
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版
本篇文章就是一个过渡学习的,先入门shell脚本,由于作者有编程基础,所以有些解释的比较少。由于现在还在努力学习中,以后等本散修进阶了之后再写进阶的、与网络安全更加贴合的shell编程
指定shebang的意思是指定脚本执行的解释器
#!/bin/bash #指定bash执行,那这就是shell语言脚本了
#!/bin/python #指定python解释器,那么这个就是python语言脚本
#!/bin/perl #指定perl解释器,那这个脚本就是perl语言脚本
查看历史指令最大存储条数
echo $HISTSIZE
存放用户执行的历史指令的文件
echo $HISTFILE
快速查看历史指令
!1000 #查看第1000条历史指令是什么
!! #执行上一条指令
反引号执行指令
`ls` #反引号中的字符会当成指令执行
文件是否能执行得看文件是否具有x执行权限
ll filename #查看文件属性
chmod +x filename #添加执行权限 这样直接+x就是a+x
有执行权限的文件通常是标志绿色的
执行shell脚本方式
source shell.sh
. shell.sh
./shell.sh
bash shell.sh
sh shell.sh
source和.是在当前环境中加载变量,所以你使用这两个命令加载shell脚本后,里面的变量就会加载到你当前的bash中,而不会开启子shell,所以慎用这两个命令。(这两个source和.符号,在后面函数分文件中也会用到)
每个用户家目录下都有一个自己的变量文件,是在系统加载的时候加载
.bash_profile
该文件作用是先加载.bashrc
然后再加载你下面定义的变量等等
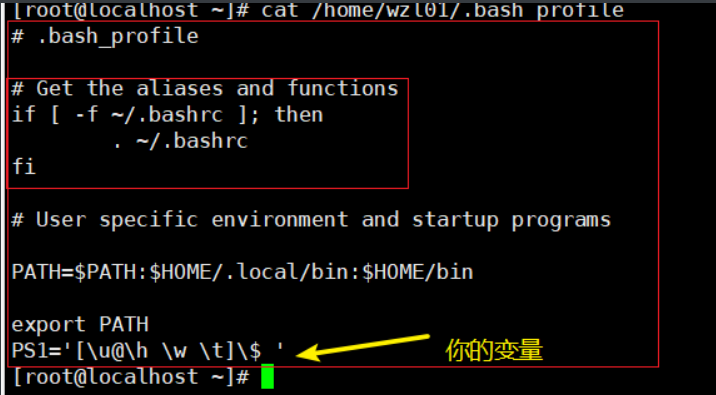
这里提前说明一下如何加载,注意是加载不是执行
source filename
. filename
以上两个都是加载文件的操作,这两个方法都是可以在该文件没有x执行权限的时候进行加载
因为如果要按照shell脚本进行加载的话,那么你里面的变量都会变成局部变量,那么脚本执行虽然也加载了,
但是执行完成后就会被释放,出来后依然还是没有成功加载你的变量
