
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 你好呀,我是歪歪。
来一起看看一个关于线程池使用场景上的问题,就当是个场景面试题了。
问题是这样的:
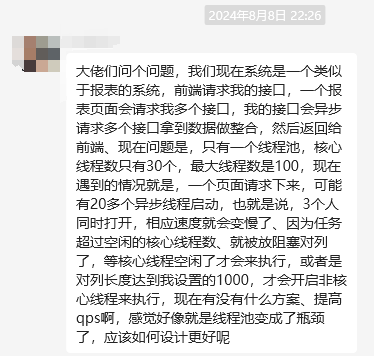
字有点多,我直接给你上个图你就懂了:
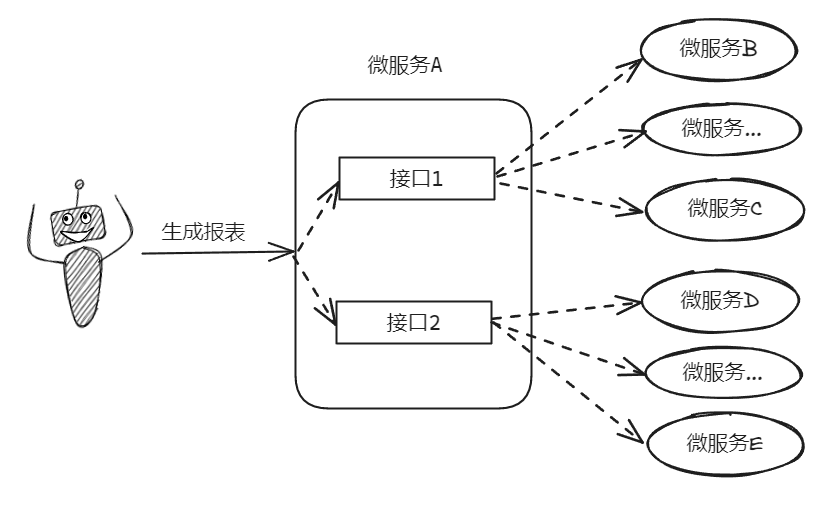
前端发起一个生成报表页面的请求,这个页面上的数据由后端多个接口返回,另外由于微服务化了,所以数据散落在每个微服务中,因此需要调用多个下游接口拿到数据进行整合。
调用多个下游接口的时候,由于接口之间不存在数据依赖,所以可以发起异步调用同时请求不同的下游接口。
也就是这里有个线程池:
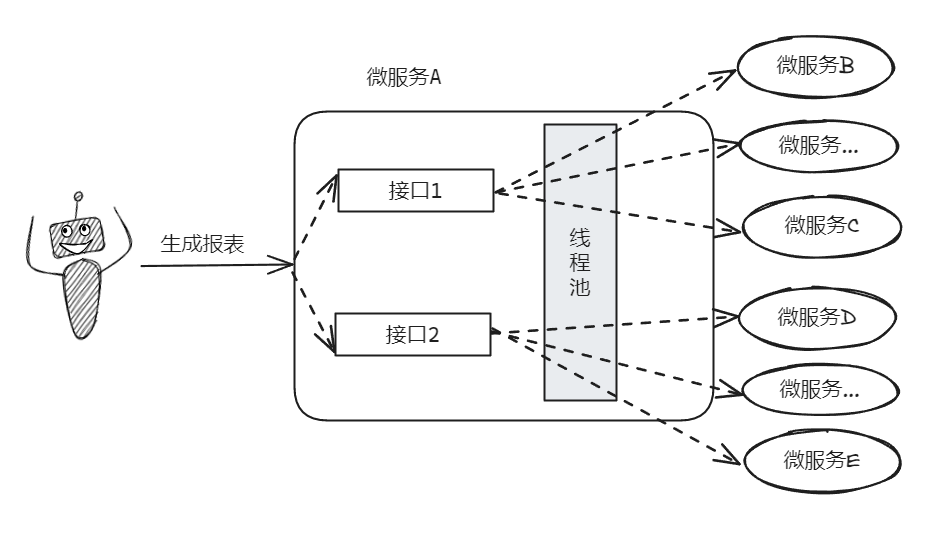
这个线程池,核心线程数只有 30 个,最大线程数是 100,队列长度是 1000。
一个报表页面的请求发过来,为了整合数据,所以会调用下游 20 多个接口获取数据。
针对这个情况,用提问者的原话就是:3 个人同时打开,相应速度就会变慢了,因为任务超过空闲的核心线程数,就被放阻塞队列了。
理论确实是这个理论。
该怎么办呢?
