
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 看到二维码,很容易猜到黑白相间的小方格就是二进制比特。那么这些比特是怎么得到的?小方格又是按照什么规则排布的?今天咱们就从零开始将一个 url 画成二维码。
考虑到大多数人可能不太了解二维码,所以先讲下基础概念。你也可以先看看左耳朵耗子写的 二维码的生成细节和原理 。
二维码一共有 40 个尺寸,官方叫作版本 Version。最小的 Version 1 是 21 × 21 的矩阵,Version 2 是 25 × 25 的矩阵 … 每增加 1 version,就增加 4 的尺寸。最高是 177 × 177 的矩阵(Version 40)。
根据日常使用经验,无论是残缺、遮挡还是污损,二维码都能够被正确识别,这得益于二维码的纠错机制。

纠错是通过纠错码实现的,当我们将源数据编码后,会采用一种 纠错算法 算出编码结果对应的纠错码,连同编码结果一起填充到二维码。
规范里明确了四个纠错等级,不同等级的纠错比例不同。

每个版本的纠错码个数都是固定的,比如 version 1-L 需要 7 个纠错码,version 1-M 需要 10 个纠错码,版本越大、数据越多、等级越高,需要的纠错码就越多。
二维码可以简单划分为三个部分:固定的功能区(用于定位)、固定的格式信息区(比如二维码用的纠错等级和版本信息)、数据区。
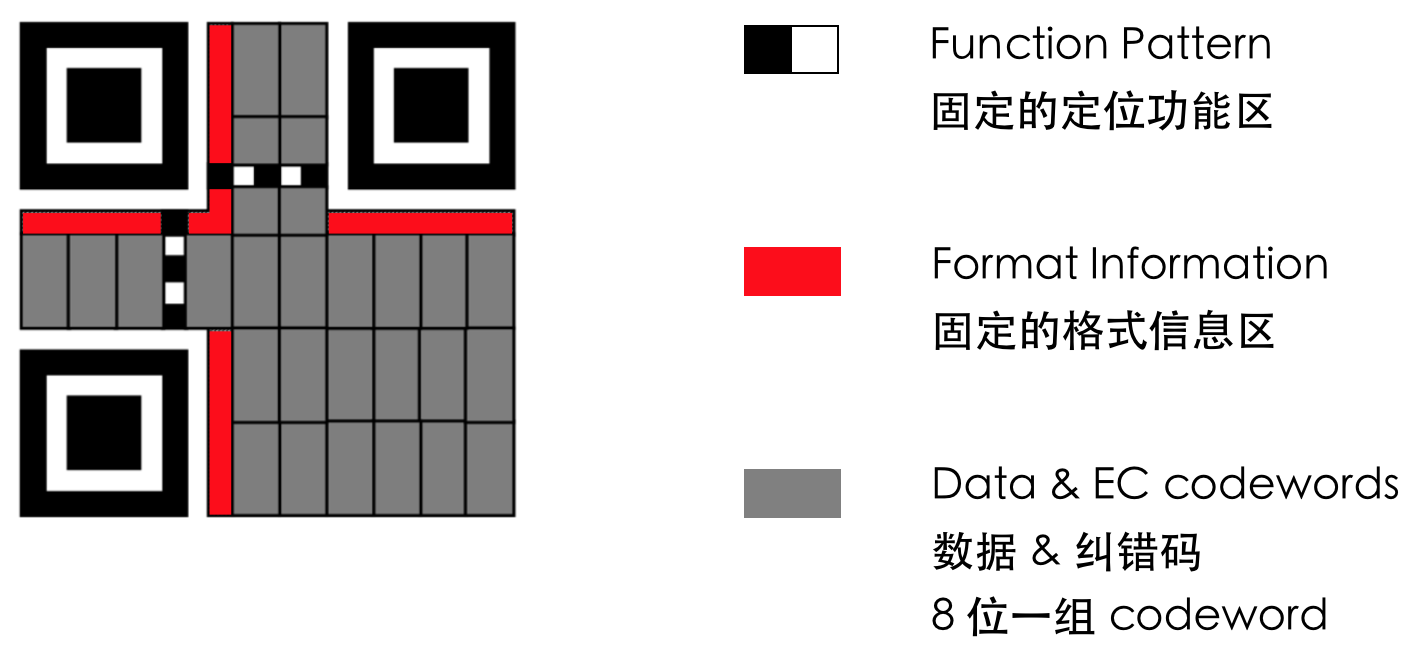
二进制数据都是严格按 8 位一组填入数据区的,每一组称为一个 codeword。如果数据区的格子数不是 8 的倍数,就会剩下留白(remainder)。每个版本的功能区、格式信息区和留白的位置及其占用的面积都是固定的。
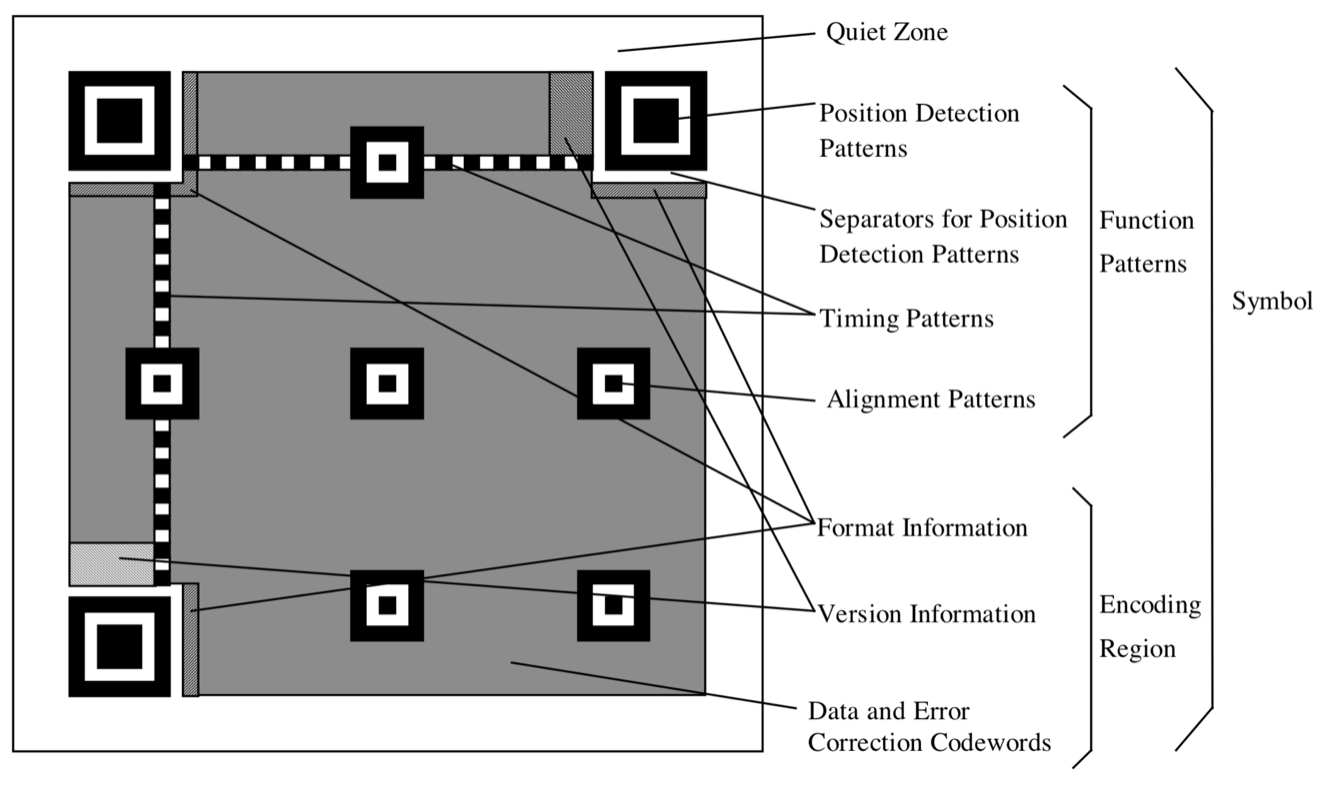
更详细的划分可以参考规范里的这张图:
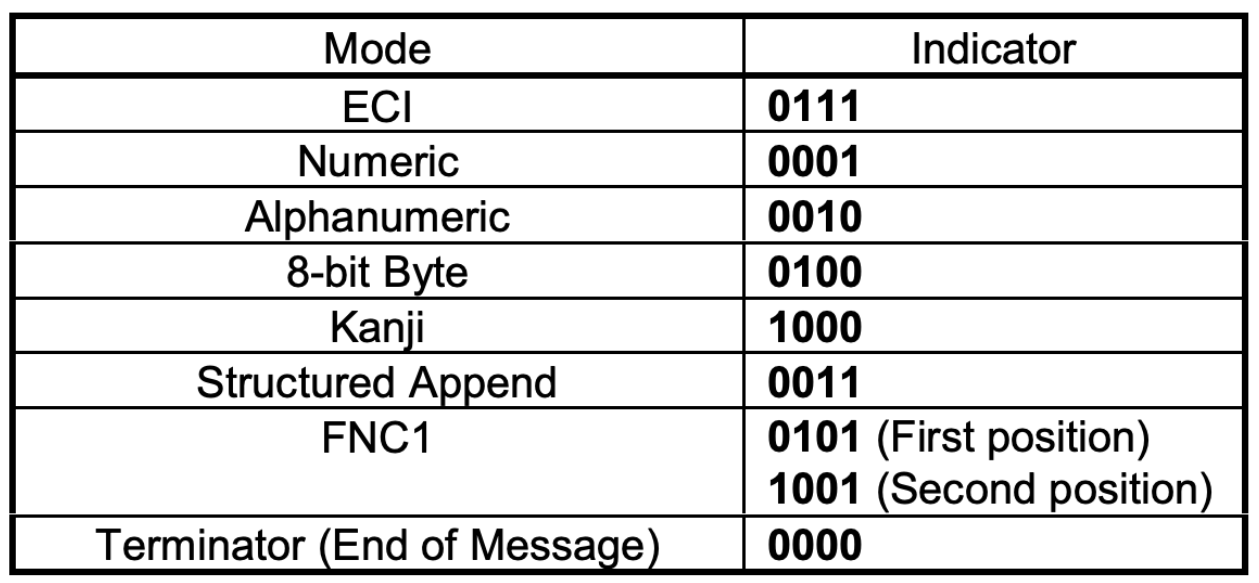
理论上凡是可以被编译为二进制的数据,都可以用二维码来表示,只要有相应的解码程序即可。规范里规定了几种国际通用的编码模式:
比如 Numeric 仅支持 0 ~ 9 的数字,它的编码规则是:将数据字符串拆分为每三个一组,每组作为一个十进制的百位数,然后转化为 10 位二进制。为什么是 10 位呢,因为 2^10 = 1024,恰好能覆盖最大的百位数 999。如果最后一组只有两位,则转化为 7 位二进制,如果只有一位,则转化为 4 位二进制。

Alphanumeric 支持 45 个字符,0 ~ 9、A ~ Z 和几个特殊字符。
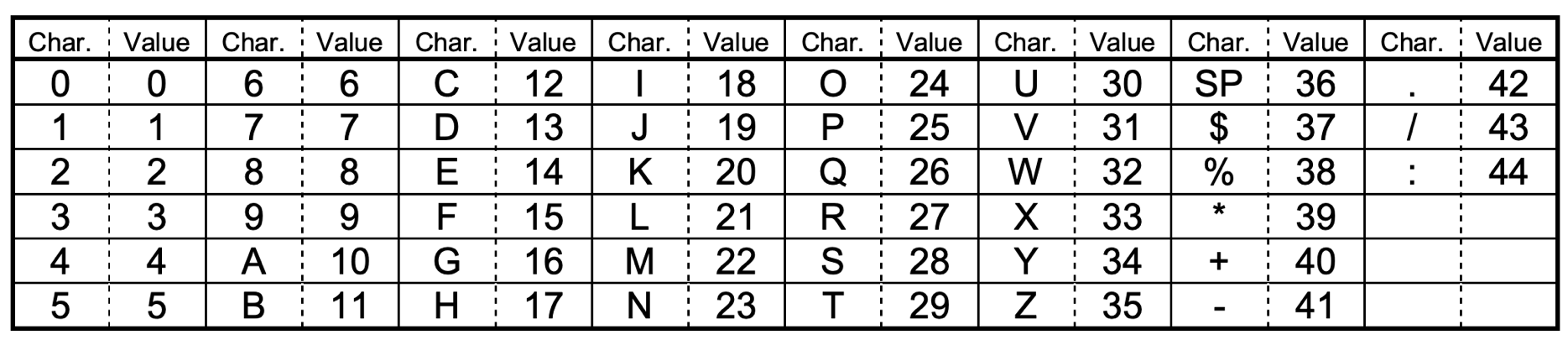
Alphanumeric 的编码规则是:根据上表查出每个 char 对应的 value,然后两两分组,按 A * 45 + B 算出一个值,并将这个值转化为 11 位二进制。如果最后一组只有一位,则将 value 转化为 6 位二进制。

Byte 模式的编码规则最简单,就是针对单字节字符集(例如 ISO-8859-1)的编码,每个字符恰好用 8 个比特表示。
我们还可以针对不同的数据片段采用不同的编码模式,这就是混合模式。

二维码包含的二进制串具体是由以下几个部分组成的:
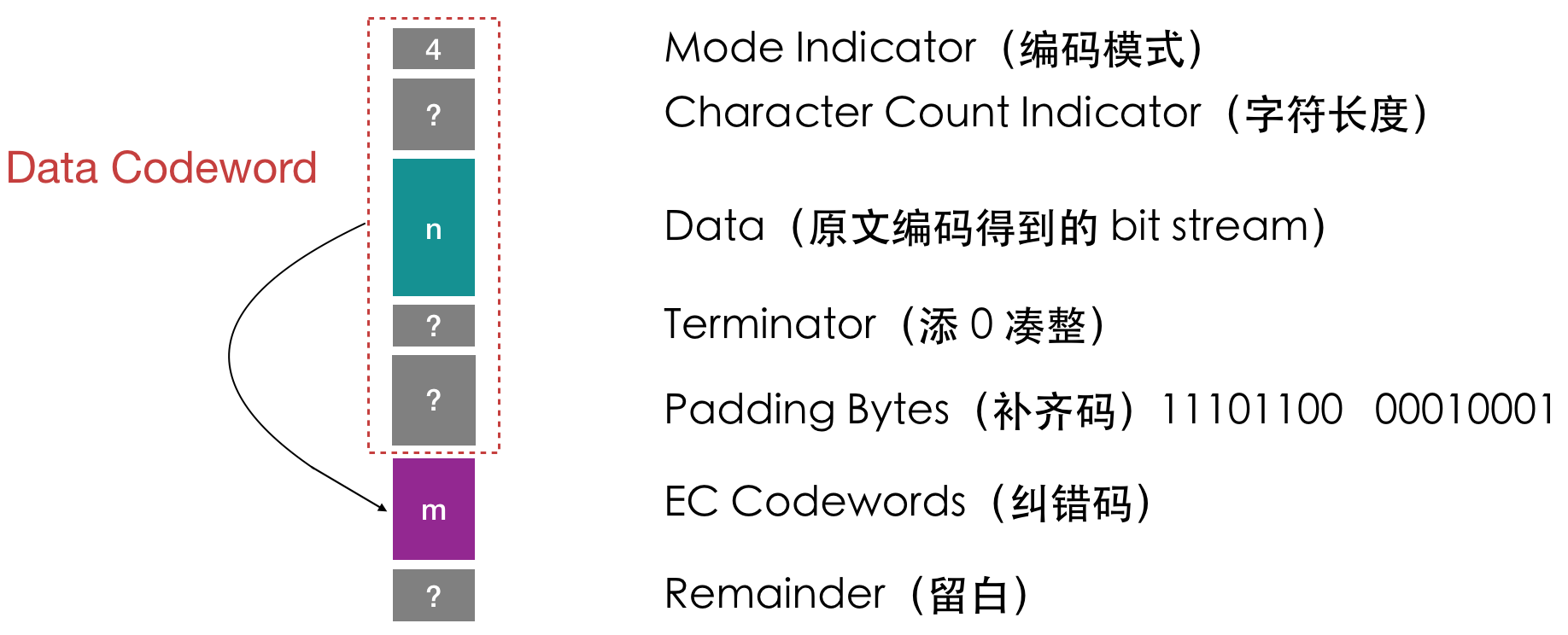