linux中执行shell脚本方式
./shell.sh
bash shell.sh
sh shell.sh
bash和sh单独使用的话,就是进入一个子shell中,我们可以通过pstree查看。
可以通过exit退出子shell
安装一个psmisc,主要用pstree功能来理解作用域,没有也无所谓
yum install psmisc -y
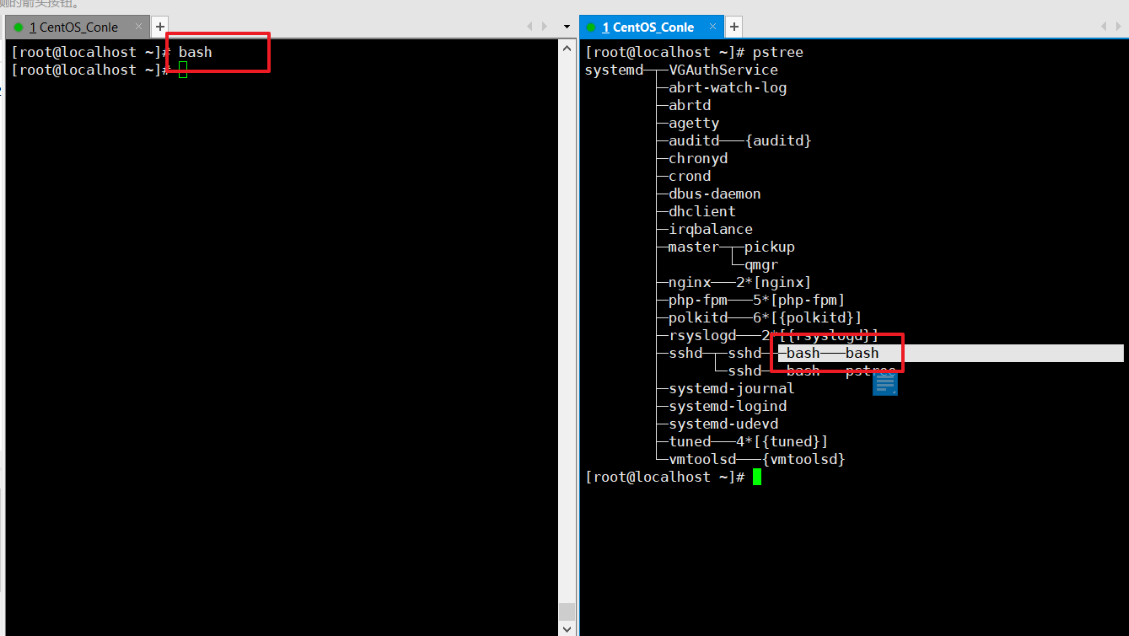
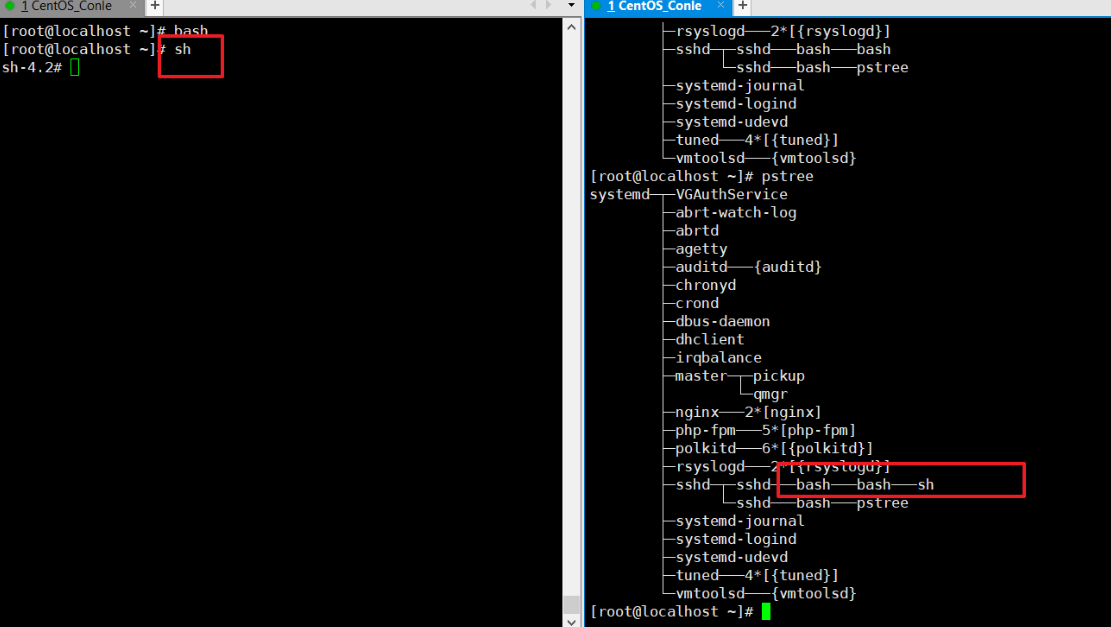
查看一下两个shell,pstree可以看到是不同bash的。
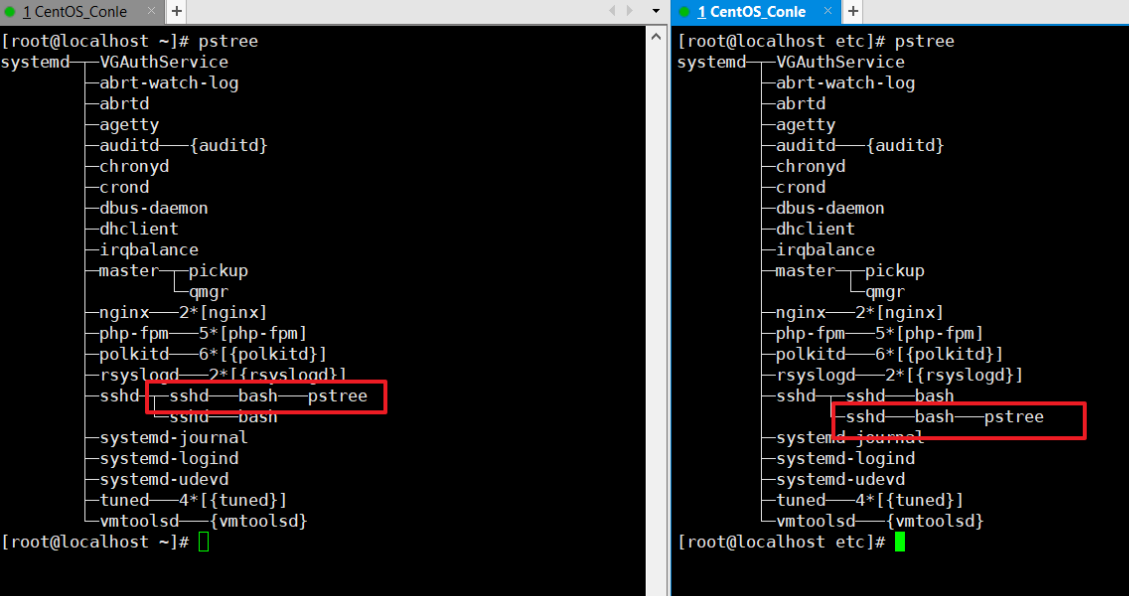
我们随便定义一个变量,可以看到不同shell之间的变量是互通不了的,原因作用域的问题
作用域大概如下,age一般定义在自己bash中的变量是不能互通的:
每一个盒子都是一个shell盒子,他们之间的变量都是不能互通的
不管是他们的全局变量还是局部变量都是不可以互通
但是除非你定义在了系统变量,比如/etc/profile这种文件中,
这种文件是在系统加载的时候加载的文件,所以每一个用户都会生效。
但是除非你自己盒子里面有和你在系统文件中定义的变量,就会被覆盖掉,以你自身的.bash_profile文件为准
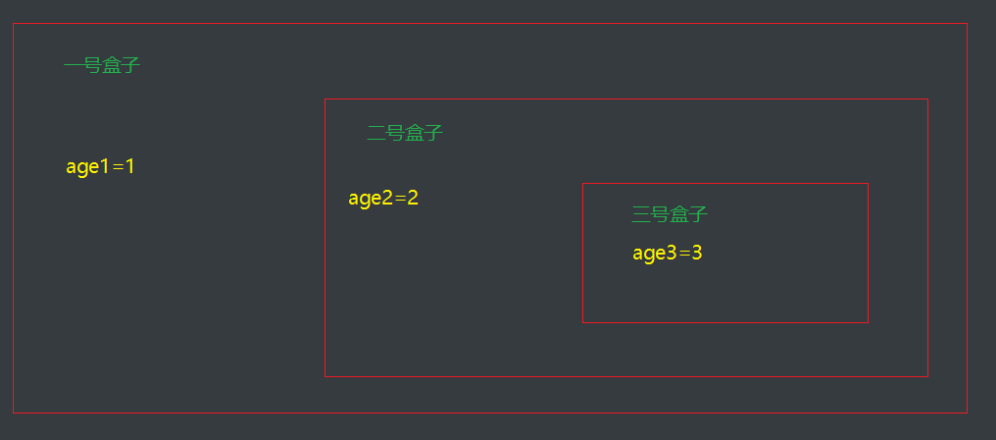
总结:
shell的作用域说白了就是每一个shell登录进来都是不一样作用域,你要全局生效就去修改/etc/profile下的系统加载文件,但是你修改了不会立刻生效,你可以使用source /etc/profile 和 . /etc/profile就能够加载一下该脚本文件,你的变量就会在你当前shell脚本生效,但是其他已经登录进来的用户不会生效,因为他没有加载系统文件,除非他退出重新登录或者source /etc/profile 或者 ./etc/profile才能加载生效。
Linux 系统中环境变量约定好都是大写,不容易和我们自己定义的出现冲突,也就是说我们定义的变量最好是小写的
查看变量相关指令
set #输出所有变量,包括全局变量和局部变量
env 只显示全局变量
declare 同set
