
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 泛型的本质是参数化类型,即允许在编译时对集合进行类型检查,从而避免安全问题,提高代码的复用性
<>
来声明类型参数.这些参数在编译时会被具体的类型替换.java在运行时,会通过类型擦除机制,将泛型类型擦除,变为原始类型(如,
String,Integer
),具体的例子将在”
泛型的使用
”中演示
ClassCastException
<>
包括起来),如
class Box
public class Box
{
private T value;//定义泛型值
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
public static void main(String[] args) {
Box stringBox = new Box<>();//实例化String类的泛型对象
stringBox.setValue("这是一个String类型范式");
System.out.println(stringBox.getValue());
Box integerBox = new Box<>();//实例化Integer类的泛型对象
integerBox.setValue(123);
System.out.println(integerBox.getValue());
}
}
interface
public interface Pair { //泛型接口
K getKey(); //Pair 接口定义了两个抽象方法 类型分别为 K,V
V getValue(); //K,V都是待定义的类型
}
public class SimplePair implements Pair{
private K key;
private V value;
//SimplePair类实现了 Pair接口 必须从写其中的抽象方法
public SimplePair(K key, V value) {
this.key = key; //SimplePair的构造函数
this.value = value;
}
@Override
public K getKey() {
return key;
}
@Override
public V getValue() {
return value;
}
public static void main(String[] args) {
//实例化 一个SimplePair对象 传入参数为 Integer,String
SimplePair integerStringSimplePair = new SimplePair(1,"one");
//则K就代表Integer V就代表String
System.out.println(integerStringSimplePair.getKey());
System.out.println(integerStringSimplePair.getValue());
}
}
public void printArray(T[] inputArray)
。泛型方法可以定义在泛型类中,也可以定义在非泛型类中。
public class Method {
public static void printArray(T[] inputArray){ //定义了一个返回值为的泛型函数
for (T element : inputArray) {
System.out.println(element);
}
}
public static void main(String[] args) {
Integer [] integers={1,2,3,4,5};
String [] strings={"abcdefg"};
printArray(integers);//调用泛型函数
printArray(strings);
}
}
?