最开头一定是编码模式,是固定的 4 位(见编码一节的表格)。
接下来是原字符的长度,不同版本和不同编码模式用多少个比特表示长度是不一样的,具体是几个,规范里有明确的规定。毕竟二维码要在有限的空间里容纳更多的信息,就不能浪费比特,用过长的二进制去表示一个较小的值。
然后就是对数据按照指定的编码模式编译出的二进制序列。如果以上三部分的数据长度不是 8 的倍数,那么必须添零凑整(terminator)。
上述数据不见得能填满整个数据区,那么剩余的空间就用两个补齐码(11101100、00010001)交错填满。这两个补齐码是规范指定的。
以上整个比特串作为输入,用纠错算法输出特定个数的纠错码,二者相接,就是整个二维码数据区的数据了。
------------------ 分割线 ------------------
接下来,咱们就选用最小的版本,和最低的纠错等级,用 Alphanumeric 模式将 HTTP://I.MEITUAN.COM 这个字符串画成一个二维码。
查表可以得到每个字符对应的码点,然后两两分组,刚好分成 10 组:(17, 29)(29, 25)(44, 43)(43, 18)(42, 22)(14, 18)(29, 30)(10, 23)(42, 12)(24, 22)。
按照 A * 45 + B 算出:794, 1330, 2023, 1953, 1912, 648, 1335, 473, 1902, 1102。
然后将每个数字依次转化为二进制(toString(2)):01100011010 10100110010 11111100111 11110100001 11101111000 01010001000 10100110111 00111011001 11101101110 10001001110。
Alphanumeric 的 mode indicator 是 0010,在 version 1 里需要 9 个比特表示长度(20 => 000010100),将它们添加到头部:
0010 000010100
01100011010 10100110010 11111100111 11110100001 11101111000
