
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 大语言模型的发展日新月异。在去年的这个时候,函数调用还是gpt-4的专属功能。到今年,本地运行的大模型无论是推理能力还是文本输出质量都已经非常接近gpt-4了。在去年,gpt-4尚未发布函数调用时,智能体框架的开发者们依赖构建精巧的提示词实现了gpt-3.5的函数调用。目前,本机运行的大模型可以通过这一套逻辑实现函数式调用。从测试的效果来看,本地大模型对于简单的函数调用成功率已经非常高了。但受限于本地机器的性能,调用的时间还是比较长。如果有NVIDIA显卡的CUDA环境,质量应该会更好。今天我们以大家都比较熟悉的LLAMA生态作为起点,基于阿里云开源的千问7B模型的量化版作为基座通过C#和SemanticKernel来实现函数调用的功能。
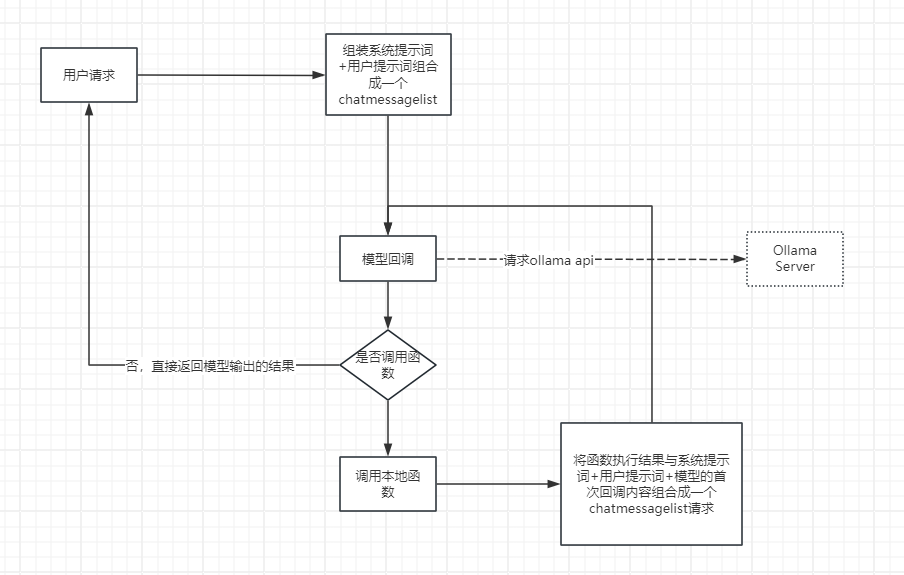
基本调用逻辑参考这张图:
首先我们需要在本机(Windows系统)安装Ollama作为LLM的API后端。访问https://ollama.com/,选择Download。选择你需要的版本即可,Windows用户请选择Download for Windows。下载完成后,无脑点击下一步下一步即可安装完毕。
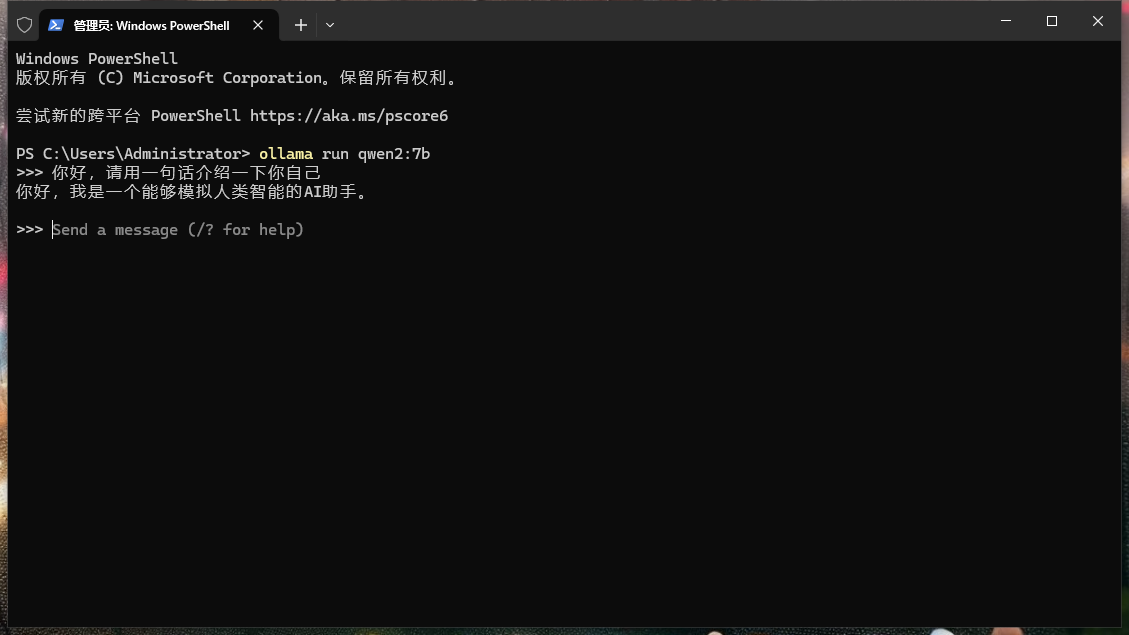