表示类型实参,表示不确定的类型(或者是待定的类型),通常用于泛型方法,泛型类,泛型接口;通常应用于当你不确定该数据类型时
public static void printElements(List list)//假设你要写一个打印集合元素的方法
//当你不确定该集合的类型 则可以使用通配符
{
for (Object o : list) {
System.out.println(o);
}
}
public static void main(String[] args) {
List stringList=new ArrayList<>();
List integerList=new ArrayList<>();
printElements(stringList);//可以打印String
printElements(integerList);//也可以打印Integer
}
List listOfNum=new ArrayList();//使用Integer是合法的
//因为Number的子类包括 Integer Double 等等
listOfNum.add(null);//也是合法的null属于一切类型
在这个例子中,
List
表示列表可以持有
Number
类型或其子类型(如
Integer
、
Double
等)的对象,但你不能往这个列表中添加除了
null
之外的任何元素,因为编译器不知道列表的确切类型
Map
List
java中,集合框架是一组接口和类的集合,他们提供了一种数据储存和操作的方式.java的集合框架主要包括两大接口
Collection和Map
Collection
是所有单列集合的根接口,其子接口包括
List
,
Set
,
Queue
java.util.Collection下的接口和继承类关系简易结构图:
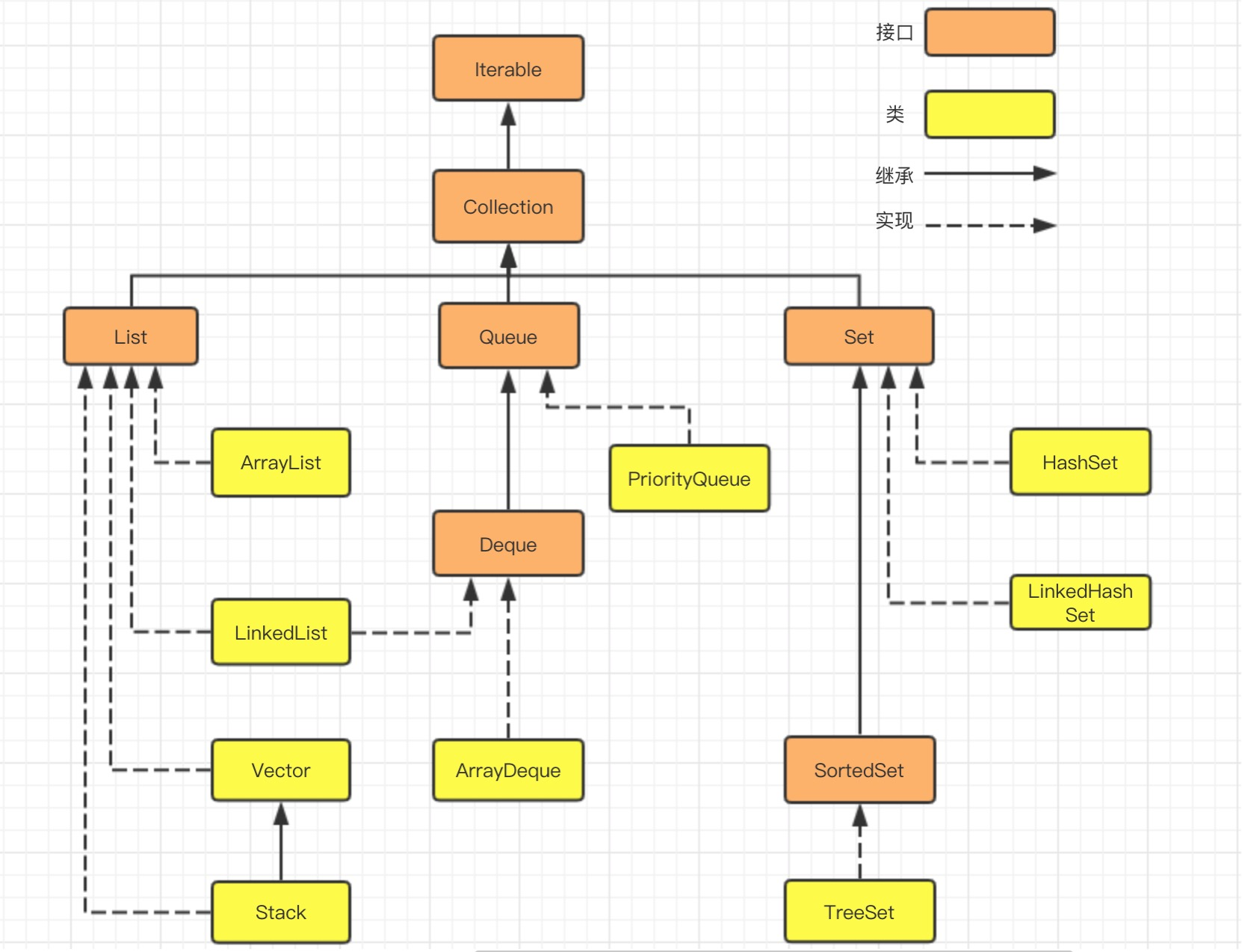
java.util.Map下的接口和继承类关系简易结构图:
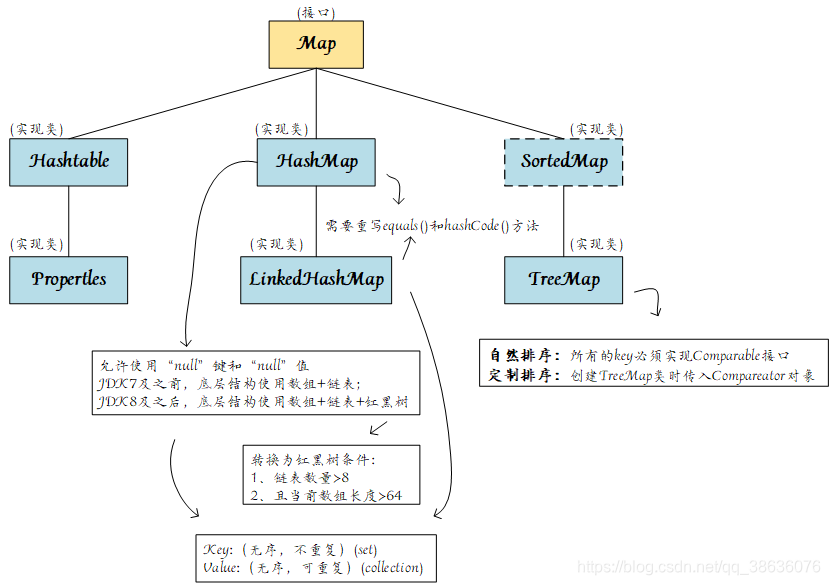
List集合也被称为序列,其允许有重复的元素.List接口的实现类主要有
ArrayList, LinkedListVector
底层使用数组实现,不是线程安全,查询速度块,但插入速度慢
public static void main(String[] args) {
//创建ArrayList对象
List list=new ArrayList<>();
//使用add()方法向数组中添加元素
list.add("张三");
list.add("李四");
list.add("王五");
//使用get(index)方法获取数组下标为index的元素
System.out.println(list.get(0));
//list的增强for循环
for (String s : list) {
System.out.println(s);
}
}
底层使用双向链表实现,查询速度慢,但其增删速度快,使用方法与
ArrayList基本一致
public static void main(String[] args) {
List list=new LinkedList<>(); //创建LinkedList对象
list.add("张三");//一下的使用方法与ArrayList一致
list.add("李四");
list.add("王五");
System.out.println(list.get(0));
for (String s : list) {
System.out.println(s);
}
底层与
ArrayList一致都是使用数组实现的,线程安全性高,但效率较低
public static void main(String[] args) {
List list=new Vector<>();//创建Vector对象
list.add("张三");
list.add("李四");
list.add("王五");