01010001000 10100110111 00111011001 11101101110 10001001110。
按 8 位一组重排,添 0 凑整:00100000 10100011 00011010 10100110 01011111 10011111 11010000 11110111
10000101 00010001 01001101 11001110 11001111 01101110 10001001 110
00000
。
version 1-L 共有 26 个 codeword,其中有 7 个纠错码(error correction codeword),那么 data codeword 应该有 19 个,目前我们只有 16 个,因此剩下 3 个需要用补齐码凑足:00100000 10100011 00011010 10100110 01011111 10011111 11010000 11110111
10000101 00010001 01001101 11001110 11001111 01101110 10001001 11000000
11101100 00010001 11101100
。
然后算出 7 个纠错码:11010100 01110000 01110111 10010001 00101110 10010101 11001111。(我是用 node-qrcode 反算出来的,搞不懂那个纠错算法)。
最终我们得到了整个编码结果:

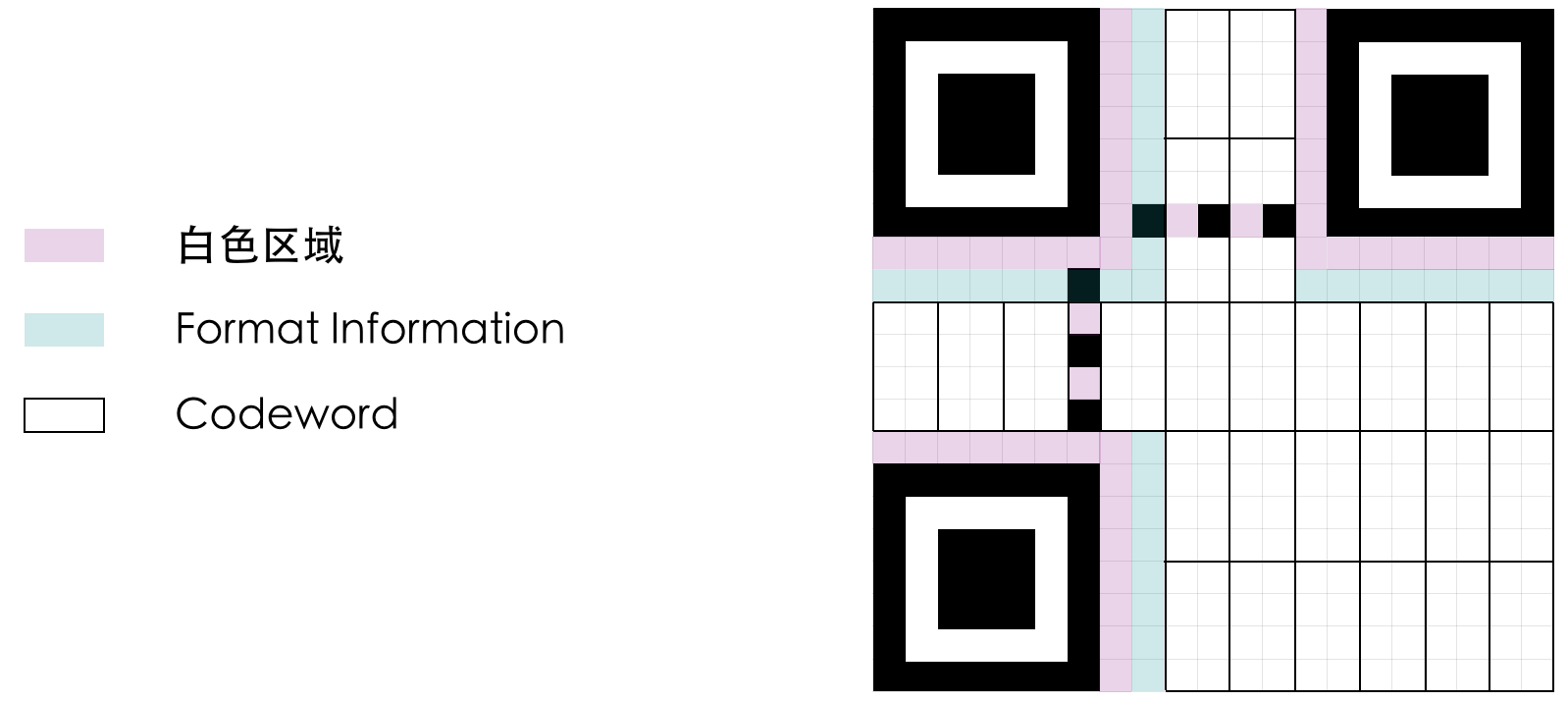
这一步最简单,按照规范里的规定画即可。为了便于区分,用淡紫色表示功能区的白色区域。
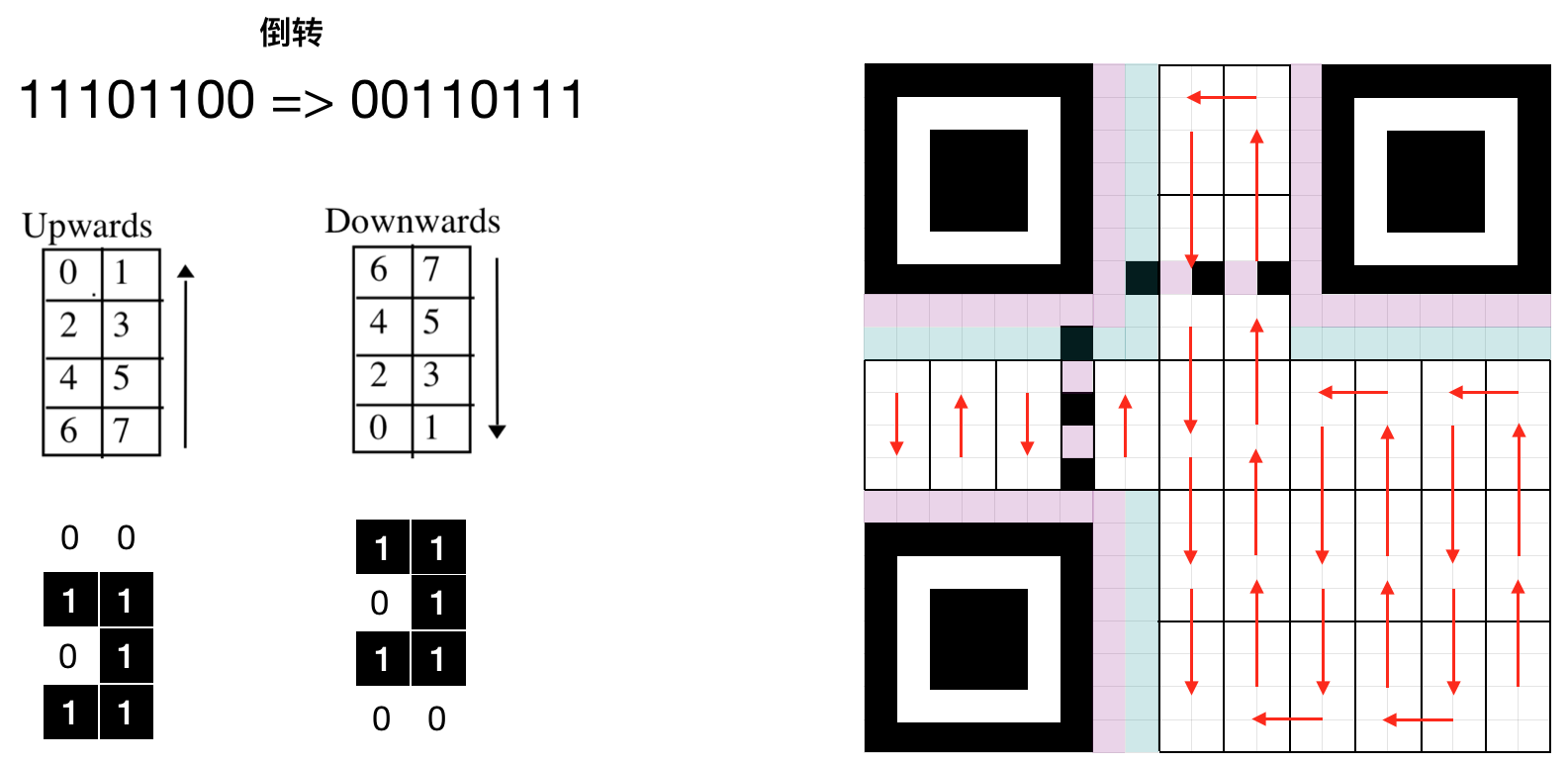
将数据按 8 位一组,从右下角开始蛇形往复填入 2 × 4 的矩形。具体怎么填规范里有明确规定,upwards 方向,将第一个数填入位置 7,第二个数填入位置 6 ... 这里是略有点坑的,因为不是从图中所示的 0 到 7,而是反过来的。方便起见,我们将数据倒过来,再按 0 ~ 7 的顺序依次填入。
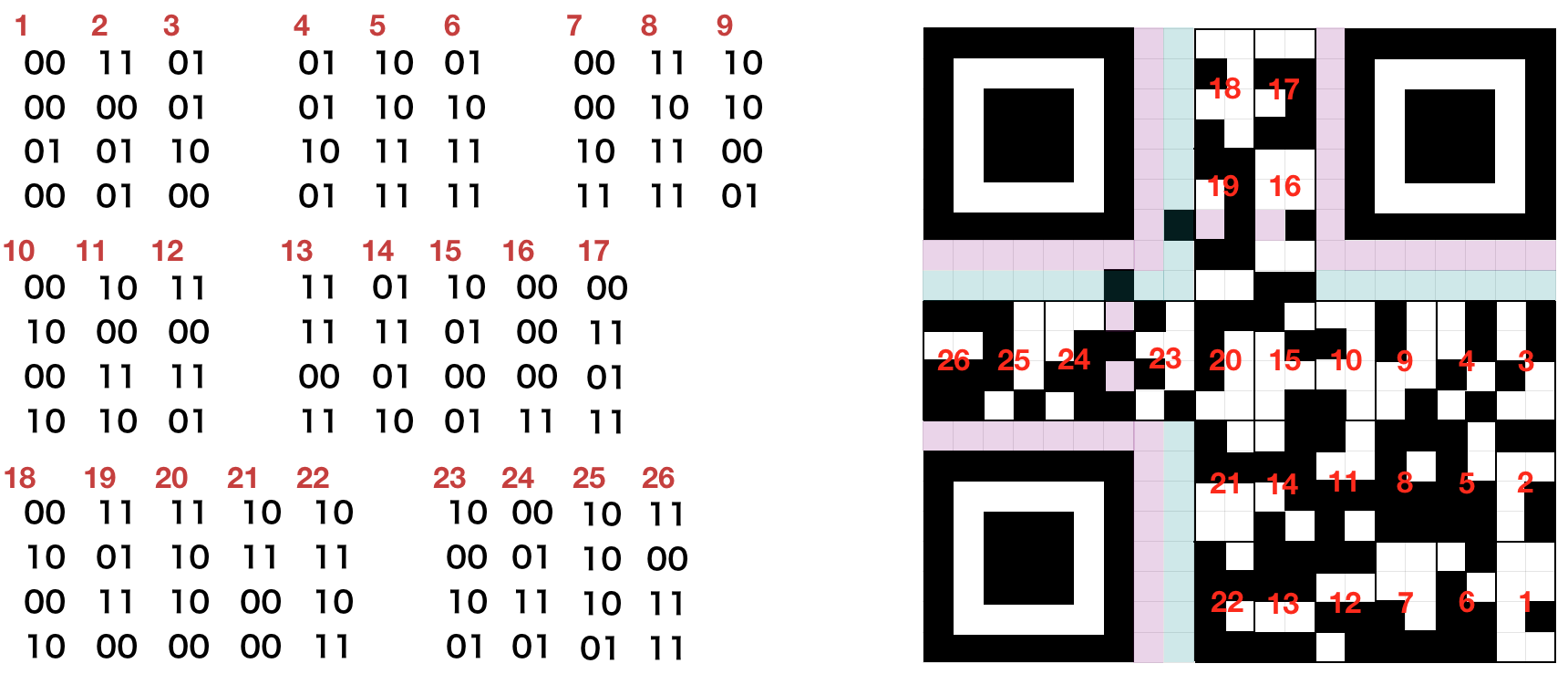
