
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 数据一致性是指在整个系统或多个系统中,数据能够保持准确、可靠和同步的状态。在实时数据处理中,一致性包括数据的准确性、完整性、时效性和顺序性。
下图展示了典型的实时/流式数据处理的流程:
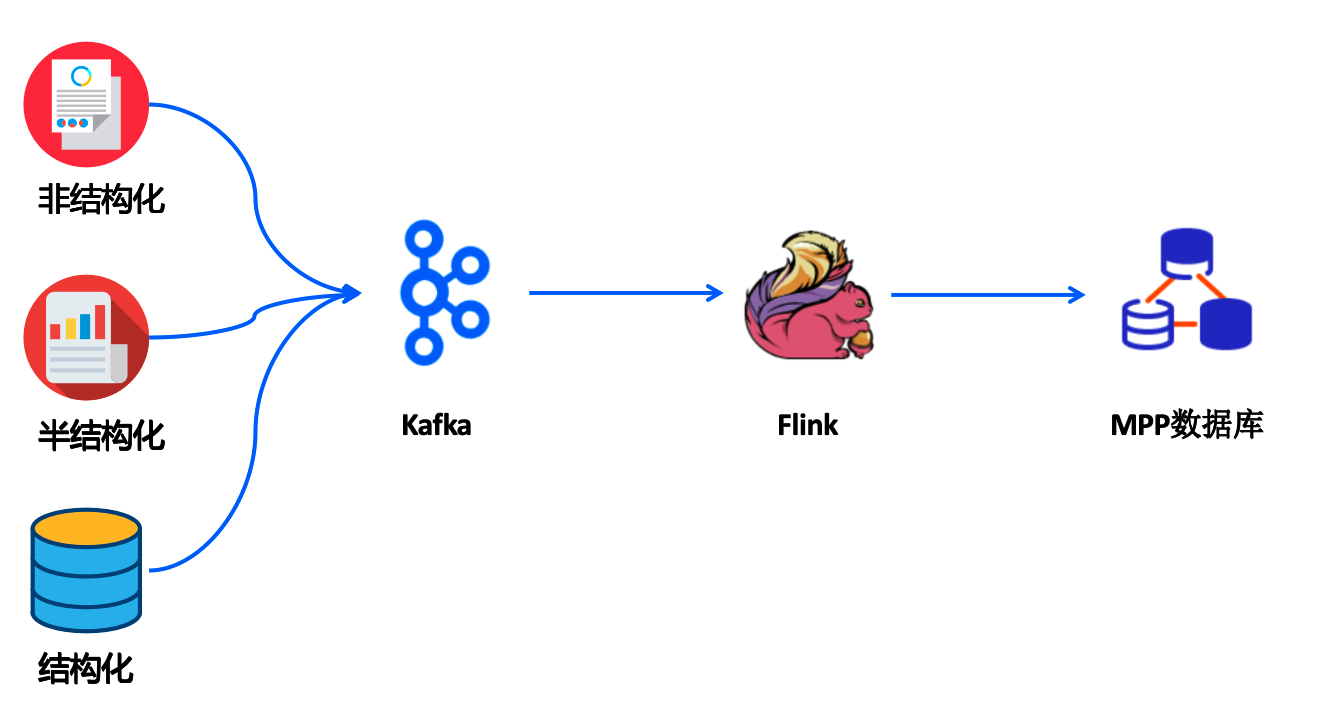
由于整个数据链条是动态变化,实时数据的一致性面临一些挑战。
高并发处理 :实时系统需要处理大量并发数据流,增加了一致性维护的难度。主要挑战在于分布式数据库端如何处理高并发的写入?
网络延迟和故障 :网络问题可能导致数据传输中断或延迟,影响数据同步。主要挑战在于数据处理过程中如何保障数据处理的一致性?
