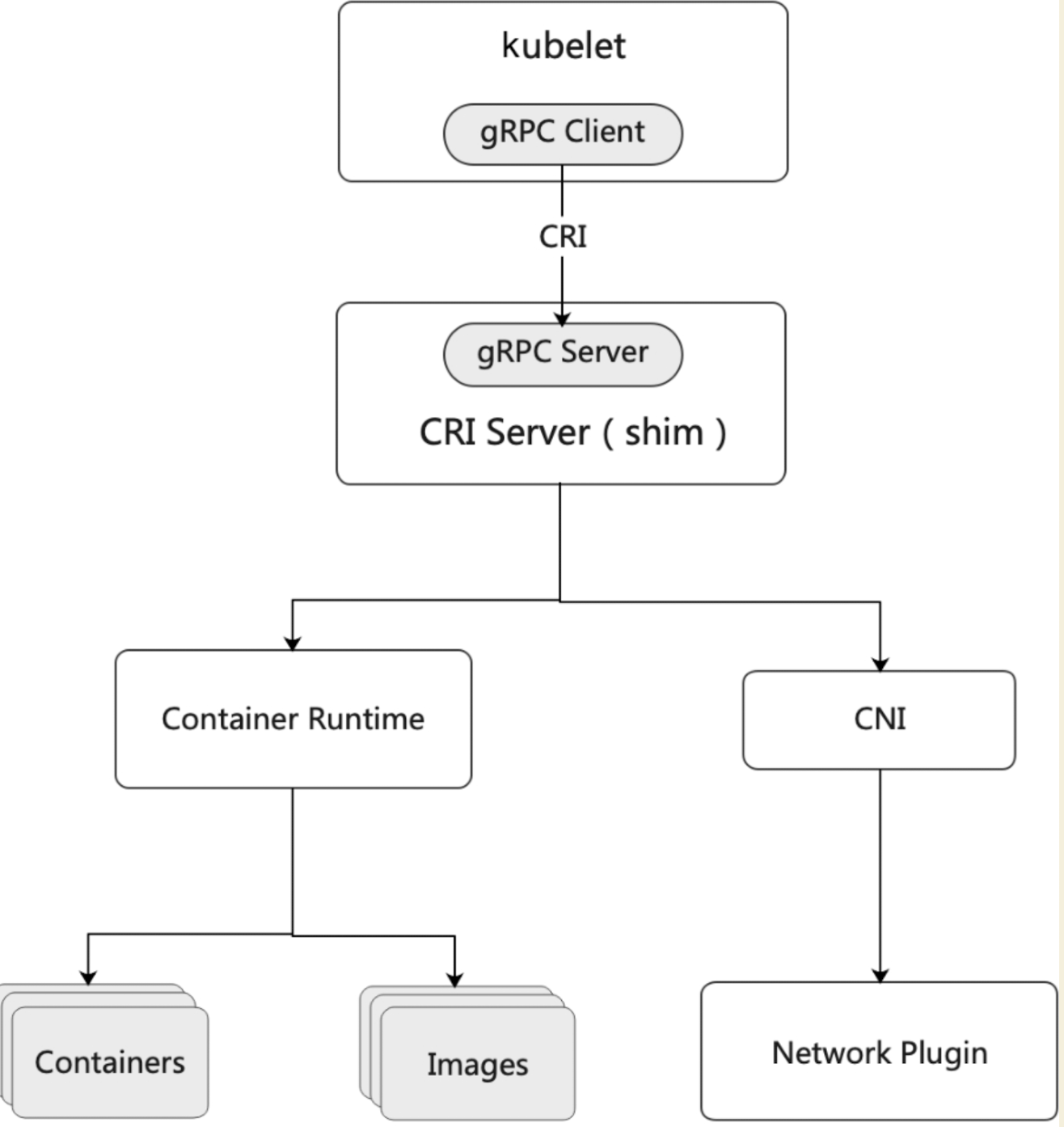
kubelet 与 cri server 交互 pkg/cri/server/sandbox_list.go:29
func (c *criService) ListPodSandbox(ctx context.Context, r *runtime.ListPodSandboxRequest) (*runtime.ListPodSandboxResponse, error)
pkg/cri/cri.go:100
s, err := server.NewCRIService(c, client)
client 是New返回一个新的containerd客户端,该客户端连接到地址提供的containerd实例,代码很简单,如果 address!="" 设置 grpc 大小为 16m,如果为空,grpc 大小为默认值 4m
// New returns a new containerd client that is connected to the containerd
// instance provided by address
func New(address string, opts ...ClientOpt) (*Client, error) {
// .......