针对这个场景,大家能想到的一个最直接的一个方案,肯定是扩大核心线程数。
这个方案,提问者也想到了,同时还进行了进一步思考:
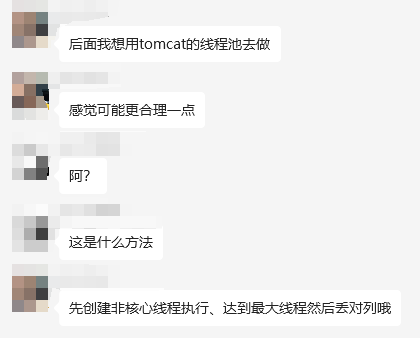
觉得应该改造一下 Spring 的这个线程池的工作模式,为了让请求尽快的得到处理,可以借鉴 Tomcat 线程池的工作模式。
Spring 这个线程池的工作模式是先启用核心线程,再启用队列,最后启用非核心线程。
Tomcat 线程池的工作模式是先启用核心线程,再启用非核心线程,最后启用队列。
思路是不错的,但是吧,我觉得在这个场景下,没啥必要。
比如 Tomcat 线程池,你的配置是核心线程数 30,非核心线程数 300,队列长度 1000。
其实你配置 Spring 线程池的时候,核心线程数 300,非核心线程数 300,队列长度 1000,效果和 Tomcat 线程池是一样的。
唯一的一点区别在非核心线程的回收,但是这一点点内存上的占用,微乎其微,我个人觉得是可以忽略不计的。
另外,在线程池配置方面,除了调整核心线程数外,还有一个常用的配置是修改线程池的拒绝策略,采用 CallerRunsPolicy,即在线程池满了的情况下,让任务调用者线程执行该任务。
这个方案在讨论的过程中也有提及到:

那这个方案可以用吗?
可以,但是需要注意一个暗坑的存在。
在任务提交线程池之后,Tomcat 的线程有两种情况:
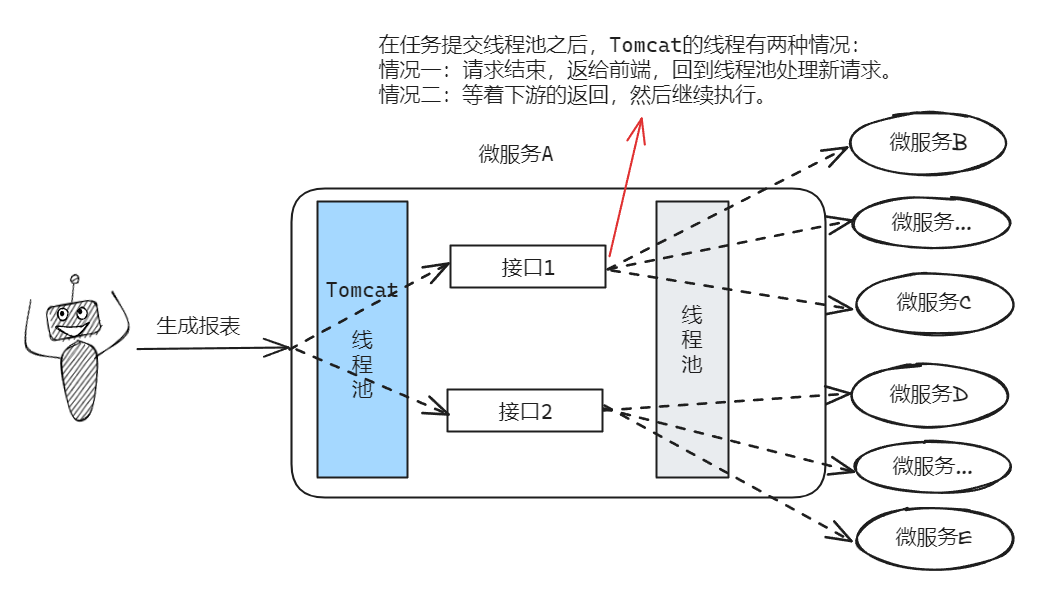
我们先看情况一,你想想,在这个场景下,CallerRun,这个 Runner 是谁?