System.out.println(list.get(0));
for (String s : list) {
System.out.println(s);
}
}
其特点为无序集合,不允许有重复元素,包括主要实现类
HashSet,LinkedSet和TreeSet
作为较为常用的Set集合,其底层是基于哈希表实现的,这就决定了其无法添加重复的元素和无序性
HashSet
之所以能保证元素的唯一性是重写了其
hashCode()
方法和
equals()
方法,具体操作为:
hashCode()
值,
看其哈希值是否与以存入
HashSet
的元素的哈希值一致,若不一致则直接存入集合
,若一致则进行步骤2
equals()
方法与哈希值相同的元素进行依次比较,若返回值为ture,则说明重复则不添加,反之则添加
HashSet
是基于哈希表实现的,因此在添加元素时,不会按照其添加的顺序排放,而是根据哈希表原理,通过hash值存放.
HashSet
,在不同的JVM和实现方法下其遍历顺序都是不同的
HashSet integerHashSet = new HashSet<>(); //创建HashSet对象
integerHashSet.add(1);
integerHashSet.add(1);//使用add方法向其插入元素
integerHashSet.add(2);
integerHashSet.add(-1);
for (Integer integer : integerHashSet) {
System.out.println(integer);
} //打印结果为 -1 1 2
作为
HashSet的子类,继承了HashSet的所有特性,即不允许集合中有重复元素, 但与HashSet不同的是LinkedHashSet内部维护了一个双向链表, 用于实现按元素的插入的顺序实现遍历
LinkedHashSet
底层的数据结构
包括一个数组和一个双向链表
(或者是红黑树),这个数组和双向链表(或者红黑树)共同构成了
LinkedHashMap
(本文将在下文讲解到),的实现基础,
而
LinkedHashSet
就是通过封装
LinkedHashMap
来实现其功能,即底层是基于
LinkedHashMap
实现的
LinkedHashSet
,在添加元素时,都会调用
LinkedHashMap
的
put
方法来实现
.LinkedHashMap
的put方法首先会计算插入元素的哈希值,并根据哈希值确定元素在数组中的位置,然后,
会在双向链表(或红黑树)添加一个节点,保存元素值
,因此每次遍历
*LinkedHashSet
时实际上是遍历其双向链表(红黑树)*,从而保证了遍历顺序与元素插入顺序一致
LinkedHashSet integerLinkedHashSet = new LinkedHashSet<>();
//创建一个LinkedHashSet对象
integerLinkedHashSet.add(1);
integerLinkedHashSet.add(1);//添加元素
integerLinkedHashSet.add(2);
integerLinkedHashSet.add(-1);
for (Integer integer : integerLinkedHashSet) {
System.out.println(integer);
}//打印结果与插入顺序一致 1 2 -1
TreeSet是Set的子类,因此也保留的Set接口的特性,特别的是TreeSet是基于红黑树实现的
TreeSet
的底层实际上是基于
TreeMap
作为底层存储实现的,TreeSet内部维护了一个
NavigableMap
(实际上就是
TreeMap
的一个实例化对象),用于存储元素,在这个映射中,键(key)就是TreeSet中的元素,而值(value)是一个固定的关系共享的Object对象,(在TreeSet中,这个Object对象被命名为PRESENT),用于表现值的存在性,不储存特点的值.
