
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 今天来讲一下损失函数——交叉熵函数,什么是损失函数呢?大体就是真实与预测之间的差异,这个交叉熵(Cross Entropy)是Shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。在信息论中,交叉熵是表示两个概率分布 p,q 的差异,其中 p 表示真实分布,q 表示预测分布,那么 \(H(p,q)\) 就称为交叉熵:
\(H(p,q) = -\sum_{i=0}^n p(i)ln^{q(i)}\)
交叉熵是一种常用的损失函数,特别适用于神经网络训练中。在这种函数中,我们用 p 来表示真实标记的分布,用 q 来表示经过训练后模型预测的标记分布。通过交叉熵损失函数,我们可以有效地衡量模型预测分布 q 与真实分布 p 之间的相似性。
交叉熵函数是逻辑回归(即分类问题)中常用的一种损失函数。
有些同学和我一样,长时间没有接触数学,已经完全忘记了。除了基本的加减乘除之外,对于交叉熵函数中的一些基本概念,他们可能只记得和符号。今天我会和大家一起回顾一下,然后再详细解释交叉熵函数。首先,我们来简单了解一下指数和对数的基本概念。
\(x^3\) 是一个典型的立方函数,大家对平方和立方可能都有所了解。指数级增长的函数具有特定的增长规律,让我们更深入地记忆和理解它们的分布特性。
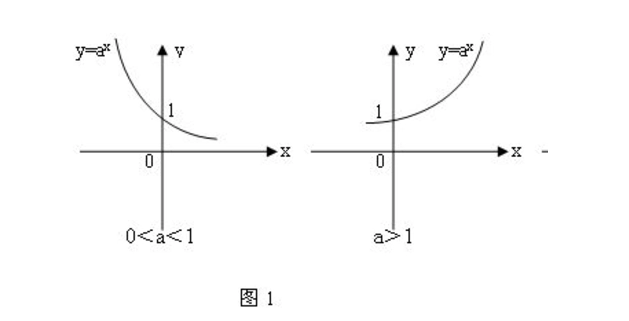
这个概念非常简单,无需举例子来说明。重要的是要记住一个关键点:指数函数的一个特殊性质是它们都经过点(0,1),这意味着任何数的0次幂都等于1。
好的,铺垫已经完成了。现在让我们继续探讨对数函数的概念。前面讲解了指数函数,对数函数则是指数函数的逆运算。如果有一个指数函数表达式为 \(y = a^x\) ,那么它的对数表达式就是 \(x = \log_a y\) 。为了方便表示,我们通常将左侧的结果记为 \(y\) ,右侧的未知函数记为 \(x\) ,因此对数函数最终表示为 \(y = \log_a x\) 。为了更加深刻地记忆这一点,让我们看一下它的分布图例。
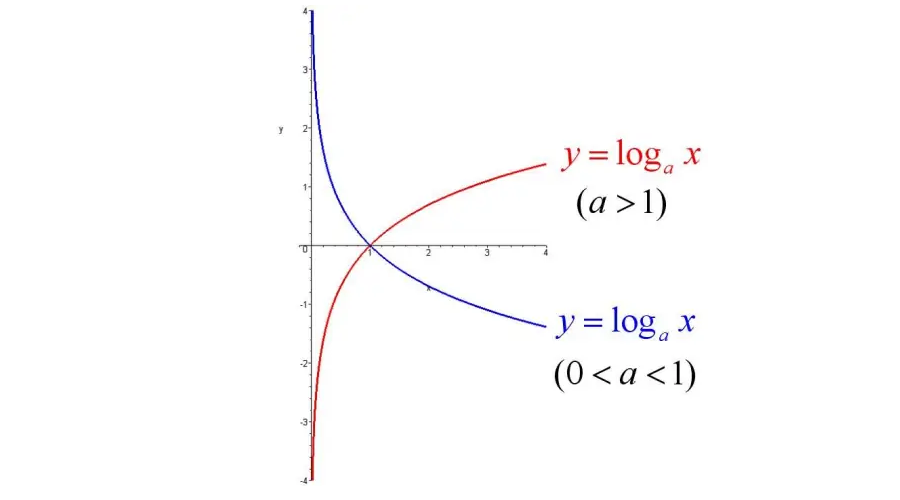
当讨论指数函数时,我们了解到其图像在( (0,1) ) 处穿过横轴。然而,当我们转而讨论对数函数时,其表示形式导致了这一点被调换至( (1,0) ),因此对于对数函数而言,它的恒过点即为( (1,0) )。
剩下关于对数的变换我就不再详细讲解了。现在让我们深入探讨一下熵的概念。
在探讨交叉熵之前,我们先来了解一下熵的概念。熵是根据已知的实际概率计算信息量的度量,那么信息量又是什么呢?