是 Tomcat 容器的线程。
好,现在我们来想象一下这个场景:你有一个自定义线程池,但是由于下游请求中有个慢接口,导致自定义的线程池满了,触发了拒绝策略。
这个时候拒绝策略是 CallerRunsPolicy。
于是 Tomcat 线程池里面的一个线程就需要去调用这个慢接口,导致本来在提交任务到线程池之后就返回的 Tomcat 的线程被拿去调用慢接口了,产生了较长时间占用。
那么会出现一个什么情况?
就是关键资源被长时间霸占,严重的情况下,服务就对外不可用了。
你想想,假设 Tomcat 一共就 200 个线程。
其中 190 个都被你这个慢接口拖着了,只剩下 10 个线程能对外提供服务。
甚至有可能 200 个都被这个慢接口拖着,而你这个服务,对外肯定不只是这一个接口吧?
其他接口会因为,慢接口里面的线程池的拒绝策略是 CallerRunsPolicy,把资源全部占用完了,从而受到影响。
即使你其他功能的一个接口耗时只需要 10ms 也没用,也要去队列里面等着,因为现在没有资源来处理你这个请求。
而对于接口调用方来说,进入队列等待的时候,也算在接口响应耗时里面。
所以,在使用 CallerRunsPolicy 拒绝策略的时候,需要特别注意,分析一下是否会占用关键资源,导致拖慢这个服务。
但是我们这个报表的场景,属于情况二,Tomcat 的线程得等着数据返回。
等着,本来也是一种占用。所以使用 CallerRunsPolicy 没啥问题。
但是,Tomcat 线程属于宝贵资源,如果出现长时间占用,那就是一个性能瓶颈点。
所以,本质上还是不应该有明显的慢接口存在。
关于“尽快释放宝贵资源”这个点,你也可以看 Dubbo 服务段线程模型,这里相当于是一个最佳实践了:
https://cn.dubbo.apache.org/zh-cn/overview/mannual/java-sdk/advanced-features-and-usage/performance/threading-model/provider/

Dubbo 协议 Provider 线程模型的默认配置是 AllDispatcher。
针对 AllDispatcher 官方给了一个示意图:
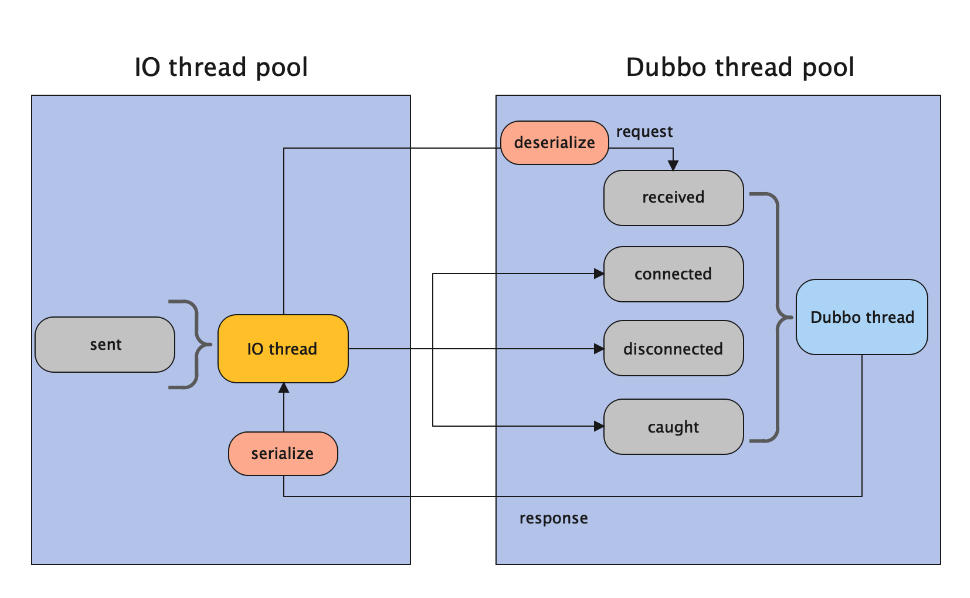
图中有 IO thread pool 和 Dubbo thread pool 这两个线程池。
为什么要搞两个线程池呢?
