
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 OpenAI的TTS模型是一种文本到语音(Text-to-Speech)模型,它可以将给定的文本转换为自然语音音频。TTS代表Text-to-Speech,是一种人工智能技术,它使计算机能够模拟自然语言的声音,从而实现文本的朗读。
在OpenAI的TTS模型中,用户可以选择不同的声音(Voice)和模型类型(Model),以定制生成语音的效果。声音可以是男声或女声,而模型类型可以选择不同的版本,如"tts-1"或"tts-1-hd",以满足不同的需求。
OpenAI的TTS模型是一种文本到语音(Text-to-Speech)模型,它可以将给定的文本转换为自然语音音频。TTS代表Text-to-Speech,是一种人工智能技术,它使计算机能够模拟自然语言的声音,从而实现文本的朗读。
在OpenAI的TTS模型中,用户可以选择不同的声音(Voice)和模型类型(Model),以定制生成语音的效果。声音可以是男声或女声,而模型类型可以选择不同的版本,如"tts-1"或"tts-1-hd",以满足不同的需求。
"tts-1":
"tts-1-hd":
$0.015/0.03 per 1,000 input characters,即1000字符0.015美元。
使用OpenAI的TTS模型需要通过API进行调用。以下是使用OpenAI的TTS模型的基本步骤:
在使用TTS模型之前,需要获得OpenAI的API密钥。API密钥是用于身份验证的关键信息。具体获取方式请自行查阅。
使用Python脚本调用OpenAI的API,需要安装OpenAI的Python库。可以使用以下命令进行安装:
pip install openai
pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple # 清华镜像安装,二者任选其一即可。
编写Python脚本,导入所需的库(如
openai
、
pathlib
等),并配置OpenAI的API密钥。
from pathlib import Path
from openai import OpenAI # 要求openai库版本1.0以上
# 配置OpenAI的API密钥
client = OpenAI(api_key="your_api_key")
# 设置文件路径
speech_file_path = Path(__file__).parent / "speech.mp3"
在脚本中调用OpenAI的TTS模型,指定模型类型、声音类型和输入文本,然后将生成的语音保存到文件。
# 调用OpenAI的TTS模型
response = client.audio.speech.create(
model="tts-1-hd", # 模型选择
voice="echo", # 不同语音模式选择
input="你好,世界!" # 生成内容选择
)
# 将生成的语音保存到文件
response.stream_to_file(speech_file_path)
ChatGPT在OpenAI的TTS-1模型中,Alloy、Echo、Fable、Onyx、Nova和Shimmer代表不同的语音模式或声音类型。每种语音模式都具有独特的音质、音调和语音特点。
Alloy(合金):
Echo(回声):
Fable(寓言):
Onyx(黑玛瑙):
Nova(新星):
Shimmer(闪光):
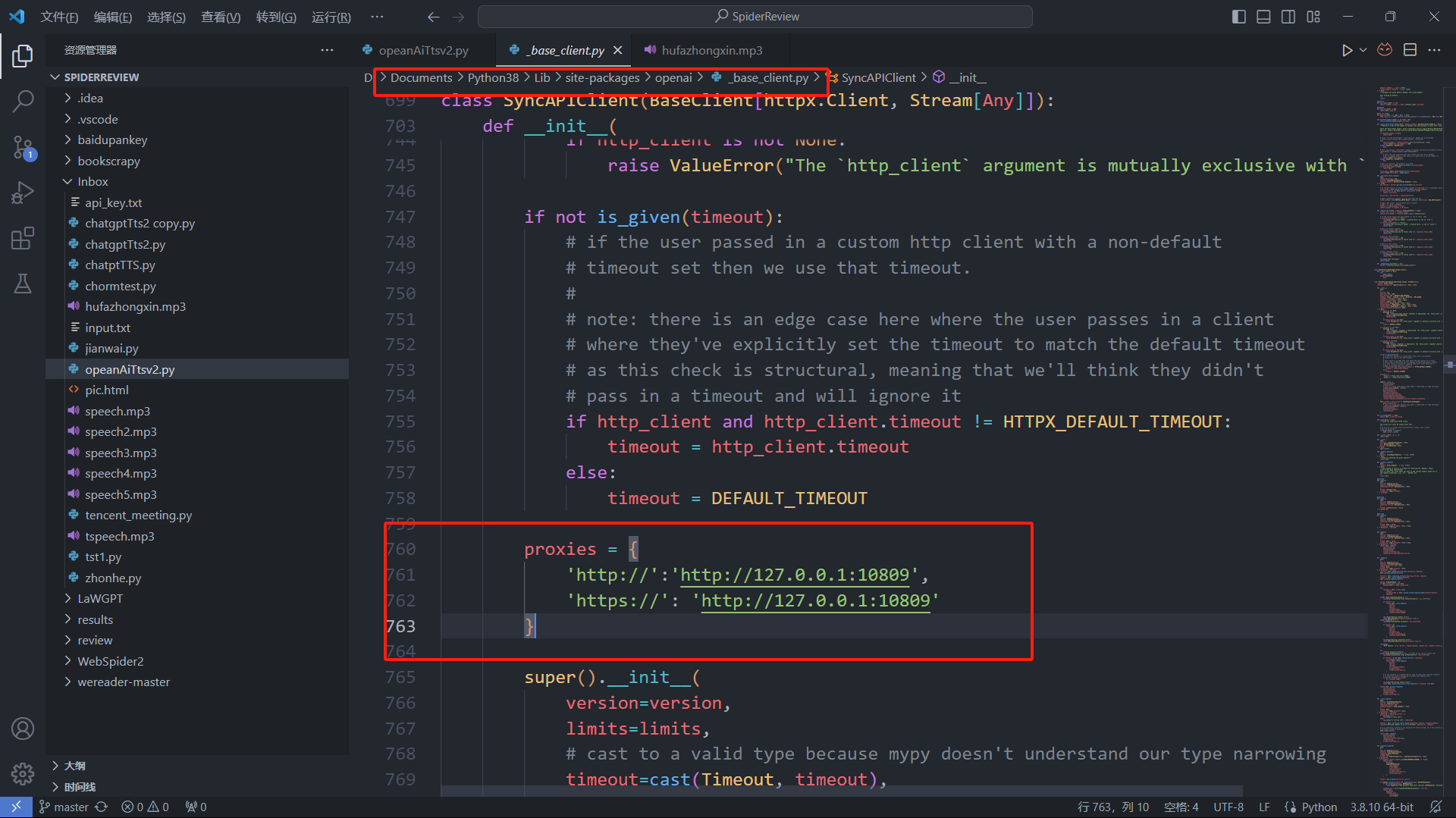
proxies = {
'http://':'http://127.0.0.1:端口',
'https://': 'http://127.0.0.1:端口'
}
运行编写好的Python脚本,根据需要提供相应的命令行参数,如API密钥、模型类型、声音类型和输入文本。
python your_script.py --api_key="your_api_key" --model="tts-1-hd" --voice="echo" --input_text="你好,世界!"
from pathlib import Path
from openai import OpenAI
client = OpenAI(api_key="your_api_key") # 此处属于你的api
speech_file_path = Path(__file__).parent / "speech.mp3" # 设置文件路径
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
) # 生成的文本内容,支持中文
response.stream_to_file(speech_file_path)
热门资讯