安装完毕后,打开我们的PowerShell即可运行大模型,第一次加载会下载模型文件到本地磁盘,会比较慢。运行起来后就可以通过控制台和模型进行简单的对话,这里我们以阿里发布的千问2:7b为例。执行以下命令即可运行起来:
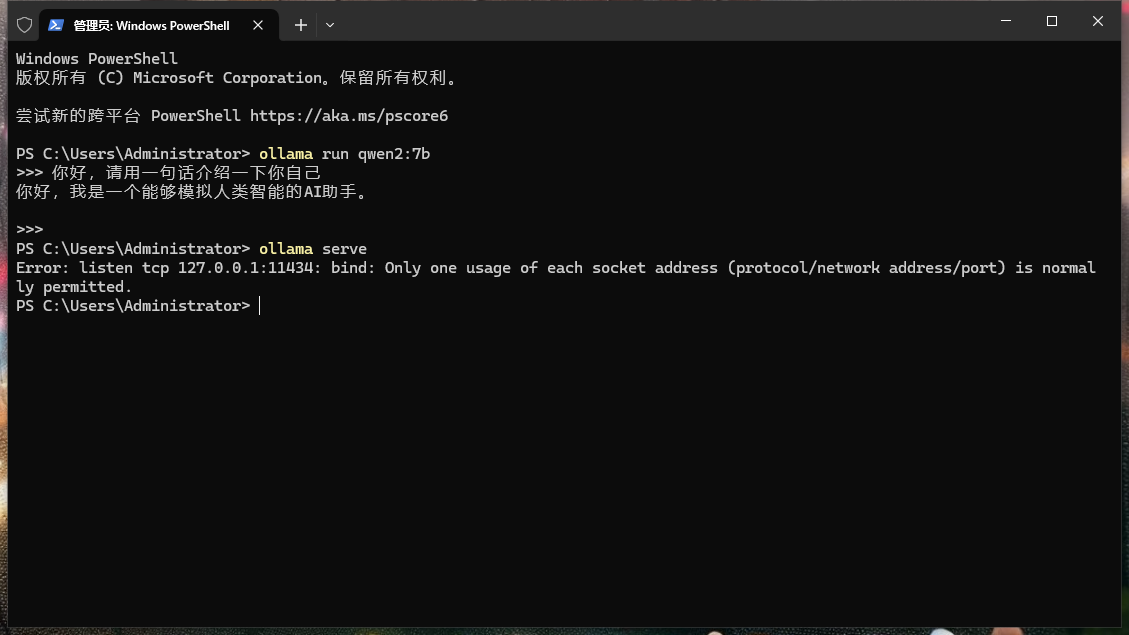
接着我们使用ctrl+D退出对话框,并执行ollama serve,看看服务器是否运行起来了,正常情况下会看到11434这个端口已经运行起来了。接下来我们就可以进入到编码阶段。
首先我们创建一个.NET 8.0的控制台,接着我们引入三个必要的包。
SemanticKernel是我们主要的代理运行框架,OllamaSharp是一个面向Ollama本地API服务的请求封装。我们还安装了Newtonsoft.Json来替代system.text.json,用于后期需要一些序列化模型回调来使用,因为模型的回调JSON可能不是特别标准,使用system.text.json容易导致转义失败。
接下来就是编码阶段,首先我们定义一个函数,这个函数是后面LLM会用到的函数,简单的定义如下:
这里的KernelFunction和Description特性都是必要的,用于SemanticKernel查询到对应的函数并封装处对应的元数据。