以下是TreeSet内部代码结构:
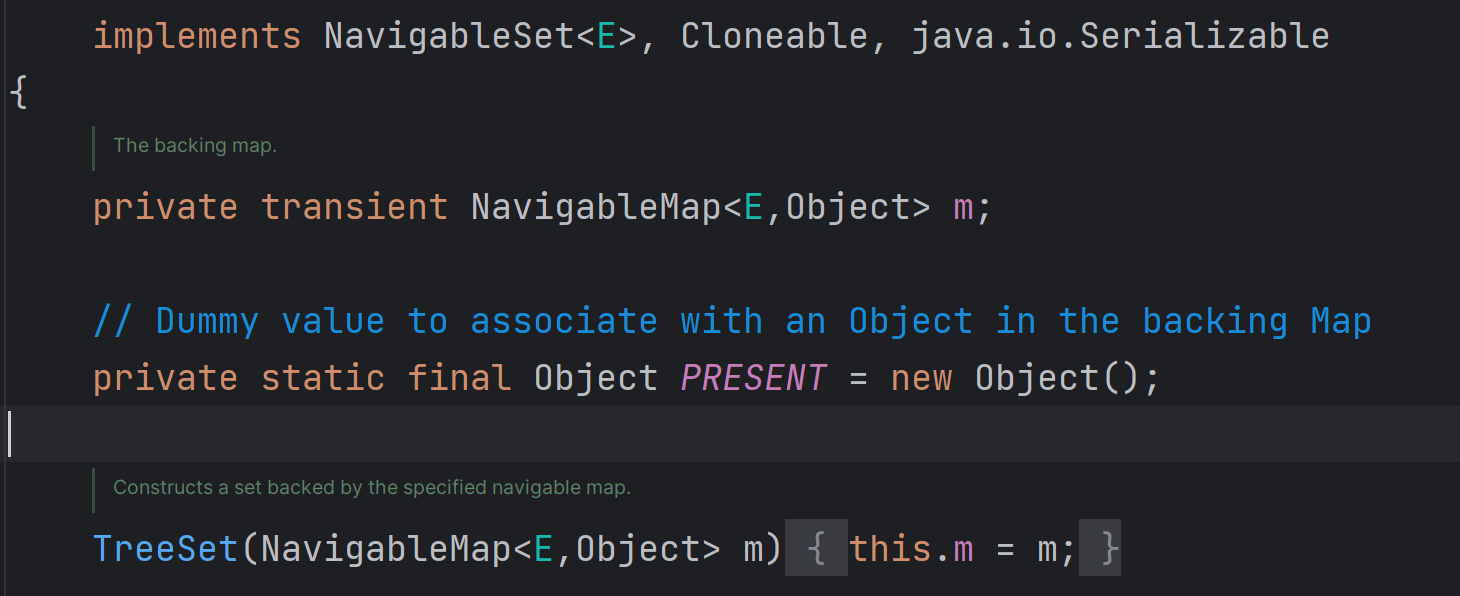
TreeSet
元素默认是根据自然顺序或
根据指定的
Comparator
进行排序
,如果没有提供
Comparator
则,TreeSet会按照元素自然排序;如果提供了
Comparator
则使用
Comparator
来确定元素的顺序
public class NumComparator implements Comparator {
//NumComparator类实现了Comparator接口
@Override//重写了compare方法
public int compare(Integer o1, Integer o2) {
return Integer.compare(o1,o2);
}
}
TreeSet integerTreeSet = new TreeSet<>(new NumComparator());
//传入NumComparator对象表明该TreeSet以该方式排序元素
integerTreeSet.add(1);//添加元素
integerTreeSet.add(-1);
integerTreeSet.add(2);
for (Integer integer : integerTreeSet) {
System.out.println(integer);
}打印结果为[-1,1,2]
| 返回值类型 | 方法和描述 |
|---|---|
| boolean | add(E e) 将指定的元素追加到此列表的末尾。 |
| void | add(int index, E element) 在此列表中的指定位置插入指定的元素。 |
| boolean | addAll(Collection c) 按指定集合的Iterator返回的顺序将指定集合中的所有元素追加到此列表的末尾。 |
| boolean | addAll(int index, Collection c) 将指定集合中的所有元素插入到此列表中,从指定的位置开始。 |
| void | clear() 从列表中删除所有元素。 |
| boolean | contains(Object o) 如果此列表包含指定的元素,则返回 true 。 |
| E | get(int index) 返回此列表中指定位置的元素。 |
| int | indexOf(Object o) 返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1。 |
| boolean | isEmpty() 如果此列表不包含元素,则返回 true 。 |
|
Iterator
|
iterator() 以正确的顺序返回该列表中的元素的迭代器。 |
| int | lastIndexOf(Object o) 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。 |
| E | remove(int index) 删除该列表中指定位置的元素。 |
| boolean | remove(Object o) 从列表中删除指定元素的第一个出现(如果存在)。 |
| boolean | removeAll(Collection c) 从此列表中删除指定集合中包含的所有元素。 |
| E | set(int index, E element) 用指定的元素替换此列表中指定位置的元素。 |
| int | size() 返回此列表中的元素数。 |
| Object[] | toArray() 以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。 |
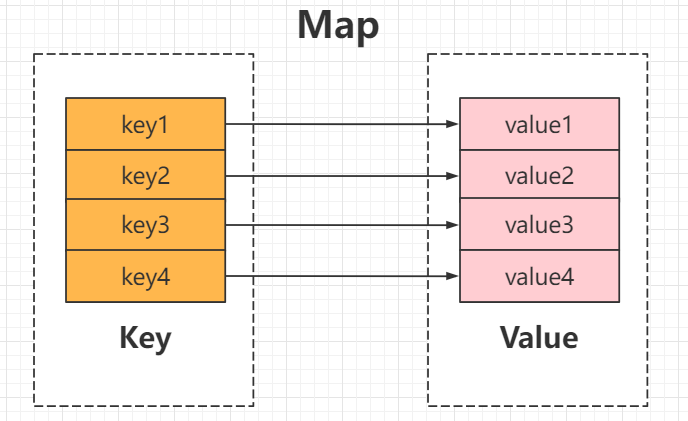
Map是一种将键(key)映射到值(value)的对象,它提供了一种键值对的储存机制, 其中每个键都唯一映射到一个值, 这种结构有利于快速查找,插入和删除值
Map的存储结构:
HashMap是基于哈希表实现的,它允许使用null键和null值,HashMap不保证映射的顺序,即遍历Map时元素的顺序可能与插入顺序不同,HashMap底层主要维护一个数组和一个链表
HashMap
的底层原理:
HashMap
底层维护了一个数组,被称为”桶”,用来储存多个键值对,没有指定初始量时,数组默认长度是16