export 显示还有设置环境变量值,在linux命令中直接使用的话是临时设置的哈
常见的环境变量
PATH:shell会到该变量定义的目录中找命令和程序
PS1:基本提示符,对于 root 用户是 #,对于普通用户是 $
HISTSIZE:最大存储的历史记录数
SHELL:该用户使用的Shell,通常是/bin/bash
HOME:当前用户给的默认主目录
LANG:语言相关的环境变量,多语言可以修改此环境变量
USER:用户名
LOGNAME:用户的登录名
HOSTNAME:主机的名称
MAIL:当前用户的邮件存放目录
撤销环境变量名
设置只读变量
readonly ,只有shell结束才能失效的变量
readonly name='abc'
name=123 #企图修改的时候就会报错下面的信息
-bash: name: 只读变量
set 查看系统中所有的系统变量
通过下图可以看到,我们每一个shell就算定义在了profile文件中,我们也要进行加载才能看到,就算我们直接grep该文件也是查看不到另一个shell中添加到profile中的变量,一定一定要使用source或者.符号进行加载才可以加载。
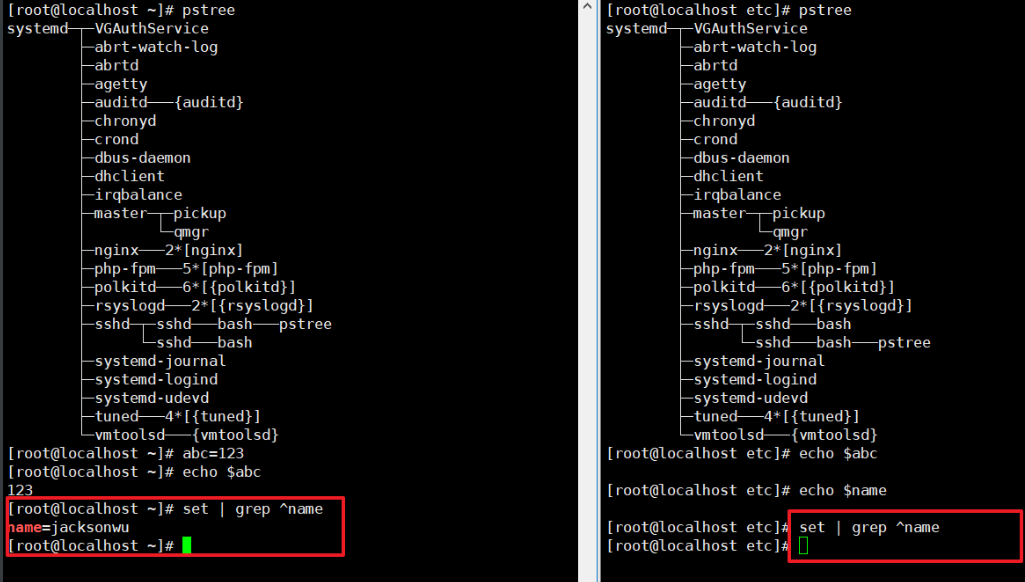
可以看到我们加载后就能够看到和使用另一个shell添加进去的name变量了。
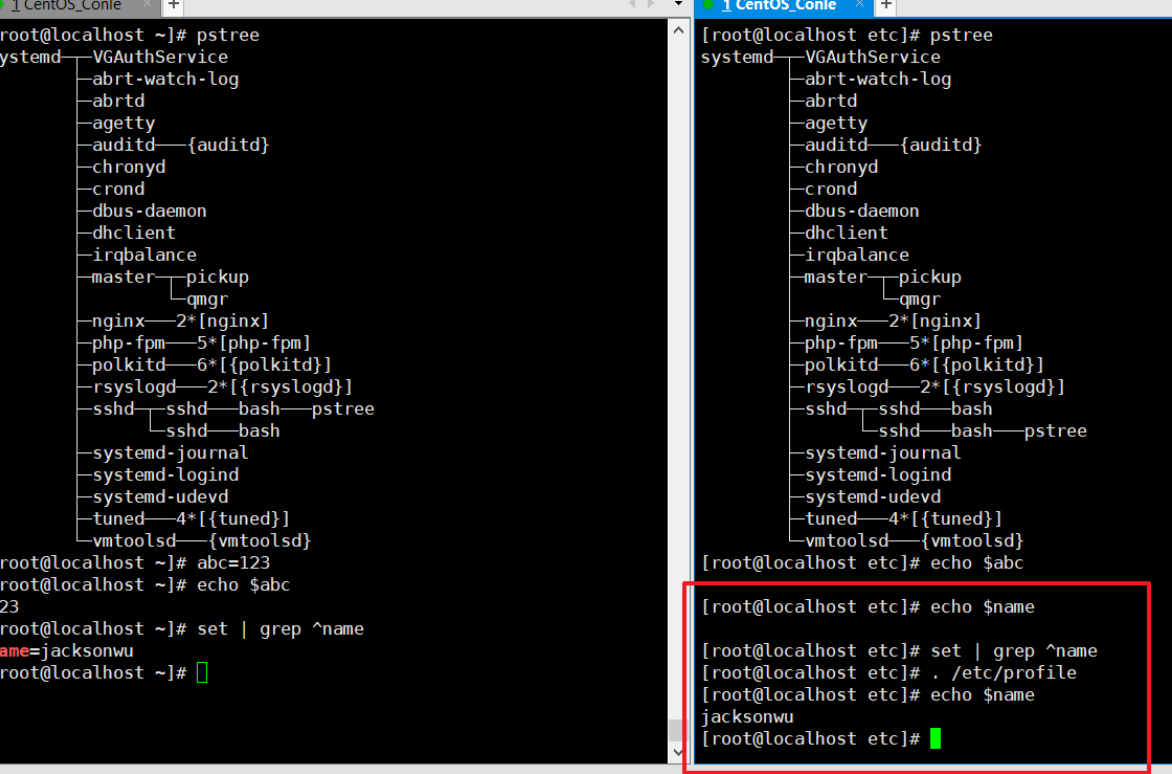
通过上面案例后,我们可以理解成:
set 就是查看系统中定义的全局变量还有局部变量,不用管他是查看哪个文件。
(PS:env就是只能看全局,比如我们用户自己在shell命令终端中定义的变量只有set能看,env看不到。)
其他查看的类型不用了解太深,其实shell脚本用到的大多都是自己定的变量,更多变量以后就会慢慢接触到。(说人话:我懒得查了)
$0 获取shell脚本的文件名以及脚本路径
$n 获取shell脚本执行的时候传入的参数,比如$1就是获取传进来的第一个参数
$# 获取执行的shell脚本后面的参数总个数,这个是统计参数个数的变量
$* 获取shell脚本传进来的所有参数,直接使用等于"$1" "$2" "$3"
"$*" 这样加上引号是获取所有参数,但是不是列表形式,而是整体"$1 $2 $3"
$@ 和 "$@" 都等于 $* ,他都是列表形式让你循环