接着我们需要自定义一个继承自接口IChatCompletionService的实现。因为SemanticKernel是基于OpenAI的GPT系列设计的框架,所以要和本地模型调用,我们需要设置独立的ChatCompletionService来让SemanticKernel和本机模型API交互。这里我们主要需要实现的函数是GetChatMessageContentsAsync。因为函数调用需要接收到模型完整的回调用于转换JSON,所以流式传输这里用不上。
接下来我们需要定义一个SemanticKernel的实例,这个实例会伴随本次调用贯穿全程。SemanticKernel使用了简单的链式构建。基本代码如下:
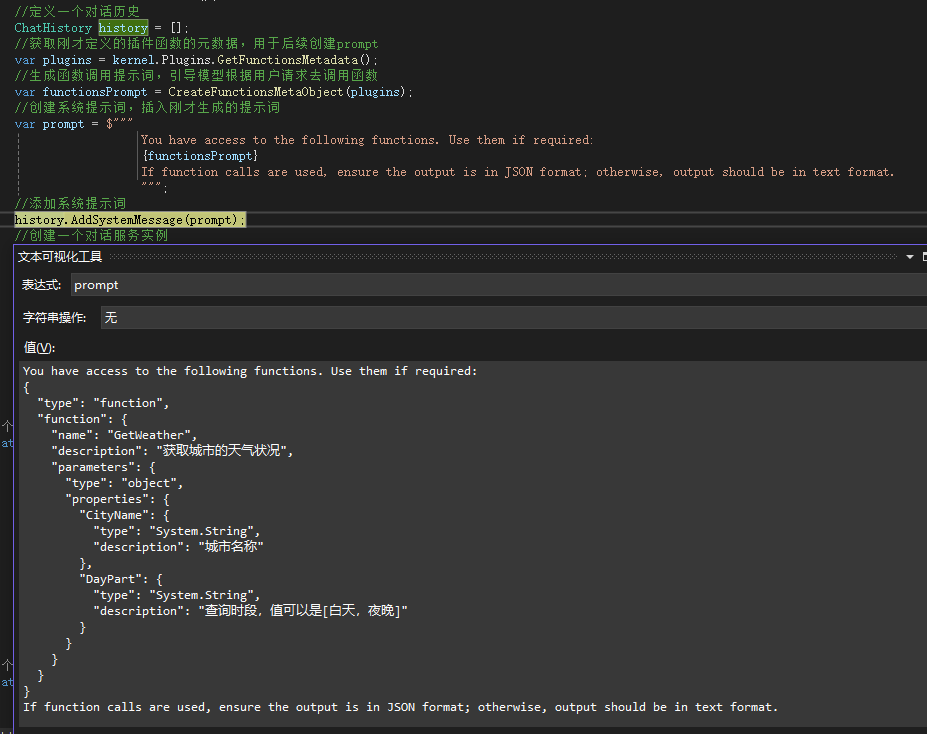
可以看到基本的构建链式调用代码部分还是比较简单的,接下来就是调用的部分。这里主要的部分就是将LLM可用的函数插入到系统提示词,来引导LLM去调用特定函数:
在这里我们可以debug看看生成的系统提示词细节:
当代码执行到GetChatMessageContentAsync这里时,就会跳转到我们的CustomChatCompletionService的GetChatMessageContentsAsync函数。在这里我们需要进行ollama的调用来达成目的。
这里比较核心的部分就是将LLM回调的内容使用JSON序列化来检测是否涉及到函数调用。由于类似qwen这样没有专门针对function calling专项微调过的(glm-4-9b原生支持function calling)模型,其function calling并不是每次都能准确的回调。