
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 本文将介绍如何使用Python语言中的smogn包,读取.csv格式的Excel表格文件,并实现SMOGN算法,用于解决机器学习和深度学习回归中的训练数据集不平衡问题。
在不平衡回归问题中,样本数量不均衡可能导致模型在预测较少类别的样本时表现较差。为了解决这个问题,可以使用SMOTE(Synthetic Minority Over-sampling Technique)算法或SMOGN(Synthetic Minority Over-Sampling Technique for Regression with Gaussian Noise)算法来生成合成样本以平衡数据集。
SMOTE算法的基本思想是通过对少数类样本进行插值,生成一些合成样本,从而增加少数类样本的数量。而SMOGN算法则在生成新样本的同时还增加了高斯噪声,并且可以同时进行过采样和欠采样。因此,SMOGN算法相较于SMOTE算法更为合理。
在Python中,我们可以使用第三方库smogn包来实现SMOGN算法。而SMOTE算法的实现相对较为复杂,需自行编写函数。鉴于SMOGN算法的合理性,本文将只介绍Python中SMOGN算法的实现。如果需要在R语言中实现这两种算法,可参考相关文章。
首先,我们需要配置需要的smogn包。在Anaconda Prompt中,选择指定的Python虚拟环境,输入代码"pip install smogn"安装smogn包,完成配置。
接下来,通过以下代码实现对不平衡数据的SMOGN算法操作。
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 11 13:56:36 2023
@author: fkxxgis
"""
import smogn
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv(r"E:\01_Reflectivity\99_Model_Training\00_Data\02_Extract_Data\26_Train_Model_New\Train_Model_0711.csv")
df_nona = df.dropna()
df_smogn = smogn.smoter(
data = df_nona,
y = "inf_dif",
k = 3)
plt.hist(df_nona["inf_dif"], bins = 50)
plt.hist(df_smogn["inf_dif"], bins = 50)
运行以上代码,即可开始实现SMOGN算法。由于数据量较大时程序运行较慢。
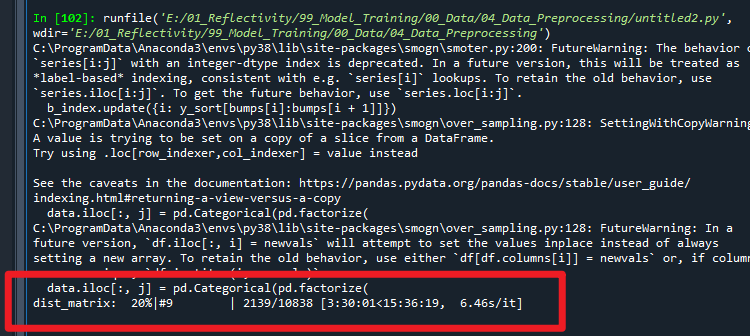
完成全部SMOGN算法需要6个进度条。下图展示了执行SMOGN算法前后的因变量直方图。
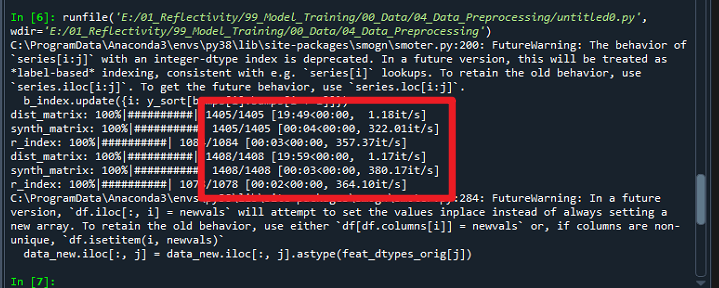
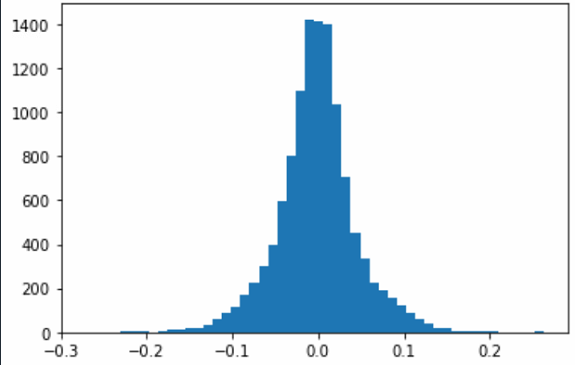
可以看到,使用SMOGN算法后,数据的少数部分略有增多;同时,数据原本的主要部分也有所增加。如果希望调整SMOGN算法的效果,可尝试修改smogn.smoter()函数的参数。
由于Python中SMOGN算法的实现速度较慢,本文建议使用R语言实现,速度快且效果好,还可同时实现SMOTE算法和SMOGN算法。具体实现方法可参考相关文章。
至此,大功告成。
热门资讯