如下脚本输出,看完就能理解这几个的区别了。
#!/bin/bash
echo '=====$@===line========='
for var in "$*"
do
echo "$var"
done
echo '=====$@===line========='
for var in $@
do
echo "$var"
done
echo '==="$@"=====line========='
for var in "$@"
do
echo "$var"
done
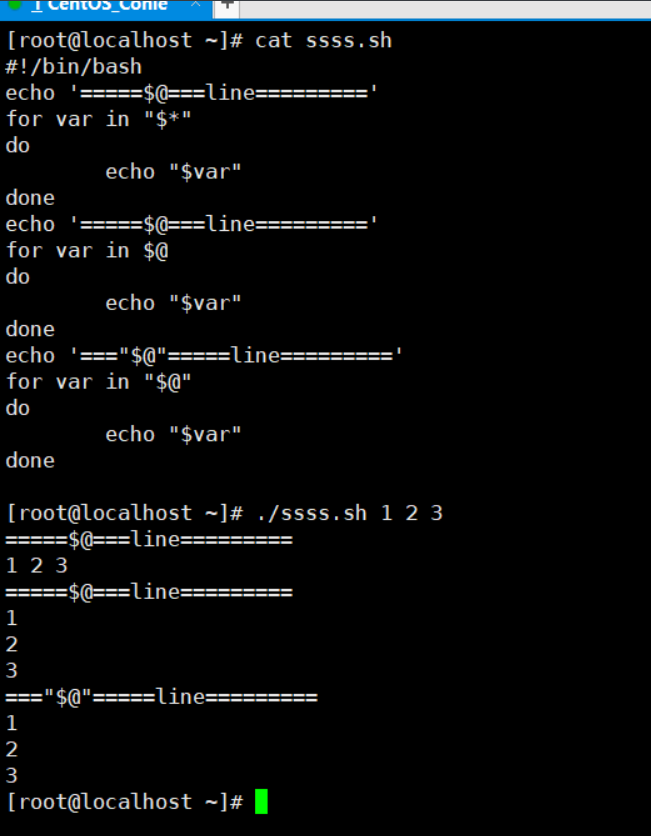
$? 上一次命令执行状态返回值,0表示正确,非零表示失败 #这里终于明白了为什么一开始学c语言的时候return 0是正常退出了!!!泪目!!
$$ 当前shell脚本的进程号
$! 上一次后台进程的PID
$_ 上次执行的命令的最后一个参数
更详细更多的特殊状态变量解释可以直接查看man手册
man bash
${变量名} #取出变量的值
$变量名 #取出变量值
$(命令) #括号中执行命令,然后返回结果
`` #反引号中执行命令,然后返回结果
() #开启子shell执行命令
内置的shell有很多,但其实在学习Linux的时候就已经有学过一些了。比如:alias也是内置的shell命令
echo
printf
eval
exec
read
echo
-n 不换行输出
-e 解析字符串汇总的特殊符号,
比如:
\n 换行
\r 回车
\t 制表符(四个空格)
\b 退格
printf
echo需要加上-e才能识别特殊符号,那printf就是可以直接解析特殊符号的。
printf "hello\nworld\n"
eval
执行多个命令
eval ls;cd /tmp;ls
其实在linux中只使用分号也能实现多个命令执行。
这里eval可能是为了在shell脚本中好执行??我也不太懂,以后再深入了解。。。
exec
不创建子进程然后执行你给的命令,然后执行结束后就直接退出当前shell,说白了就是exec执行命令后就会自动exit你当前的shell
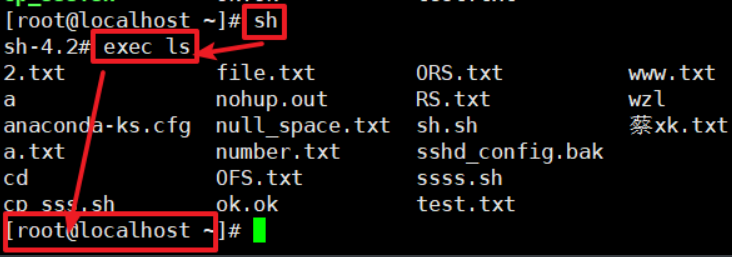
read
read [-参数] [变量1 变量2 ...]
