
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 PDF(Portable Document Format)是一种广泛用于文档交换的文件格式,由Adobe Systems开发。它具有跨平台性、固定布局和易于打印等特点,因此在商业、学术和个人领域广泛应用。然而,PDF文件的解析一直是一个具有挑战性的问题,因为其内部结构的复杂性和多样性,使得提取其中的文本、图片和表格等内容并不是一件容易的事情。
在目前的PDF文件解析领域中,我们可以将其大致分为以下几类技术方案:
各个解决方案目前可能需要配合使用,因为PDF格式本身的复杂程度,一项技术方案可能是 无法100%满足业务需求 的,这里面需要考虑的是:
当我们处理解析PDF时,我们需要可以讲每一项的难点都进行拆分,从需求出发,逐一进行攻破,找到解决方案。
其实我觉得技术人员如果能 通过技术手段确定PDF中的Block(块)以及阅读顺序,按Block(块)进行输出转换(Markdown/Html等),这里面包括的Block块元素:文本、图片、表格等等。那么这个提取的效果就会达到我们的最优 。
而这个目标是我们接下来要重点讨论的。
在考虑解析PDF文件时,我们需要根据当前的技术栈发展情况,并结合实际的业务诉求,综合考量这其中的技术难点,因为每一项技术难点所涉及的技术方案都会需要一个算法/或者技术手段去突破。
而开发者从解析的效果去考虑,可以从简单的做起,逐步突破难点,这对于开发人员自身的自信心提升也是一种正向的导向。在整个PDF解析过程中,我觉得以下几项是比较难处理的:
我们从解析PDF的技术可行性角度,考虑哪些方面值得我们重点关注和突破:
结合上面的技术难点/方案及可行性上去分析,我们可以看看目前开源的技术组件中,有哪些是我们可以考虑进行结合的。
因为目前TorchV系统主要以Java+Python双语作为底层的应用开发语言,接下来我们可以看看在这两个编程语言中,有哪些开源的方案可以使用。
在Java生态中,对于PDF组件处理的开源方案不多见,Apache PDFBOX是当前最强的,也是最好的
| 名称 | 地址 | 说明 |
|---|---|---|
| Apache PDFBox | https://github.com/apache/pdfbox | 提供开箱即用的文本、图片内容提取方式,并且可以基于Stream接口重写各项元素的解析实现, 并能输出元素的坐标信息 。开发者可以根据元素的坐标信息结合算法进行内容的高度还原。唯一的缺点是没有表格组件提取的API供开发人员使用。 |
| tabula-java | https://github.com/tabulapdf/tabula-java | 基于Apache PDFBOx组件的表格提取实现 |
Python生态的PDF提取组件还是蛮多的,不过也是有不同的侧重,比如pdfplumber、camelot等都专注在表格的提取上,提供了开箱即用的方案。
| 名称 | 地址 | 说明 |
|---|---|---|
| pypdf | https://github.com/py-pdf/pypdf | 一个纯Python PDF库,能够分割、合并、裁剪和转换PDF文件的页面 |
| PyMuPDF(AGPL) | https://github.com/pymupdf/PyMuPDF | 高性能 Python 库,用于 PDF(和其他)文档的数据提取、分析、转换和操作。 |
| pdfplumber (MIT) | https://github.com/jsvine/pdfplumber | 查看 PDF 以获取有关每个字符、矩形、线条等的详细信息,并轻松提取文本和表格。 |