c := &Client{
defaultns: copts.defaultns,
}
// .......
if address != "" {
// .......
gopts := []grpc.DialOption{
grpc.WithBlock(),
grpc.WithTransportCredentials(insecure.NewCredentials()),
grpc.FailOnNonTempDialError(true),
grpc.WithConnectParams(connParams),
grpc.WithContextDialer(dialer.ContextDialer),
grpc.WithReturnConnectionError(),
}
if len(copts.dialOptions) > 0 {
gopts = copts.dialOptions
}
// 设置 grpc 最大值 16m
gopts = append(gopts, grpc.WithDefaultCallOptions(
grpc.MaxCallRecvMsgSize(defaults.DefaultMaxRecvMsgSize),
grpc.MaxCallSendMsgSize(defaults.DefaultMaxSendMsgSize)))
//........
connector := func() (*grpc.ClientConn, error) {
ctx, cancel := context.WithTimeout(context.Background(), copts.timeout)
defer cancel()
conn, err := grpc.DialContext(ctx, dialer.DialAddress(address), gopts...)
if err != nil {
return nil, fmt.Errorf("failed to dial %q: %w", address, err)
}
return conn, nil
}
conn, err := connector()
if err != nil {
return nil, err
}
c.conn, c.connector = conn, connector
}
//........
return c, nil
}
但是在 pkg/cri/cri.go:62 初始化 cri 插件时,address 为空,grpc 大小为默认值 4m
client, err := containerd.New(
"",
containerd.WithDefaultNamespace(constants.K8sContainerdNamespace),
containerd.WithDefaultPlatform(platforms.Default()),
containerd.WithServices(servicesOpts...),
)
社区目前的方案就是设置 maximum-dead-containers 兜底
https://github.com/kubernetes/kubernetes/issues/63858
increase(problem_counter{app="ops.paas.npd",reason="lots of pods notReady"}[60m]) > 0
死亡容器保持一个不删,只是原因,后续发现sandbox 的 GC 速度很慢 (看日志 GC 一个sandbox 5s 左右)
removeSandBox 会调用 stopSandBox,if sandbox.NetNS != nil 会 teardownPodNetwork ,这里会和 cni 插件交互,因为 cni-adaptor 重复删除网络又报错,GC 就失败了,极大影响 GC 效率,后续需要对 cni 插件进行优化
cni 删除操作,因改为尽量删除
https://github.com/containernetworking/plugins/issues/210
vendor/github.com/containerd/go-cni/cni.go:234
// Remove removes the network config from the namespace
func (c *libcni) Remove(ctx context.Context, id string, path string, opts ...NamespaceOpts) error {
if err := c.Status(); err != nil {
return err
}
ns, err := newNamespace(id, path, opts...)
if err != nil {
return err
}
for _, network := range c.Networks() {
if err := network.Remove(ctx, ns); err != nil {
// Based on CNI spec v0.7.0, empty network namespace is allowed to
// do best effort cleanup. However, it is not handled consistently
// right now:
// https://github.com/containernetworking/plugins/issues/210
// TODO(random-liu): Remove the error handling when the issue is
// fixed and the CNI spec v0.6.0 support is deprecated.
// NOTE(claudiub): Some CNIs could return a "not found" error, which could mean that
// it was already deleted.
if (path == "" && strings.Contains(err.Error(), "no such file or directory")) || strings.Contains(err.Error(), "not found") {
continue
}
return err
}
}
return nil
}
热门资讯







