
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 从一道Leetcode题目说起
首先,来看一下Leetcode里面的一道经典题目: 146.LRU缓存机制 ,题目描述如下:
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现
LRUCache类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。函数
get和put必须以O(1)的平均时间复杂度运行。
LRU 的全称是 Least Recently Used,也就是说我们认为最近使用过的数据应该是是「有用的」,很久都没用过的数据应该是无用的,内存满了就优先删那些很久没用过的数据。
要让 LRU 的
put
和
get
方法的时间复杂度为 O(1),可以总结出 LRU 这个数据结构必要的条件:
key
是否已存在并得到对应的
val
;
key
,需要将这个元素变为最近使用的,也就是说 LRU 要支持在任意位置快速插入和删除元素。
那么,什么数据结构同时符合上述条件呢?哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢。所以结合一下,形成一种新的数据结构:哈希链表
LinkedHashMap
。
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。这个数据结构长这样:
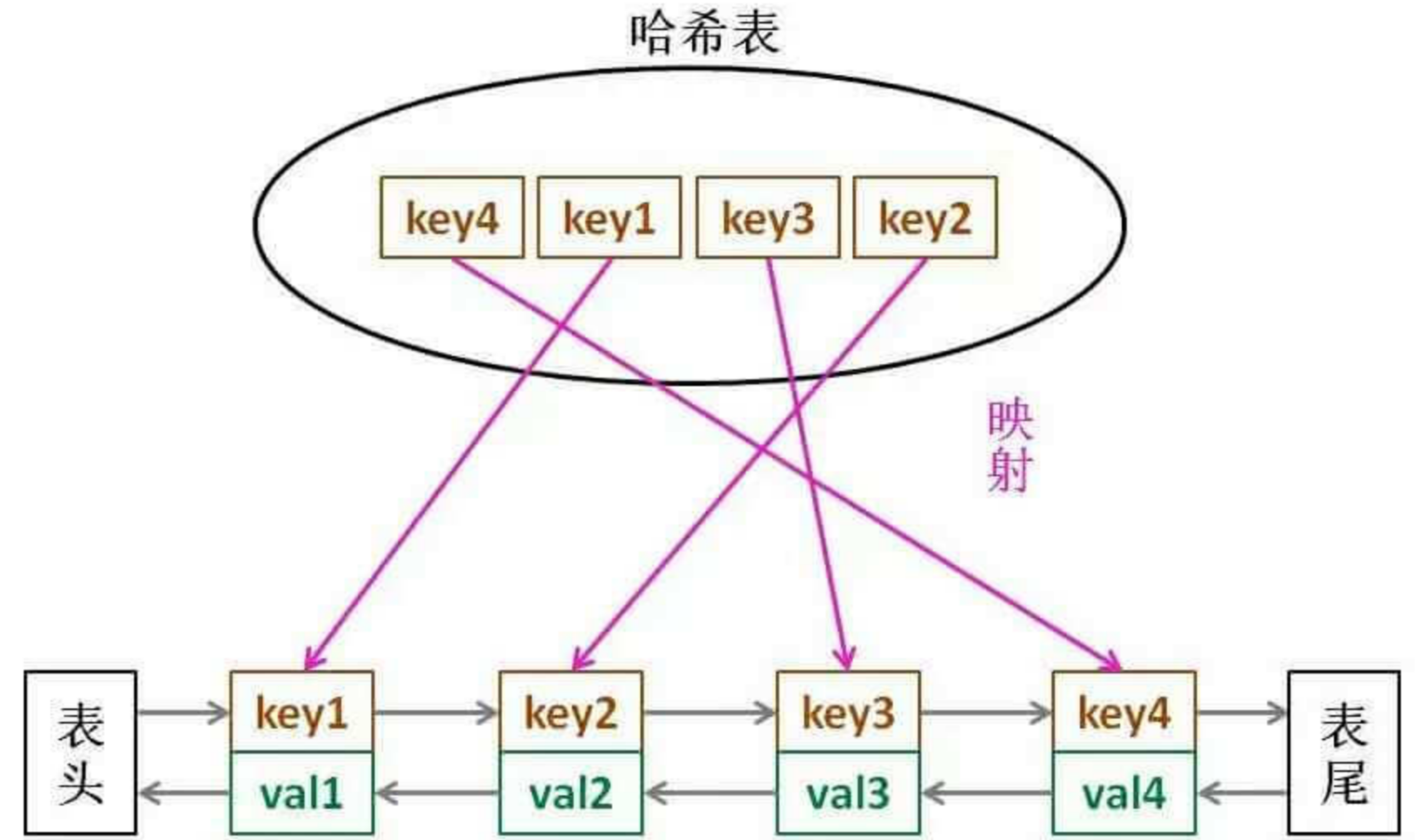
借助这个结构,逐一分析上面的 3 个条件:
key
,我们可以通过哈希表快速定位到链表中的节点,从而取得对应
val
。
key
快速映射到任意一个链表节点,然后进行插入和删除。
put方法流程图:
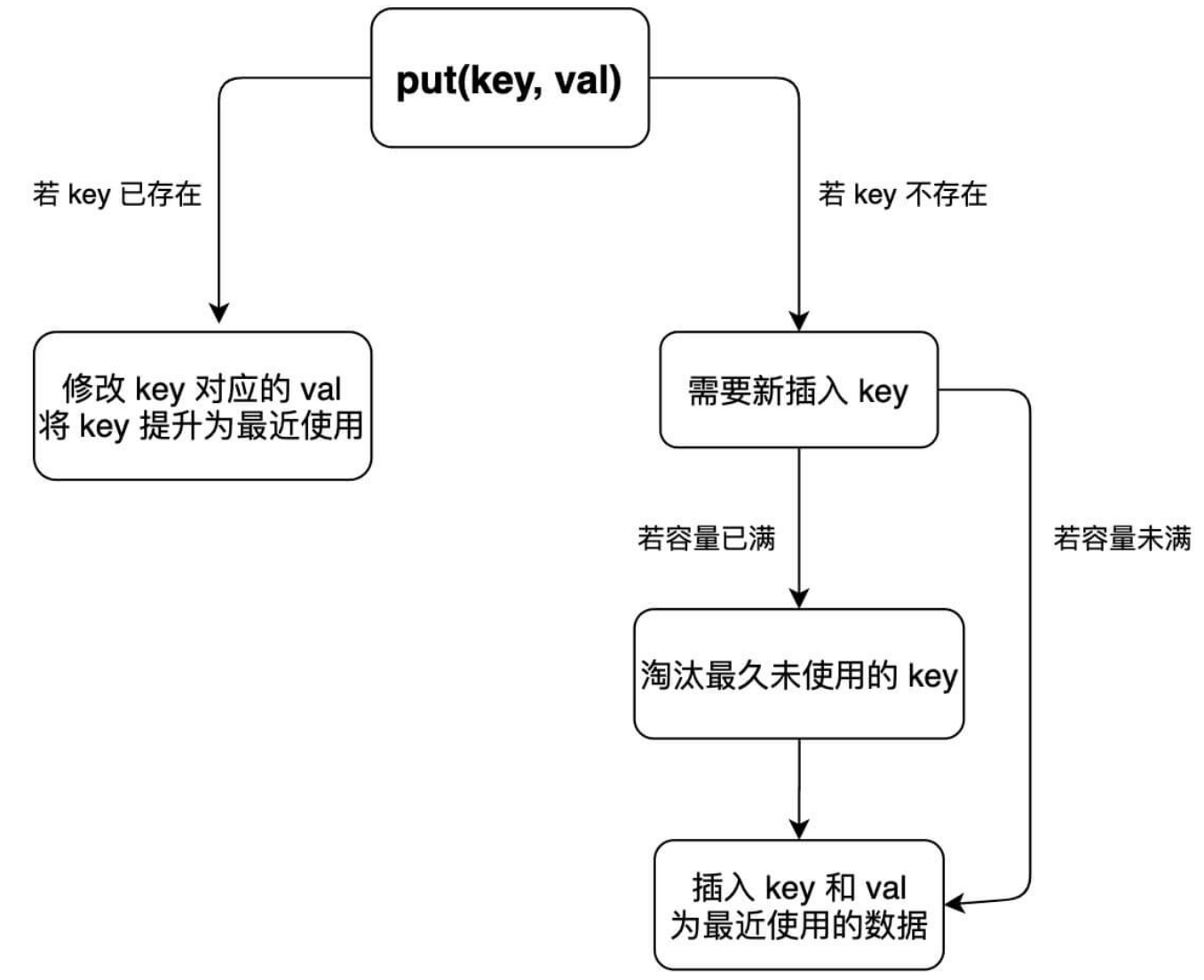
class LRUCache {
int cap;
LinkedHashMap cache = new LinkedHashMap<>();
public LRUCache(int capacity) {
this.cap = capacity;
}
public int get(int key) {
if (!cache.containsKey(key)) {
return -1;
}
// 将 key 变为最近使用
makeRecently(key);
return cache.get(key);
}
public void put(int key, int val) {
if (cache.containsKey(key)) {
// 修改 key 的值
cache.put(key, val);
// 将 key 变为最近使用
makeRecently(key);
return;
}
if (cache.size() >= this.cap) {
// 链表头部就是最久未使用的 key
int oldestKey = cache.keySet().iterator().next();
cache.remove(oldestKey);
}
// 将新的 key 添加链表尾部
cache.put(key, val);
}
private void makeRecently(int key) {
int val = cache.get(key);
// 删除 key,重新插入到队尾
cache.remove(key);
cache.put(key, val);
}
}
LinkedHashSet 和 LinkedHashMap 其实也是一回事。 LinkedHashSet 和 LinkedHashMap 在Java里也有着相同的实现,前者仅仅是对后者做了一层包装,也就是说 LinkedHashSet里面有一个LinkedHashMap(适配器模式) 。