| camelot (MIT) | https://github.com/camelot-dev/camelot | 专注于PDF中表格的提取,包括复杂的表格 |
在上面Python和Java生态库的开源组件,基本都是针对文字的PDF处理为主,当我们的PDF是扫描件时,那上面的组件统统失效,都提取不出来文本信息。
此时就需要用到OCR的模型进行提取。
考虑到如果是OCR提取,那么最终的目的是将PDF文件Page页码内容提取出完成的图片Image,所以本质上是对图片内容的理解
可以考虑的开源组件如下:
| 名称 | 地址 | 说明 |
|---|---|---|
| marker(GPL) | https://github.com/VikParuchuri/marker | 基于模型将PDF文件内容提取为Markdown格式 |
| surya(GPL) | https://github.com/VikParuchuri/surya | OCR、布局分析、阅读顺序、线条检测(支持90 多种语言) |
| tesseract(Apache 2) | https://github.com/tesseract-ocr/tesseract | 老牌OCR组件,支持100多种语言 |
| RapidOCR(Apache) | https://github.com/RapidAI/RapidOCR | 基于 ONNXRuntime、OpenVION 和 PaddlePaddle 的出色 OCR 多种编程语言工具包。 |
| PaddleOCR(Apache) | https://github.com/PaddlePaddle/PaddleOCR | 基于飞桨的出色多语言OCR工具包(实用的超轻量级OCR系统,支持80+语言识别) |
| EasyOCR(Apache ) | https://github.com/JaidedAI/EasyOCR | Python\C++开发,支持80多种语言OCR识别 |
在解析PDF时,我们也会有一些其他方面的知识储备,以便我们快速应对不同的业务需求及应用产品形态。
1、图形类API :不管是Java还是Python里面,对于处理PDF中间件的部分,都需要对图形类的API/算法熟悉和掌握,这里面包含图形的转换、缩放、矩阵坐标、截取等等,都会在PDF提取的过程中使用到。
2、PDF标准 :在处理PDF中,结合开源的技术中间件,对于PDF的ISO标准,我们也是需要了解的,这样更加有利于开发人员理解中间件的代码写法及含义。
3、边/线/矩阵算法等 :对于文本/边框的聚类算法等,在根据元素坐标高效还原时,利用高效的算法可以提高解析速度以及内容还原度
4、OCR/LLM模型等 :了解学习在用OCR/LLM模型分析布局、边界检测等等技术上的一些算法及数据工程上的实践
5、 PDF页面旋转 :有时候原PDF可能会有旋转(0、90、180、270度),需先校正后,再次提取内容
6、 字体/乱码 :系统/服务器中缺失PDF中的字体,导致文本提取乱码
本文从大的方面简单概括了在PDF解析处理过程中的技术方案/难点/开源技术方案等内容,后面我会从一些细节方面来逐一分享我们在构建TorchV产品时,解析PDF文件过程中的一些问题及技术实践,包括对表格的提取,感兴趣的可以关注我们?。
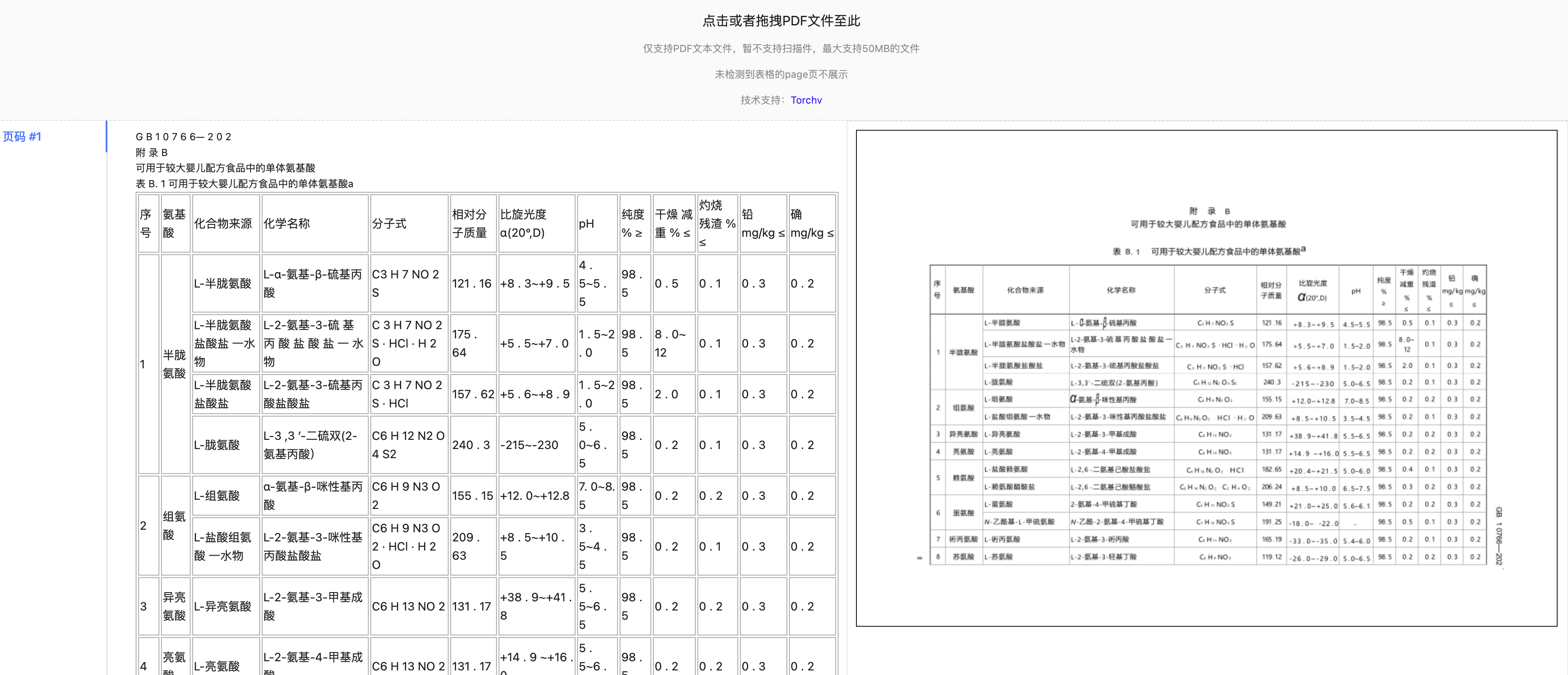
另外,我们团队提供了一个PDF解析的Demo地址,针对文本类的PDF(暂时不支持扫描件),可以进行试用体验。
地址: http://tabletest.torchv.com:8010/
热门资讯