所以这里我们需要对回调的内容进行反序列化和信息抽取,确保模型的调用符合回调函数的格式标准。具体代码如下:
这里我们首先使用SemanticKernel的kernel的函数元数据通过GetDicSearchResult构建了一个字典。
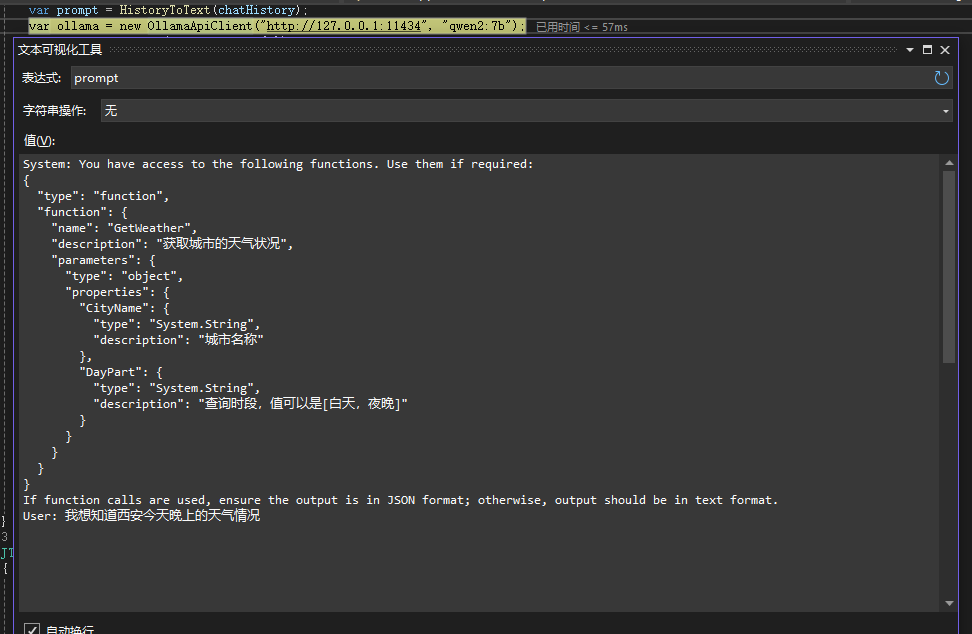
接着使用HistoryToText将历史对话信息组装成一个单一的prompt发送给模型,大概会组装成如下内容,其实就是系统提示词+用户提示词组合成一个单一文本:
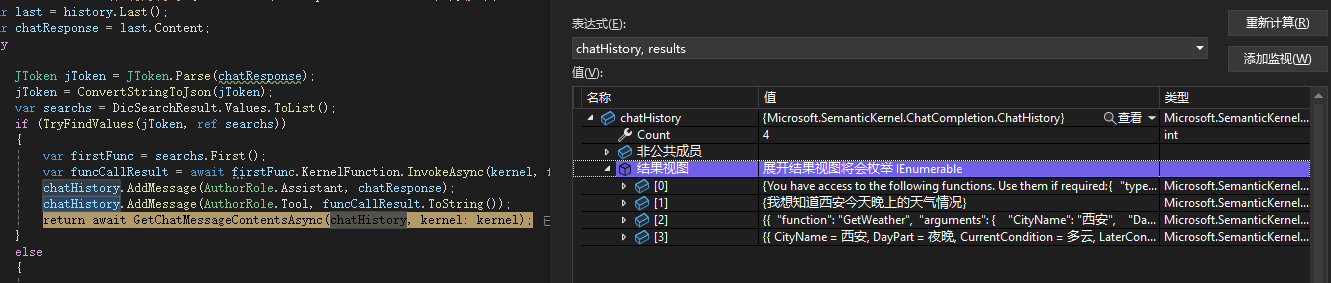
接着我们使用OllamaSharp的SDK提供的OllamaApiClient发送信息给模型,等待模型回调后,从模型回调的内容中抽取chatResponse。接着我们需要通过一个try catch来处理,当chatResponse可以被正确的解析成标准JToken后,说明模型的回调是一段JSON,否则会抛出异常,代表模型输出的是一段文本。如果是文本,我们就直接返回模型输出的内容,如果是JSON则继续向下处理,通过一个TryFindValues函数从模型中抽取我们所需要的回调函数名、参数,并赋值到一个临时变量中。