因为 IO 线程是非常宝贵的资源,它只是应该承担发送请求、发送响应的功能。
搞个 Dubbo 线程池的目的就是为了尽快释放宝贵的 IO 线程资源。
比如 received、connected、disconnected、caught 这些行为都是在 Dubbo 线程上执行的,反序列化的动作也是在 Dubbo 的线程池中做的。
类比到我们前面的例子中,IO 线程池就是 Tomcat 线程池,Dubbo 线程池就是我们项目中的自定义线程池。
模式,就是这个模式。
道理,就是这个道理。
如果这真的是一个面试场景题,增加核心线程数和 CallerRunsPolicy 这个方案,面试官肯定是不会满意的,你还得继续往下挖掘。
比如,为什么下游返回的那么慢?
是不是接口上有可以优化的空间?
是不是有慢 SQL?
是不是多返回了不需要的信息?
是不是有不合理的数据结构?
是不是在接口里面干了一些其他的事情?
是不是下游的下游拉胯了?
...
不要老是从自己身上找原因,也合理指出其他人的问题,对吧?
总之,20 多个异步接口,一定是有相对较慢的那个。
它,就是那块短板,找到它,然后定向分析它。
如果下游说实在是没有优化空间了,那就加点钱嘛,多搞几台机器,横向扩展一下,花不了几个钱的。
这种情况在实际工作中还真的挺常见的,歪师傅就遇到过。
上游服务有 8 台机器,我只有 4 台机器,上游并发量一起来,就说我接口响应慢了。
机器都差了一倍,请求来得又太多,都堆起来了,那可不得慢嘛。
当然了,把锅甩给下游,下游不一定会接,问题还是得靠自己解决。
通过前面的分析,我们知道了可以调大核心线程数,但是面试官直接追问一句,调到多少合适呢?
合适,就是一个很微妙的词了。
一般我们用“动态调整”来应对这个问题。
但是在这个“报表”的场景下,歪师傅觉得还真的可以调到一个合适的值,甚至可以用“精准”来形容这个值。
怎么做呢?
上个图:
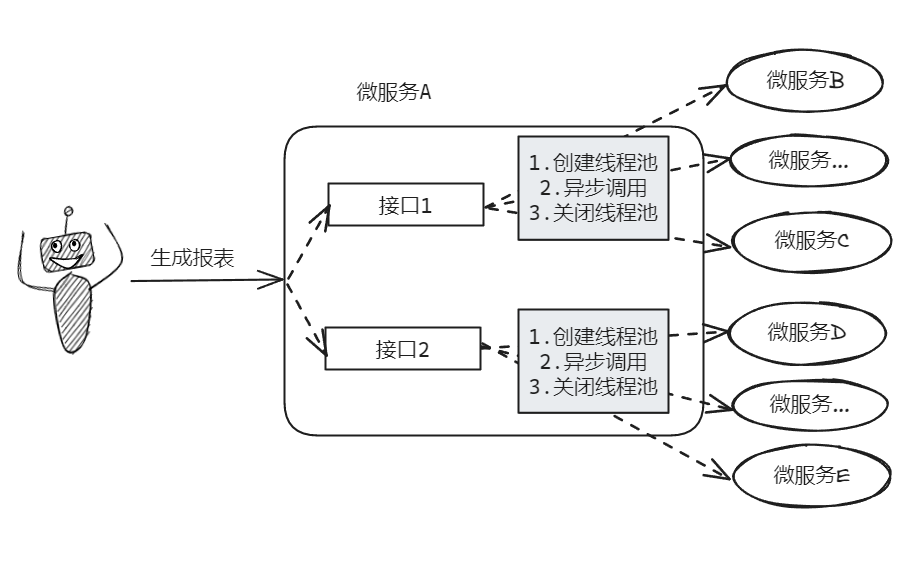
在每个接口里面搞个线程池,这个线程池的生命周期和一次请求绑定。
即一次请求结束,这个线程池就 shutdown 掉。
你一个接口背后需要调用下游的多少个异步接口,你在写的时候是知道的。
假设是 15 个,那么你在这个请求里面搞个核心线程数是 15 个的线程池。
我就问你,精不精准?