LinkedHashMap 实现了 Map 接口,即允许放入key为null的元素,也允许插入value为null的元素。从名字上可以看出该容器是 linked list 和 HashMap 的混合体,也就是说它同时满足 HashMap 和 linked list 的某些特性。 可将LinkedHashMap看作采用linked list增强的 HashMap 。
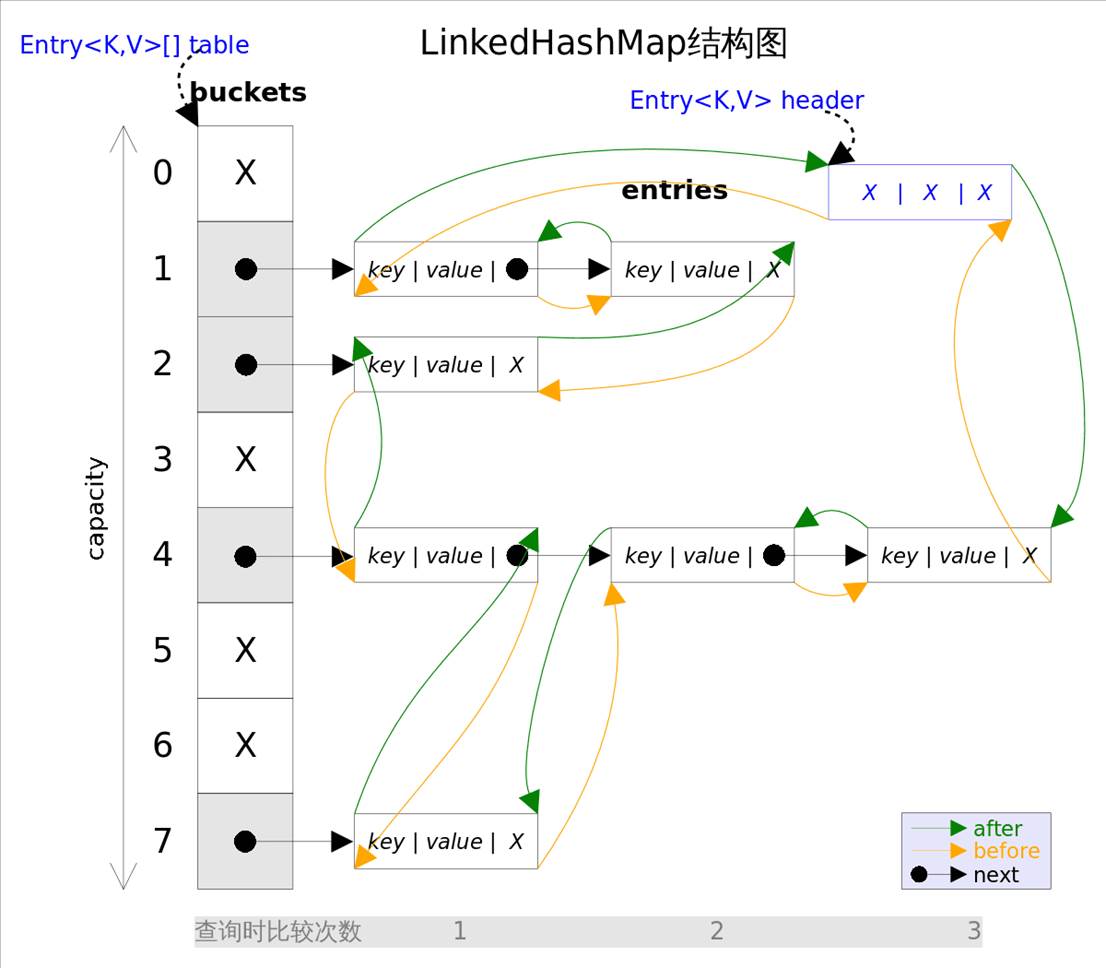
事实上 LinkedHashMap 是 HashMap 的直接子类, 二者唯一的区别是LinkedHashMap在HashMap的基础上,采用双向链表(doubly-linked list)的形式将所有entry连接起来,这样的好处:
可以保证元素的迭代顺序跟插入顺序相同 。跟 HashMap 相比,多了header指向双向链表的头部(是一个哑元), 该双向链表的迭代顺序就是entry的插入顺序 。
迭代LinkedHashMap时不需要像HashMap那样遍历整个table,而只需要直接遍历header指向的双向链表即可 ,也就是说 LinkedHashMap 的迭代时间就只跟entry的个数相关,而跟table的大小无关。
有两个参数可以影响 LinkedHashMap 的性能:初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。这点与 HashMap 是一样的
get(Object key)
方法根据指定的key值返回对应的value。该方法跟HashMap.get()方法的流程几乎完全一样
put(K key, V value)
方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于get()方法;如果没有找到,则会通过