最后通过SemanticKernel的KernelFunction的InvokeAsync进行真正的函数调用,获取到函数的回调内容,接着我们需要将模型的原始输出和回调内容一同添加到chatHistory后,再度递归发起GetChatMessageContentsAsync调用,这一次模型就会拿到前一次回调的城市天气内容来进行回答了。
第二次回调前的prompt如下,可以看到模型的输出虽然是JSON,但是并没有规范的格式。不过使用我们的抽取函数还是获取到了需要的信息,从而正确的构建了底部的回调:
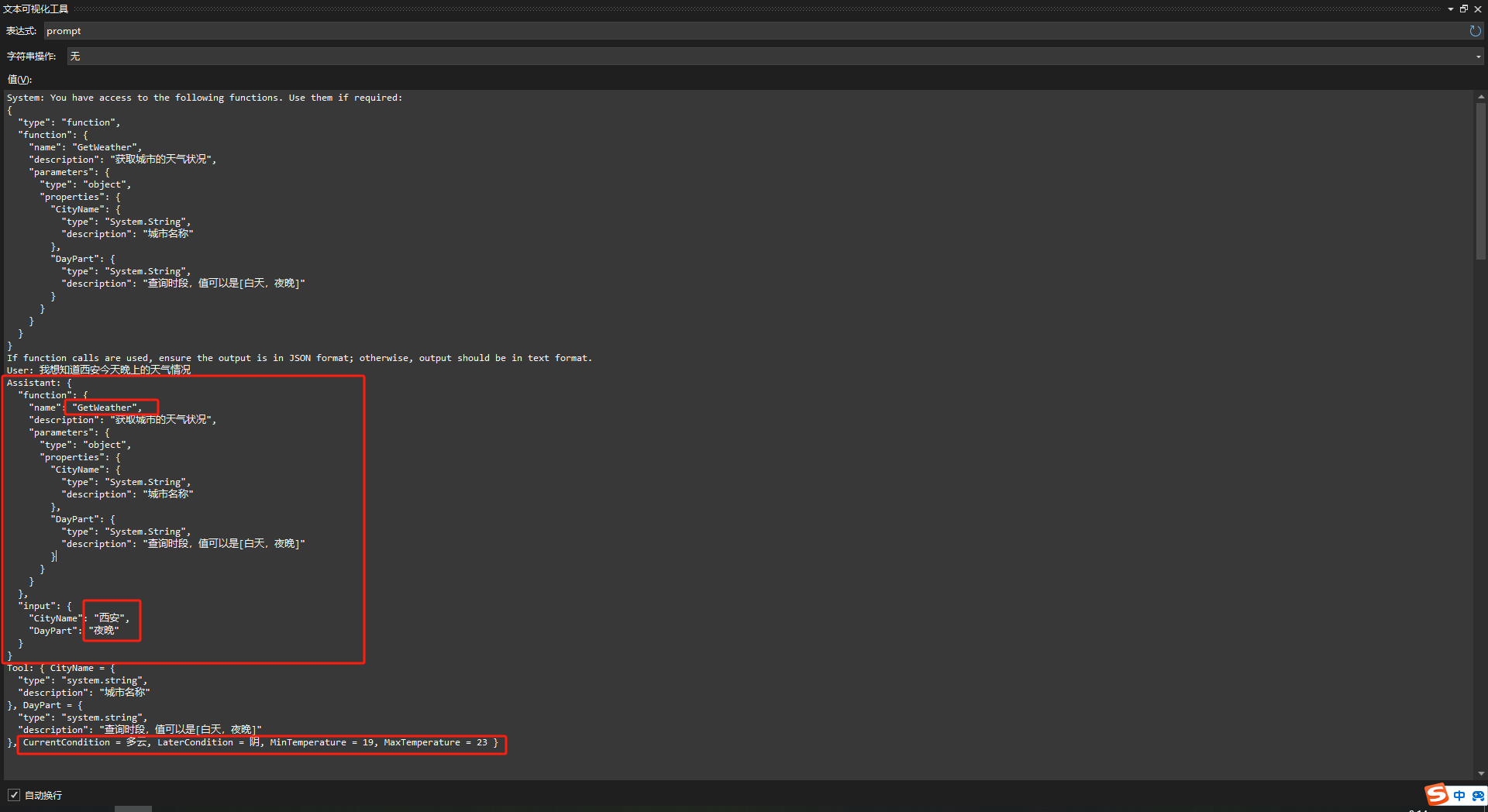
通过这一轮回调再次喂给LLM,LLM就可以正确的输出结果了:
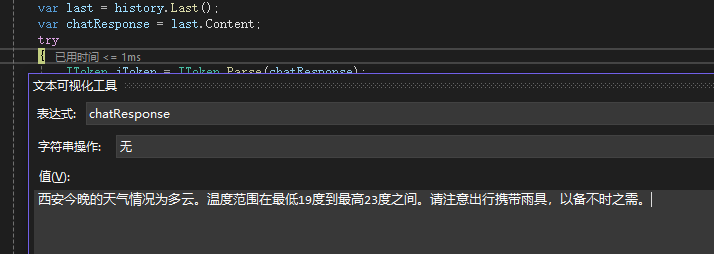
以上就是整个文章的内容了。可以看到在这个过程中我们主要做的工作就是通过系统提示词诱导模型输出回调函数JSON,解析JSON获取参数,调用本地的函数后再次回调给模型。这个过程其实有点类似的RAG,只不过RAG是通过用户的提示词直接进行近似度搜索获取到近似度相关的文本组合到系统提示词,而函数调用给了模型更大的自由度,可以让模型自行决策是否调用函数,从而使本地Agent代理可以实现诸如帮你操控电脑、打印文件、编写邮件等等助手性质的功能。
下面是核心部分的代码,请大家自取:
program.cs:
CustomChatCompletionService.cs:
热门资讯