masking 的作用是使二维码的分布更加均匀。具体操作就是将数据区和 mask pattern 对应位置的比特做异或运算。比如数据区第 8 行第 10 列是白色 0,mask pattern 第 8 行第 10 列是黑色 1,异或运算的结果是黑色 1,那么就将数据区第 8 行第 10 列改成黑色。官方规定了八种 mask pattern(000 ~ 111),我们选用 000。



对所有的版本,格式信息都是固定的 15 位。其中两个是纠错等级,三个是 mask pattern,剩下十个是纠错码。
可以想象,没有格式信息,根本无法进行解码。因此格式信息非常重要,会重复画两次(类似于双机房备份)。
左下角那一列开头是永远固定的占位符。
格式信息也需要经历纠错码 + masking 的处理。
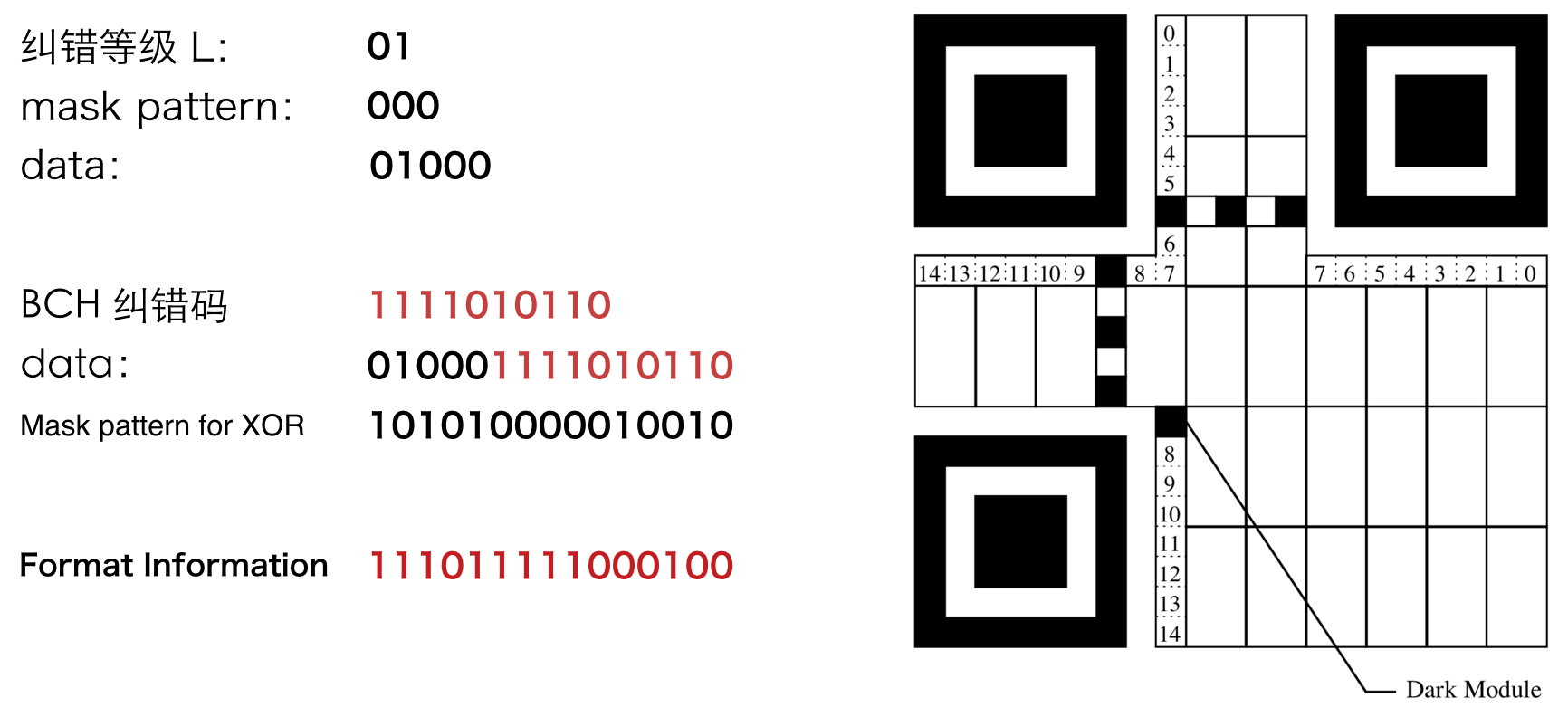
同样的,应该反过来,从位置 14 开始填。当然,也可以先把字符串倒过来。

最终结果:

————————————————————————————————————
本文写于 2019 年
热门资讯