HashMap integerStringHashMap = new HashMap<>();//创建HashMap对象
integerStringHashMap.put(1,"one");//Map使用put添加元素
integerStringHashMap.put(-1,"-one");
integerStringHashMap.put(2,"two");
for (Map.Entry entry : integerStringHashMap.entrySet()) {
System.out.println(entry.getKey()+" "+entry.getValue());
}//对于Map有特殊的遍历方式,本文将会在下文解析
//输出[-1 -one,1 one,2 two]
TreeMap是基于红黑树实现的Map接口,基于这种数据结构让TreeMap可以在log(n)时间复杂度完成containsKey、get、put和remove等操作.TreeMap是实现TreeSet的基础
Comparator
实现
TreeMap integerStringHashMap = new TreeMap<>();//创建TreeMap对象
integerStringHashMap.put(1,"one");//Map使用put添加元素
integerStringHashMap.put(-1,"-one");
integerStringHashMap.put(2,"two");
for (Map.Entry entry : integerStringHashMap.entrySet()) {
System.out.println(entry.getKey()+" "+entry.getValue());
}//对于Map有特殊的遍历方式,本文将会在下文解析
//输出[-1 -one,1 one,2 two]
HashTable底层原理与HashMap十分相似,但与HashMap相比HashTable的put,get,remove加上了同步块,和使用了this锁,则使得HashTable线程是安全的,但性能较低
NullPointerException
异常
HashMap integerStringHashMap = new HashMap<>();//创建HashMap对象
integerStringHashMap.put(1,"one");//Map使用put添加元素
integerStringHashMap.put(-1,"-one");
integerStringHashMap.put(2,"two");
for (Map.Entry entry : integerStringHashMap.entrySet()) {
System.out.println(entry.getKey()+" "+entry.getValue());
}//对于Map有特殊的遍历方式,本文将会在下文解析
//输出[-1 -one,1 one,2 two]
LinkedHashMap继承了HashMap,Linked的内部维护了一个双向链表用于保证元素的顺序
LinkedHashMap
内部结构:
其内部结合了
哈希表和双向链表两种数据结构,
哈希表用于快速检索元素,双向链表用于维护元素的顺序
LinkedHashMap
时,会在链表的尾部添加一个新的节点。如果设置了按访问顺序排列(通过构造函数或
setAccessOrder
方法),则每次访问元素时,会将该节点移动到链表的尾部,以保持访问顺序
LinkedHashMap integerStringHashMap = new LinkedHashMap<>();//创建LinkedHashMap对象
integerStringHashMap.put(1,"one");//Map使用put添加元素
integerStringHashMap.put(-1,"-one");
integerStringHashMap.put(2,"two");
for (Map.Entry entry : integerStringHashMap.entrySet()) {
System.out.println(entry.getKey()+" "+entry.getValue());
}//对于Map有特殊的遍历方式,本文将会在下文解析