这种用法,就比较适用于这个较为特殊的场景。
特殊点就在于,需要对数据进行聚合处理,所以需要异步调用多个下游服务,要拿到下游服务的数据返回之后,才能返回给调用方。
但是这里上游服务发起调用具有不确定性,可能是同时来 10 个请求,也可能是同时来 1000 个请求。
这种情况导致怎么去合理的定义一个全局的线程池,是一个令人头疼的问题。
所以,换个思路。
在不确定性中寻找确定性。
不确定性是不知道有多少个请求会过来。确定性是每个前端过来的请求,都会对应固定数量的下游接口。
那就不要用全局的线程池了,给每个请求都单独搞个线程池,及时创建,及时回收。
当然,这个方案的弊端之一在于不存在线程池的复用了,只是为了单纯的异步。
弊端之二就是有可能瞬间产生大量的线程,对内存造成一定的压力,但是理论上这些线程都会被很快的回收,所有这点压力应该是在可以接受的范围内。
但是你想想,你调大核心线程数的根本目的是为了给每个异步任务都分配一个线程。
我上面的这个方案能达到一样的目的,而且,控制更加精准。
其实你有没有发现前面说的调整核心数、一个请求对应一个线程池这些方案都很别扭,感觉都不得劲儿?
是的,我就是有这样的感觉。
所以,我再看看问题:
“类似于报表的系统”。
如果我是刚刚工作三年的时候,我可能会在接到这个需求之后就去思考技术方案。
但是现在随着工作年限的增加,我会带着“质疑”的眼光去看待需求,去判断是否是一个“伪需求”。
在需求和技术落地之间找到一个平衡点,让业务和开发都舒服一点。
比如既然是报表为什么要求要实时响应呢?
前端发起请求,后端收到请求之后先返回前端,给个提示:哥们,收到你的请求了,生成报表需要点时间,请十分钟后到 xx 菜单下访问。
然后你后台慢慢处理,其实五分钟就生成好了,然后你给哥们发个短信提醒:数据已就位。
别人还会觉得:可以啊,挺快的,科技的哥们真厉害。
再说了,报表一般来说不都是 T-1 日的数据展示吗?
既然是 T-1 日的数据,那为什么不在凌晨做个定时任务,先主动把各个系统前一日的数据聚合一下,在本地放一份呢?
这样就不用在前端调用的时候,实时去调用接口聚合了嘛。查本地数据,那不是很快的事情,性能一下就上去了。
或者再往前想一步:为什么你要去调用别的系统的接口去获取数据呢?
因为你自己系统没有数据。
为什么你自己系统没有数据呢?
因为你们是微服务架构,数据散落在各个微服务系统里面。
那在拆分微服务的时候,有没有考虑过各种各样的报表需求?
如果考虑过,是不是就应该建设一个大数据平台,由大数据平台将各个微服务系统的业务数据抽走,然后整合数据,基于这些数据出各种各样的报表。
而微服务系统,只需要关注业务就好了。
如果你们没有大数据平台,你应该给领导充分阐述该平台在当下的必要性,以及未来的重要性。
然后,这个功能就不需要你来做了。
热门资讯