信息论中,信息量的表示方式: \(I(x_j) = -ln^{(px_j)}\)
\(x_j\) :表示一个事件。
\(px_j\) :表示一个事件发生的概率。
\(-ln^{(px_j)}\) :表示某一个事件发生后会有多大的信息量,概率越低,所发生的信息量也就越大。
这里为了更好地说明,我来举个例子。比如说有些人非常喜欢追星。那么,按照一般的逻辑来说,我们可以谈谈明星结婚这件事的概率分布:
| 事件编号 | 事件 | 概率p | 信息量 I |
|---|---|---|---|
| \(x_1\) | 两口子都在为事业奋斗照顾家庭 | 0.7 | \(I(x_1) = -ln^{0.7}= 0.36\) |
| \(x_2\) | 两口子吵架 | 0.2 | \(I(x_2) = -ln^{0.2}= 1.61\) |
| \(x_3\) | 离婚了 | 0.1 | \(I(x_3) = -ln^{0.1}= 2.30\) |
从上面的例子可以看出,如果一个事件的概率很低,那么它所带来的信息量就会很大。比如,某某明星又离婚了!这个消息的信息量就非常大。相比之下,“奋斗”事件的信息量就显得小多了。
按照熵的公式进行计算,那么这个故事的熵即为:
熵: \(H(p) = -\sum_j^n(px_j)ln^{(px_j)}\)
计算得出: \(H(p) = -[(px_1)ln^{(px_1)}+(px_2)ln^{(px_2)}+(px_3)ln^{(px_3)}] = -[0.7*0.36+0.2*1.61+0.1*2.3] = 0.804\)
上面我们讨论了熵的概念及其应用,熵仅考虑了真实概率分布。然而,我们的损失函数需要考虑真实概率分布与预测概率分布之间的差异。因此,我们需要进一步研究相对熵(KL散度),其计算公式为:
\(H(p) = \sum_j^n(px_j)ln^{(px_j) \over (qx_j)}\)
哎,这其实就是在原先的公式中加了一个 \(q(x_j)\) 而已。对了,这里的 \(q(x_j)\) 指的是加上了预测概率分布 \(q\) 。我们知道对数函数的对称点是(1,0)。因此,很容易推断出,当真实分布 \(p\) 和预测分布 \(q\) 越接近时,KL散度 \(D\) 的值就越小。当它们完全相等时,KL散度恒为0,即在点(1,0)。这样一来,我们就能够准确地衡量真实值与预测值之间的差异分布了。但是没有任何一个损失函数是能为0 的。
当谈到相对熵已经足够时,为何需要进一步讨论交叉熵呢?让我们继续深入探讨这个问题。
重头戏来了,我们继续看下相对熵函数的表达式: \(H(p) = \sum_j^n(px_j)ln^{(px_j) \over (qx_j)}\)
这里注意下, \(log^{p \over q}\) 是可以变换的,也就是说 \(log^{p \over q}\) = \(log^p -log^ q\) ,这么说,相对熵转换后的公式就是:$H(p) = \sum_j n(px_j)ln - \sum_j n(px_j)ln = -H(p) + H(p,q) $
当我们考虑到 \(H(p)\) 在处理不同分布时并没有太大作用时,这是因为 \(p\) 的熵始终保持不变,它是由真实的概率分布计算得出的。因此,损失函数只需专注于后半部分 \(H(p,q)\) 即可。
所以最终的交叉熵函数为: \(-\sum_j^n(px_j)ln^{(qx_j)}\)
这里需要注意的是,上面显示的是一个样本计算出的多个概率的熵值。通常情况下,我们考虑的是多个样本,而不仅仅是单一样本。因此,我们需要在前面添加样本的数量,最终表示为: \(-\sum_i^m\sum_j^n(px_j)ln^{(qx_j)}\)
这里主要使用Python代码来实现,因为其他语言实现起来没有必要。好的,让我们来看一下代码示例:
import numpy as np
def cross_entropy(y_true, y_pred):
# 用了一个最小值
epsilon = 1e-15
y_pred = np.clip(y_pred, epsilon, 1 - epsilon)
# Computing cross entropy
ce = - np.sum(y_true * np.log(y_pred))
return ce
# Example usage:
y_true = np.array([1, 0, 1])
y_pred = np.array([0.9, 0.1, 0.8])
ce = cross_entropy(y_true, y_pred)
print(f'Cross Entropy: {ce}')
这里需要解释一下为什么要使用一个最小值。因为对数函数的特性是,其参数 ( x ) 可以无限接近于0,但不能等于0。因此,如果参数等于0,就会导致对数函数计算时出现错误或无穷大的情况。为了避免这种情况,我们选择使用一个足够小的最小值作为阈值,以确保计算的稳定性和正确性。
在本文中,我们深入探讨了交叉熵函数作为一种重要的损失函数,特别适用于神经网络训练中。交叉熵通过衡量真实标签分布与模型预测分布之间的差异,帮助优化模型的性能。我们从信息论的角度解释了交叉熵的概念,它是基于Shannon信息论中的熵而来,用于度量两个概率分布之间的差异。
在讨论中,我们还回顾了指数和对数函数的基本概念,这些函数在交叉熵的定义和理解中起着重要作用。指数函数展示了指数级增长的特性,而对数函数则是其逆运算,用于计算相对熵和交叉熵函数中的对数项。
进一步探讨了熵的概念及其在信息论中的应用,以及相对熵(KL散度)作为衡量两个概率分布差异的指标。最后,我们详细介绍了交叉熵函数的定义和实际应用,以及在Python中的简单实现方式。
通过本文,希望读者能够对交叉熵函数有一个更加深入的理解,并在实际应用中运用此知识来优化和改进机器学习模型的训练效果。
热门资讯