注意:变量1 2 这些是输入的数据,然后按照顺序给到变量,变量名可以随便起,后面要使用该变量的时候按照正常的$符号取变量值即可。
-p #显示提示信息,后面加上你要提示的字符串
-r #不对输入的字符进行转义,读到什么字符串就输出什么字符串
-t #限制用户输入的时间,单位秒
-s #静默模式,不会显示你输入的内容,就像你修改密码的时候也不会显示出来
-p参数解释
read -p '请输入数据:' name age
echo $name
echo $age
脚本读到read这行的时候就会要求用户输入数据,然后数据会按照顺序给到变量name和age
-t参数解释
read -t 5 -p "请输入你要修改的名字:" name
echo $name
脚本读到read这行的时候就会要求用户输入数据,然后数据给到name变量
这里使用name作为变量,下面都使用name
${name} 返回变量值
${#name} 返回name的字符长度(这个获取长度命令很快)
${name:start} 返回name变量的start下标开始以及后面的字符
${name:start:length} 返回name变量的start下标开始然后截取length个字符
下面介绍删除字符的
str_or_pattern意思是可以是字符也可以是正则匹配模式,最短和最长就是因为有正则模糊匹配
${name#str_or_pattern} 从变量开头开始删除匹配最短str_or_pattern
${name##str_or_pattern} 从变量开头开始删除匹配最短的str_or_pattern
${name%str_or_pattern} 从变量结尾开始删除匹配最短的str_or_pattern
${name%%str_or_pattern} 从变量结尾开始删除匹配最长的str_or_pattern
下面介绍替换字符的
下面这种方式有点像我们sed还有vim里面自带的字符替换,所以说Linux语法都是大差不差的哈
${name/pattern/string} 用string替换第一个匹配的pattern
${name//pattern/string} 用string替换所有匹配的pattern
注意
#上面的删除字符#和%这两个,#开头一定要匹配上,比如name=123abcABC456abcABC
#那么我们要删除的话肯定是1开头的,如果不是1开头就无效,给你返回源字符了
[root@localhost ~]# echo ${name#1*c}
ABC456abcABC
[root@localhost ~]# echo ${name##1*c}
ABC
[root@localhost ~]# echo ${name##2*c} #匹配不正确导致的输出原变量值
123abcABC456abcABC
#那么同理%也是,只不过是从结尾开始匹配,那么我们给的str_or_pattern结尾要和变量最后一个字符一样才行哈
[root@localhost ~]# echo ${name%b*C}
123abcABC456a
[root@localhost ~]# echo ${name%%b*C}
123a
[root@localhost ~]# echo ${name%%C*a} #匹配不正确导致的输出原变量值
123abcABC456abcABC
最快统计字符方式就是自带的
echo ${#name}
wc
-L 统计字符数最多那一行,输出他的字符数量
-l 统计文件行数
-c 统计文件字符数
expr length "字符"
直接输出字符长度,这里可以使用变量,当然你用变量的话记得使用双引号
expr length "${name}"
计算方式:time 指令
比如我们这里统计上面统计字符长度哪个指令是速度最快的
待检测数据为:
time for i in {1..10000};do str=`seq -s "ok" 10`;echo ${#str} &> /dev/null;done
修改${#str}部分为其他统计字符指令即可检测不同指令之间的效率
知识点:
&>是1&2>的缩写
&1是为了标识1不是一个文件,而是一个标准输出,所以 2>&1意思是将标准错误输入到标准输出1中
command &> /dev/null 等于 command > /dev/null 2>&1
${#str} 这种方式最快
[root@localhost ~]# time for i in {1..10000};do str=`seq -s "ok" 10`;echo ${#str} &> /dev/null;done
real 0m10.319s
user 0m4.307s
sys 0m6.660s
wc -L 需要使用到管道符一般都比较慢
[root@localhost ~]# time for i in {1..10000};do str=`seq -s "ok" 10`;echo $str | wc -L &> /dev/null;done
real 0m19.679s
user 0m12.981s
sys 0m13.072s
expr length "${str}"
[root@localhost ~]# time for i in {1..10000};do str=`seq -s "ok" 10`;expr length "${str}" &> /dev/null;done
real 0m19.057s
user 0m8.865s
sys 0m11.688s
数据
[root@localhost ~]# touch whoisdhan_{1..10}_nono
[root@localhost ~]#
[root@localhost ~]# ls who*
whoisdhan_10_nono whoisdhan_4_nono whoisdhan_8_nono
whoisdhan_1_nono whoisdhan_5_nono whoisdhan_9_nono
whoisdhan_2_nono whoisdhan_6_nono
whoisdhan_3_nono whoisdhan_7_nono
将上面的文件所有带_nono的,都替换为空,比如whoisdhan_10_nono 变成 whoisdhan_10
答案不止一个,下面是我的答案
for var in `ls who*`;do mv $var ${var//_nono/};done
#从这里可以扩展一下思维。我第一时间想到的是find命令进行查找,其实不用,因为我们的文件就在该目录下了,直接ls通配符模糊匹配即可。
注意:这里我个人认为是适合用在开发脚本的时候,对脚本接受到的参数进行筛选甄别。
${parameter:-str} #如果parameter为空的时候,就返回str字符串,不为空那就返回parameter