//输出[1 one,-1 -one,2 two]
由于Map数据结构的特性,(使用键值对),因此必须指定要遍历的条件,例如按键或按值遍历等等
使用
entrySet()
和增强for循环:
通过
entrySet()
方法,
Map可以被转换为一个包含Map.Entry对象的Set集合,其中每个Map.Entry对象都代表Map中的一个键值对
。然后,可以使用增强for循环来遍历这个Set集合
LinkedHashMap integerStringHashMap = new LinkedHashMap<>();//创建LinkedHashMap对象
for (Map.Entry entry : integerStringHashMap.entrySet()) {
System.out.println(entry.getKey()+" "+entry.getValue());
}
使用
KeySet()
和增强for循环:
如果只对Map的键感兴趣,可以使用
keySet()
方法获取一个包含Map中所有键的Set集合
,然后遍历这个集合。如果需要获取对应的值,可以通过键来从Map中获取。
LinkedHashMap integerStringHashMap = new LinkedHashMap<>();
for (Integer integer : integerStringHashMap.keySet()) {//其中integer表示Map的键值
//通过Map方法的get(key)方法返回的是通过key映射的value
System.out.println(integer+integerStringHashMap.get(integer));
}
使用
values()
和增强for循环:
与
KeySet()
方法同理,如果只对Map的值感兴趣,可以使用
values()
方法获取一个包含Map中所有值的Collection集合,然后遍历这个集合。
但请注意,这种方式无法直接获取到对应的键。只能获取其value值
LinkedHashMap integerStringHashMap = new LinkedHashMap<>();//创建LinkedHashMap对象
for (String value : integerStringHashMap.values()) {
System.out.println(value);
}
使用
entrySet()
和
Iterator
迭代器
使用
entrySet()
方法结合
Iterator
迭代器来遍历
Map
中的键值对是一种
常见的做法
,尤其当需要同时访问键和值时,
整体是通过while循环实现的
在使用前必须使用
interator()
方法构建一个
interator
对象,并且需要通过
Iterator
的
hasNext()
方法检查是否还有下一个元素。
使用
Iterator
的
next()
方法获取下一个
Map.Entry
对象,从
Map.Entry
对象中使用
getKey()
和
getValue()
方法分别获取键和值。
LinkedHashMap integerStringHashMap = new LinkedHashMap<>();
Iterator> iterator = integerStringHashMap.entrySet().iterator();
//使用interator()创建一个intertor对象这步其实为联合方法可以分为一下两步
while (iterator.hasNext())
{
Map.Entry entry = iterator.next();
//每次通过next()方法获取entries的下一个实体 储存再entry中
Integer key=entry.getKey();//使用迭代器的getKey()方法可以获取键
String value=entry.getValue();//getValue()方法可以获取值
System.out.println(key+value);
}
Iterator
//使用interator()创建一个intertor对象这步其实为联合方法可以分为一下两步
entrySet()
方法创建一个Set集合:
Set
其中
Map.Entry<>
表示Map中的一个实体
interator()
构造一个
interator
对象
Iterator
热门资讯