缓冲机制 :使用消息队列作为缓冲,平衡数据生产者和消费者之间的速度差异。
顺序保证 :确保消息按照发送顺序被处理。
数据重放(Data Replay)
状态恢复(State Recovery)
通过状态恢复和数据重放,Flink 确保即使在发生故障的情况下,也能保持数据处理的端到端一致性。并且Flink 提供了端到端的精确一次(exactly-once)处理语义,确保每条数据在系统中只被处理一次,即使在故障发生时也是如此。
故障处理流程
时间语义 :Flink 支持不同的时间语义(事件时间、处理时间和摄取时间),允许开发者根据业务需求处理数据的时效性问题。
水印机制 (Watermarks):Flink 使用水印来处理事件时间的数据流。水印是一种用于表示时间进度的机制,可以告诉 Flink 在特定时间之前的所有事件都已到达,可以进行处理。这允许系统处理乱序事件或延迟到达的数据。
窗口技术 :Flink 提供了多种窗口操作,如滚动窗口(tumbling windows)、滑动窗口(sliding windows)和会话窗口(session windows),这些窗口可以对数据进行分组并在指定的时间范围内聚合,从而处理数据到达的延迟。
状态管理 :Flink 允许操作符维护状态,即使数据延迟到达,也可以在状态中保留必要的信息,直到数据真正到达时再进行处理。
允许乱序和延迟的 API
:Flink 提供了
allowedLateness
参数,允许在窗口操作中指定一定的延迟容忍度,窗口会为延迟数据保留状态,直到延迟数据到达后进行处理。
分布式数据库在设计的时候会考虑高并发情况下保持数据一致性的策略,主要有使用事务管理,数据分区分片,数据版本控制,以及采用最终一致性原理。
使用事务管理 :MPP数据库一般会提供ACID事务属性,确保事务具有原子性、一致性、隔离性和持久性,另外在分布式系统中支持分布式事务,使用两阶段提交等协议来维护事务一致性。
数据分区分片 :将数据分布到不同的分区或分片上,减少单个节点的负载,提高并发处理能力。数据分区分片时采用一致性哈希算法来分配数据到不同的节点,即使在节点增减的情况下也能保持数据分布的一致性。
数据版本控制 :当多个事务或操作可能同时对同一数据进行修改时,数据版本控制可以确保数据库的一致性和完整性。另外,数据版本控制可以实现多版本并发控制(MVCC),允许在不锁定资源的情况下执行读取和写入操作,从而提高系统的并发性能。在分布式系统中,不同节点可能会对同一数据产生冲突的更新,版本控制机制可以帮助识别和解决这些冲突。
采用最终一致性模型 :大部分分布式数据库采用CAP定理,接受短暂的数据不一致,最终一致性。
在实时数据处理流程中,从技术架构的设计到数据处理引擎的实现,再到分布式数据库在面对高并发、系统故障和网络异常等挑战时确保数据一致性的机制,都需要开发人员在开发和部署阶段进行精心的规划和应用。通过合理利用这些功能,可以有效地维护数据的完整性和一致性。
注:分布式数据库的设计和操作深受CAP定理的影响,该定理指出在分布式系统中,以下三个特性不可能同时得到完全满足:
一致性(Consistency):在分布式系统中的所有数据副本上,对于任何更新操作,都能保证所有节点在同一时间看到最新的数据。
可用性(Availability):每个请求接收到一个响应,无论是成功还是失败的响应。
分区容错性(Partition Tolerance):在网络分区(即系统的一部分被网络故障隔离)发生的情况下,系统仍然能够继续运行。
在CAP定理的框架下,分布式数据库需要在这三个特性之间做出权衡:
强一致性与可用性的权衡:如果一个分布式数据库优先考虑一致性,那么在更新数据时可能需要锁定相关的数据副本,直到所有副本都更新完毕。这可能会降低系统的可用性,因为在更新过程中,其他操作可能需要等待。
最终一致性:在这种模型下,分布式数据库接受在数据更新后的短时间内数据可能不一致,但保证系统最终会达到一个数据一致的状态。这种模型通常通过版本控制、数据版本控制、冲突解决策略等技术实现,允许系统在更新过程中继续处理请求,但返回的数据可能是旧版本。
分区容错性:对于分布式数据库来说,网络分区是一种常见情况,因此数据库需要设计为即使在分区发生时也能继续提供服务。这通常意味着牺牲一定程度的一致性或可用性,例如,通过使用最终一致性模型来保证系统的持续运行。
在实际应用中,分布式数据库可能采用以下策略来实现CAP定理中的权衡:
数据副本和同步策略:选择合适的数据副本数量和同步方式,以平衡一致性和可用性。
读写分离:通过分离读操作和写操作,可以在保持高可用性的同时,通过异步复制机制逐步达到数据一致性。
冲突解决机制:在检测到数据冲突时,使用预定义的策略来解决冲突,如“最后写入胜出”或基于特定业务逻辑的自定义策略。
智能路由和负载均衡:在网络分区发生时,智能地路由请求到可用的节点,并在后台同步数据,以保持系统的可用性和一致性。
使用不同的一致性模型:根据业务需求,选择强一致性、最终一致性或其他一致性模型,以适应不同的应用场景。
最终,分布式数据库的设计者和运维人员需要根据具体的业务需求、系统特点和预期的工作负载来决定如何在CAP定理的三个特性之间做出最佳权衡。
热门资讯