${parameter:=str} #如果parameter为空的时候,将parameter赋值为str并且返回str值
${parameter:?str} #如果parameter为空的时候,将str当作错误内容输出,否则输出parameter值
就像下面这样
[root@localhost ~]# echo ${q:?空变量}
-bash: q: 空变量
${parameter:+str} #parameter为空的时候啥也不做,如果不为空那就返回str(可以用来判断某些参数是否为空)
就像下面这样
[root@localhost ~]# echo ${name:+不为空}
不为空
下面是我看超哥教程的一份图解:
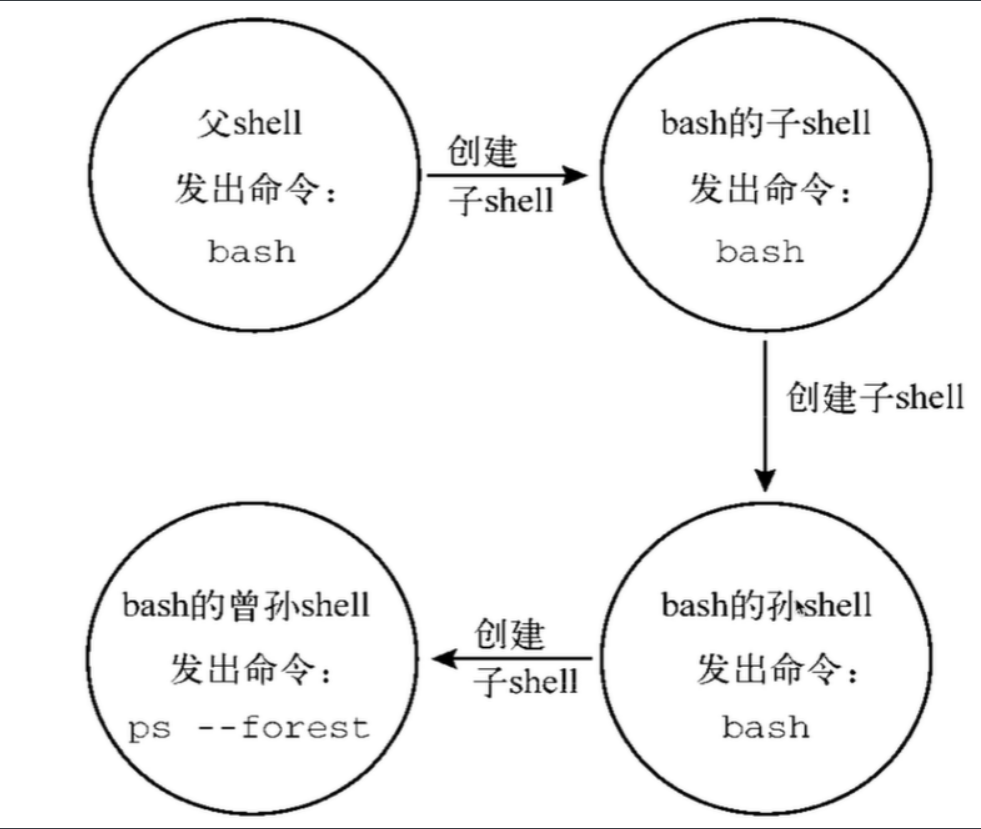
为什么要理解父子shell的关系,原因是因为我们shell编程中一个括号就能够开启一个子shell,目的是不让某些操作比如Ping指令将我们当前的shell卡主,这样的话你可以开一个子shell去执行ping这种指令,然后可以让shell脚本继续执行下去。

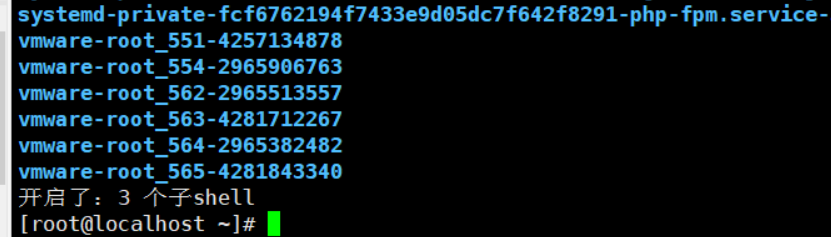
$BASH_SUBSHELL该变量是检测开启了几个子shell
(cd ~;pwd;ls;(cd /tmp;ls;(echo "开启了:$BASH_SUBSHELL 个子shell")))
识别内置还是外置
type cd
type rename
快速查看系统有哪些是内置命令
compgen -b
先认识一下两个的意思
内置
在系统启动时就加载内存,常驻内存,执行效率更高,但是占用资源
外置
系统需要从硬盘中读取程序文件,再读入内存加载
二者区别:
内置就是不开启子进程,直接在当前shell中执行,外置就是需要下载的一些系统命令,使用外置命令的时候需要开启一个子进程执行。

((i=i+1)) #双括号里面进行一系列的运算
$((i=i+1)) #加个$符号就是取你计算出来的结果
((条件判断)) #为真返回1,为假返回0
注意:
假设你有一个变量名为name=123
当你使用双括号进行name变量运算的时候是按照你name本来的值进行运算的,同时可以修改name的值。
((name++))
echo $name
124
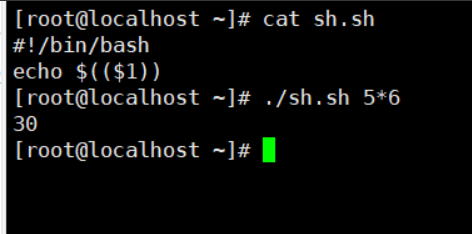
计算器简易版
#!/bin/bash
echo $(($1))
age=5
let age+=5 #let后面就能够直接使用变量进行计算了
等同于
$((age+=5)) #但是这种是会报错的,因为会把结果10当成命令执行,但是我们赋值是赋值成功了的
复习一下,之前我们使用expr进行字符长度计算
直接输出字符长度,这里可以使用变量,当然你用变量的话记得使用双引号
expr length "${name}"
expr --help
将表达式的值列印到标准输出,分隔符下面的空行可提升算式优先级。
可用的表达式有:
ARG1 | ARG2 若ARG1 的值不为0 或者为空,则返回ARG1,否则返回ARG2
ARG1 & ARG2 若两边的值都不为0 或为空,则返回ARG1,否则返回 0
ARG1 < ARG2 ARG1 小于ARG2
ARG1 <= ARG2 ARG1 小于或等于ARG2
ARG1 = ARG2 ARG1 等于ARG2
ARG1 != ARG2 ARG1 不等于ARG2
ARG1 >= ARG2 ARG1 大于或等于ARG2
ARG1 > ARG2 ARG1 大于ARG2
ARG1 + ARG2 计算 ARG1 与ARG2 相加之和
ARG1 - ARG2 计算 ARG1 与ARG2 相减之差
ARG1 * ARG2 计算 ARG1 与ARG2 相乘之积
ARG1 / ARG2 计算 ARG1 与ARG2 相除之商
ARG1 % ARG2 计算 ARG1 与ARG2 相除之余数
字符串 : 表达式 定位字符串中匹配表达式的模式
match 字符串 表达式 等于"字符串 :表达式"
substr 字符串 偏移量 长度 替换字符串的子串,偏移的数值从 1 起计
index 字符串 字符 在字符串中发现字符的地方建立下标,或者标0
length 字符串 字符串的长度
在使用expr进行计算的时候,符号与数据之间记得加上空格才能够识别成功过,和变量赋值不一样哈
加减乘除
expr 2 + 3
expr 2 - 3
expr 2 \* 3 #乘法这里要对乘号进行字符转义
expr 2 / 3
判断符号
expr 1 \> 2
expr 1 \< 2
: 冒号,计算字符串的数量
.* 任意字符串重复0或多次
看一个语法就理解了(就是有点奇怪,用冒号作为计算字符串标志)
str=str.aaa.bbb
expr $str ":" "st.*b"
11
意思是计算出str.aaa.bbb字符一共11个字符数量
"st.*b"这个是正则匹配哈,特殊符号记得加转移\
说白了expr就是正则模式匹配上了的,就统计你那个匹配上的字符,但是expr匹配模式是从字符串开始匹配的,所以只能规定后面的截止字符,
比如expr str.abc.abwwwc ":" "a*c"这样是匹配不成功的,因为字符串是s开头,而你给的匹配模式是a开头。
bc计算器
bc是可以直接当作计算机使用的。你直接敲bc命令进入后,直接输入加减乘除这些式子回车都能够给你输出接过来。
[root@localhost ~]# bc
bc 1.06.95
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
1+1
2
(1+2)*3
9
9*9
81
通过管道符计算
echo "4*4" | bc
echo '1+1' | bc
[root@localhost ~]# echo '9*3' | bc
27
[root@localhost ~]# echo "1+2*3" | bc
7
练习:计算1..100的总和
方式一:echo {1..100} | tr ' ' '+' | bc
方式二:seq -s '+' 100 | bc
方式三:seq -s ' + ' 100 | xargs expr
方式三我的理解:首先xargs不加-i参数是因为-i是要配合{}一起使用,然后是一个一个的传进去,但是expr是expr 1 + 2这样的,所以我们就不能用-i,那么我们也不能直接 seq -s ' + ' 100 | expr直接管道符接,因为相当于字符串过去了,即相当于expr "1 + 2 + ..",那我们要配合xargs这种是接到"1 + 2 + .."后,当参数给到exrp而不是整个字符串给他,那么就刚好等于expr 1 + 2 + 3 + ..