addEntry(int hash, K key, V value, int bucketIndex)
方法插入新的entry。
注意,这里的 插入有两重含义 :
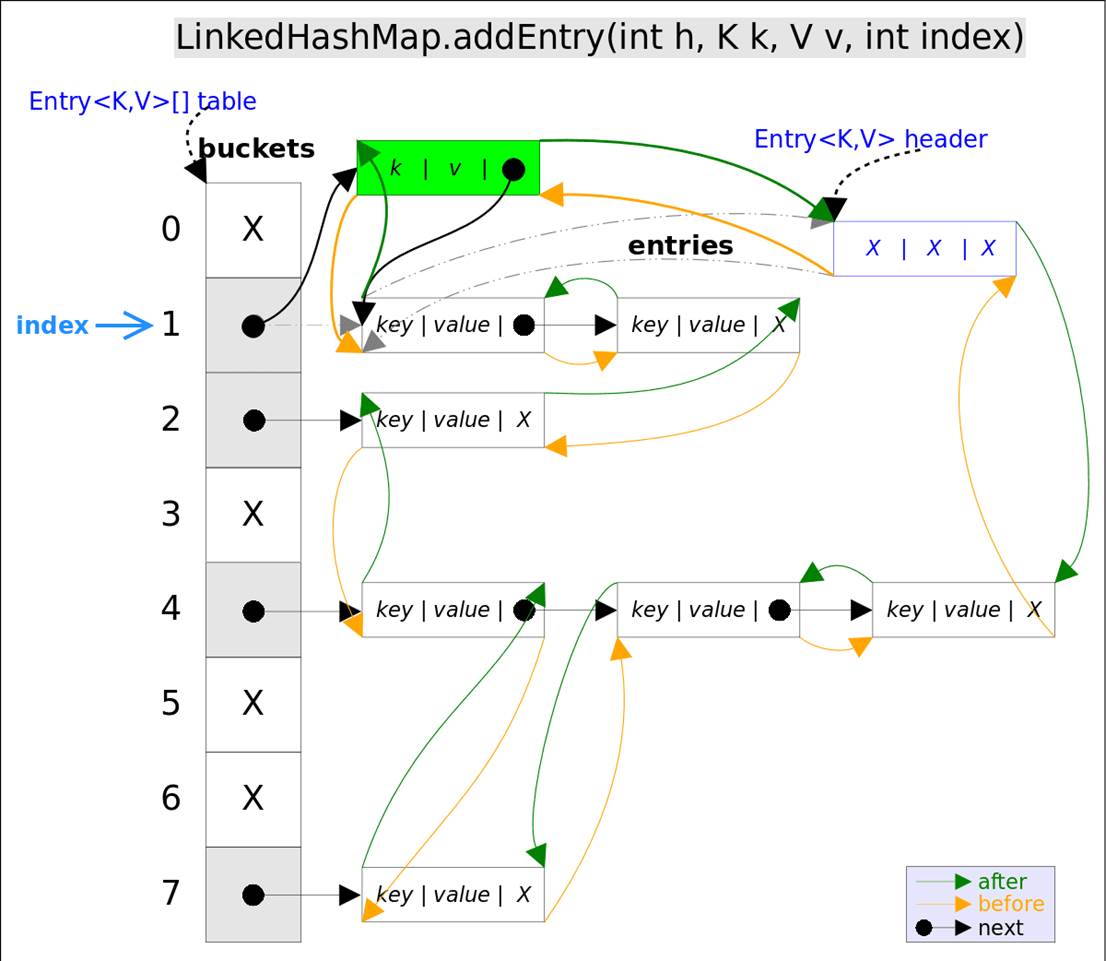
addEntry()代码如下:
// LinkedHashMap.addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在冲突链表头部插入新的entry
HashMap.Entry old = table[bucketIndex];
Entry e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在双向链表的尾部插入新的entry
e.addBefore(header);
size++;
}
上述代码中用到了addBefore()方法将新entry e插入到双向链表头引用header的前面,这样e就成为双向链表中的最后一个元素。addBefore()的代码如下:
// LinkedHashMap.Entry.addBefor(),将this插入到existingEntry的前面
private void addBefore(Entry existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟get()方法类似。
注意,这里的 删除也有两重含义 :
从table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。
从header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。
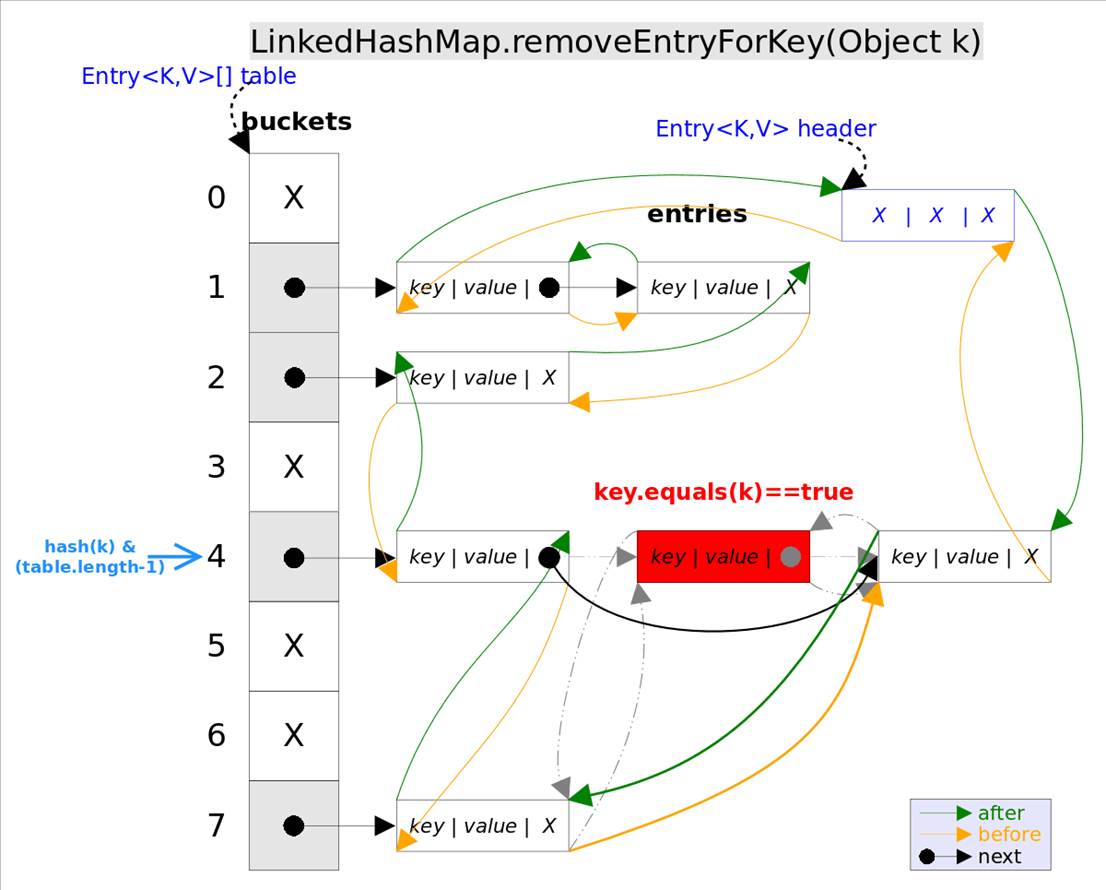
removeEntryForKey()对应的代码如下:
// LinkedHashMap.removeEntryForKey(),删除key值对应的entry
final Entry removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry prev = table[i];// 得到冲突链表
Entry e = prev;
while (e != null) {// 遍历冲突链表
Entry next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry
modCount++; size--;
// 1. 将e从对应bucket的冲突链表中删除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. 将e从双向链表中删除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}
LinkedHashSet是对LinkedHashMap的简单包装,对LinkedHashSet的函数调用都会转换成合适的LinkedHashMap方法,因此LinkedHashSet的实现非常简单
public class LinkedHashSet
extends HashSet
implements Set, Cloneable, java.io.Serializable {
......
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}
来自一线程序员Seven的探索与实践,持续学习迭代中~
本文已收录于我的个人博客: https://www.seven97.top
公众号:seven97,欢迎关注~
热门资讯