知道这种格式用法即可了
echo "2 3" | awk '{print($1*$2)}' #等于2*3=6
num=3
$[num+=2]
$[num-1]
[root@localhost ~]# num=3
[root@localhost ~]# res=$[num+=5]
[root@localhost ~]# echo $res
8
需要注意的是,不要直接就是$[num=3]这样,因为你这样就相当于执行了一个$[num=3]取出来的结果作为命令使用,当然num=3是执行成功了的哈。
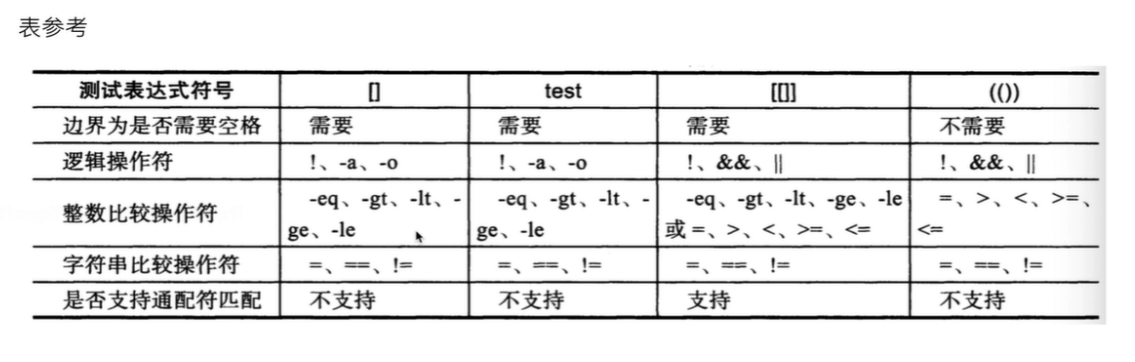
-e 测试文件或目录是否已存在,存在则返回真,否则返回假
-f 判断文件是否是普通文件类型
-d 判断是否是目录类型
-n 判断字符串不为空则为真,理解为 no zero
-z 判断字符串为空时候为真,理解为 zero
-r 判断当前用户对该文件是否有权限查看
-u 判断该文件是否具有SUID属性
-g 判断该文件是否具有SGID属性
比较参数
-eq 相等
-ne 不相等
-gt 大于
-lt 小于
-ge 大于等于
-le 小于等于
-a (and) 比如:test -r hello -a -w hello
#判读用户对该hello文件是否有r读取和w写入权限
-o (or) 比如:test -r hello -o -w hello
#判断用户对该hello文件是否有r读取或者w写入任意一个权限
! (not) 表示非,例如:test ! -r hello
表示当用户对该文件不具有r读取权限的时候就返回true,
注意写的时候! -r之间一定要有空格,否则会报错,不能连在一起写,因为-r是参数,除非你是等于号就可以连在一起!=
-e
简单做一个练习:判断hello文件是否存在,存在则打印“文件已存在” 否则打印 “文件成功创建” 并且创建hello文件
test -e "hello" && echo "文件已存在" || (touch hello && echo "文件成功创建")
-f
判断这个文件是否是普通文件类型,如果是就打印yes否则打印no
test -f hello && echo yes || echo no
-d
判断是否是目录类型
test -d hello && echo yes || echo no
-n
判断字符是否为空,不为空则打印str_yes,否则打印str_no
str=''
test -n "$str" && echo str_yes || echo str_no
-r
判断用户对文件是否有r读取权限
test -r "hello" && echo yes || echo no
-w
判断用户对文件是否有w写权限
-x
判断用户对文件是否有x执行权限
注意:如果你使用root来测试的话只能返回yes,因为root权限是最大的。
注意:[]的两边一定要一定要加上空格,否则会出错,这里在if使用中括号的时候是一样的。
文件名和目录名最好使用引号引起来,虽然可以不用引号,但是不敢担保你的文件是否有空格隔开。
格式:[ 条件表达式 ]
参数
-f 测试普通文件是否存在
-d 测试目录是否存在
-r
-w
-x
以上三个都是判断用户对文件是否有r读取、-w写入、-x执行权限。
比较参数
-eq 相等
-ne 不相等
-gt 大于
-lt 小于
-ge 大于等于
-le 小于等于
-a (and) 比如:[ -f hello -o -f world ] && echo yes || echo no
-o (or) 比如:[ -f hello -o -f world ] && echo yes || echo no
! (not) 表示非,例如:[ ! -f hello ] && echo yes || echo no
表示当用户对该文件不具有r读取权限的时候就返回true,
注意写的时候! -r之间一定要有空格,否则会报错,不能连在一起写,因为-r是参数,除非你是等于号就可以连在一起!=
判断hello文件是否存在,存在就输出yes 否则就输出 no
[ -f hello ] && echo yes || echo no
判断hello目录是否存在,存在就输出yes 否则就输出no
[ -d hello ] && echo yes || echo no
注意:在中括号中写判断符号的时候,数据与判断符号和数据之间都要用空格隔开,包括中括号也要空格哈,比如下面
(后面会解释为什么使用转移符号=)
[ "${name}" \= "123" ] && echo yes || echo no
注意:这里使用一个等号还是两个等号都是一样的哈。
意思是如果该变量name等于123的话就echo yes 否则 no
同理其他单个的符号也要空格,双个不用
[ 1 \= 1 ]
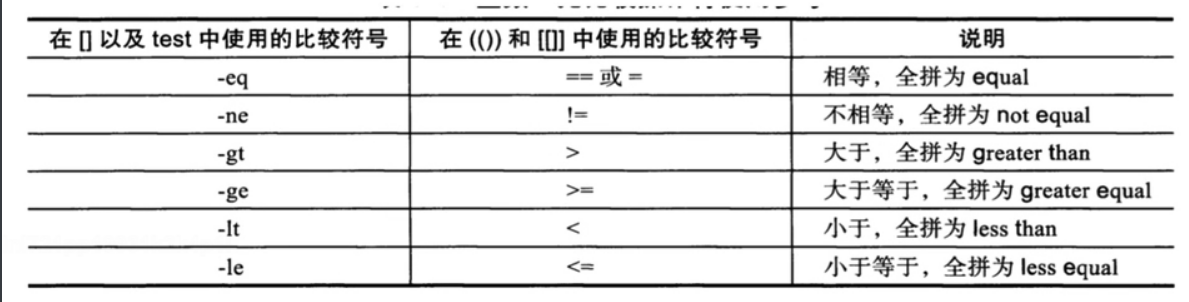
使用数学比较符号的时候记得使用转义符
[ 1 \> 2 ] 这样才对,否则你使用[ 1 > 2 ]是错误的
下面两语句执行以下就知道结果了
[ 1 \> 2 ] && echo yes || echo no
[ 1 > 2 ] && echo yes || echo no
总结:使用数学运算符的话,如果是单个字符的就要使用转移符号\,如果是!=或者==或者>=这种就不用加转义符号。
格式:[[ 条件表达式 ]]
使用起来和单中括号的区别就是:双中括号不用写转义符,就可以直接识别> < = ,那么双中括号同时还支持正则表达式匹配。
然后其他单中括号支持的在双中括号里也能用。
但是我们平时用的比较多的是单中括号。
总结括号的知识:
注意:条件表达式可以是很多种,我们上面学的shell条件判断方式否可以使用
单分支
if <条件表达式>
then
codeing...
fi
#简化
if <条件表达式>;then
codeing
fi
嵌套if
if <条件表达式>
then
codeing...
if <条件表达式>
then
fi
fi
if-else
if <条件表达式>
then
coding...
else
coding...
fi
if-elif
if <条件表达式>
then
coding
elif <条件表达式>
then
coding
else
coding...
fi
注意:case的出现是可以让你少用if else,同时他也是一个菜单化的这么一个命令。
格式
语法
case $choice in
1)
shell代码
;;
2)
shell代码
;;
3)
shell代码
;;
*) #这个是固定的,相当于我们编程中的default,就是上面的选项都没有被$变量的值的时候就会跳到这里来,在shell中一般是用来写提示信息的。
shell代码
;;
esac
#为什么是esac,很简单,我们学习if的时候是用fi解释,就是if倒过来,那么case的结束也是倒过来esac
注意:
1)
2)
3)
里面的123可以随便,只要你的$变量可以找到这个里面,你可以随便写,可以是:
qqq)
reg)
adgsaf)
*)
随便写,只要你的$变量能够找到即可。
*)最后一个是固定的
语法
for 变量名 in 循环列表(一定是列表哈)
do
shell代码
done
注意
循环列表可以是:
{1..100} shell命令自带的生成1-100的序列,当然其他命令都可以比如seq
"1 2 3 4" 这种也能够当成循环列表,以空格为分隔符号,会依次取出1 2 3 4
文本文件中你cat出来每一行也能当作列表循环
for i in $(cat /etc/passwd) #这种读取文件出来就是每一行作为一个变量
$()等于``,执行命令,不要忘记了,在这里回顾一下。
语法
while <条件表达式>
do
shell代码
done
注意
这个条件表达式和之前学的一样,shell的条件判断表达式能写的while照样可以拿来当条件表达式,不过一般都是用 [] 单中括号的比较多
定义
数组名=(值1 值2 值3)
取数组值
#根据下标取值
${数组名[下标]} #不能用$数组名[下标] ,取不到数组值
#取数组中所有的值
${数组名[*]}
${数组名[@]}
#计算数组长度
${#数组名[@]}
${#数组名[*]}
#解释:这里很巧妙使用了我们上面说的#取字符长度的写法,这里就变成了取数组长度。比如$*和$@都是取所有参数,然后我们这里就是取数组所有值,那么再结合之前学的统计字符长度${#name}这种,就完美解释和理解了为什么计算数组长度是用${#数组名[@]}这个样子了。
说明:函数必须先定义再执行
注意:return 和 exit 是不同的,exit是结束shell环境,而return是结束函数执行。
语法格式如下
#第一种
function 函数名(){
函数体
return 返回值
}
#第二种
function 函数名{
函数体
return 返回值
}
#第三种
函数名(){
函数体
return 返回值
}
#执行方式
函数名
函数名(参数1 [,参数2,...] )
说明:在shell脚本中,传参方式和你输入的参数一样,我们平常的比如touch ,touch 传参数是 touch 文件名,那么函数传参也是这样。同时,函数获取参数方式和脚本获取参数方式是一样的。(这句话理解不了就看下面的例子)
function 函数名(){
echo $1 $2 $3
return 返回值
}
#函数有参数的调用方式如下(和脚本传参一样格式)
函数名 参数1 参数2 参数3
示例脚本:
[root@localhost cxk]# cat args_sh.sh
function f(){
echo $1 $2 $3
echo "函数执行完毕。"
return 0
}
f "var1" "var2" "var3"
exit 0
[root@localhost cxk]# bash args_sh.sh
var1 var2 var3
函数执行完毕。
如果你要分文件,那么可以使用source 或者 .符号进行当前执行shell的bash中加载进来,所以这就是为什么我们不同shell之间就算定义了系统变量,也要重新加载的原因了吧 。
fun.sh文件
. fun.sh
fun1
fun2
exit 0
main.sh文件
#!/bin/bash
fun1(){
echo "fun11111 runing..."
}
fun2(){
echo "fun22222 runing..."
}
执行main.sh文件(可以看到成功分文件执行成功)
[root@localhost cxk]# bash main.sh
fun11111 runing...
fun22222 runing...
[root@localhost cxk]#
学过编程的同学都知道,我们程序主入口的名字一般都是main,
虽然我们shell中没有固定的main函数,但是我们还是进行一些规范化操作。
比如:
fun1(){}
fun2(){}
在定义了一系列函数之后,我们最后要写一个main函数来规范化我们的代码执行逻辑,一方面是方便阅读,二来也是对脚本的封装模块化能够有更深的理解。
热门资讯







