
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版
不得不说,现在的计算机视觉技术已经发展到足够成熟的阶段了,还记得笔者刚工作的时候,相机标定还是个很神秘的技术,只有少数专业人员能够做,网上也找不到什么相关的资料。但是现在相机标定已经是一个非常普遍的技术了,也有不少的资料的可以参考,因此笔者突发奇想,既然那些大部头的相机可以标定,那么我们使用的手机摄像头一定也可以标定。因此,笔者就记录一下给自己手机摄像头的具体实践,算是弥补下当年没有学习到该技术的遗憾,毕竟要学习一项技术最好的办法就是亲自实践一下。
笔者见过不少正规的标定场,有的标定场很大,有很多带有标志物的竖条,还带有载动相机设备的轨道。不过目前比较流行且成本最低的办法就是使用棋盘格标定板了,也就是所谓的张正友标定法。
那么棋盘格标定板哪里来呢?打印到纸上倒是一个办法,不过可能有两个问题,一个是打印后每个格子的尺寸需要换算一下,由像素换成米制单位,这可能不是一个整数;另一个就是得找一面墙来贴上去,要贴的光滑平整还是挺难的。因此笔者没有选择这个办法,最后还是通过网上购物找的标定板。由于是给手机摄像头传感器尺寸都不是太大,标定板也不用选择太大,笔者最终选用的标定板尺寸如下所示:
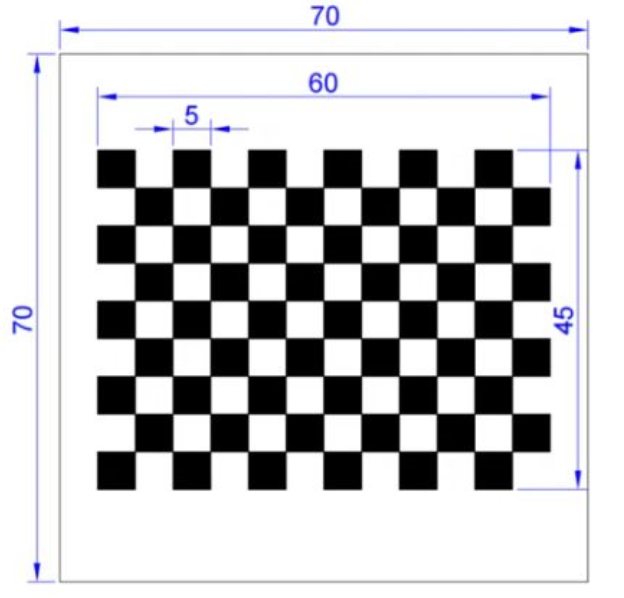
每个格子是5毫米,一共12X9个格子,整体尺寸还是比较小巧的,大概就一个手掌心大小。材质是玻璃基板,成本大概是50元左右。这个尺寸笔者实际体验还是有点偏小的,不过再大成本就上来了,建议有财力的同学可以适当选择大一点。
接下来就是用手机摄像头对棋盘格标定板进行拍摄了。理论上进行标定解算只需要6组控制点就可以了,但是因为识别的控制点都是有误差的,需要多组点位来进行求解以提升精度。只拍摄一张照片获得的控制点也不太够,通常还需要获取多张照片上的控制点,避免局部最优的问题,提高解算过程的可靠性。如果可以的话,要使用多个视角、多个不同距离的标定板照片,同时最好保证标定板覆盖整个图像平面的不同区域,这样可以更好地估计畸变和其他参数。
在这里笔者拍摄了6张棋盘格标定板的图片,分别是前、后、左、右、上、下6个不同的位置和视角,如下所示:
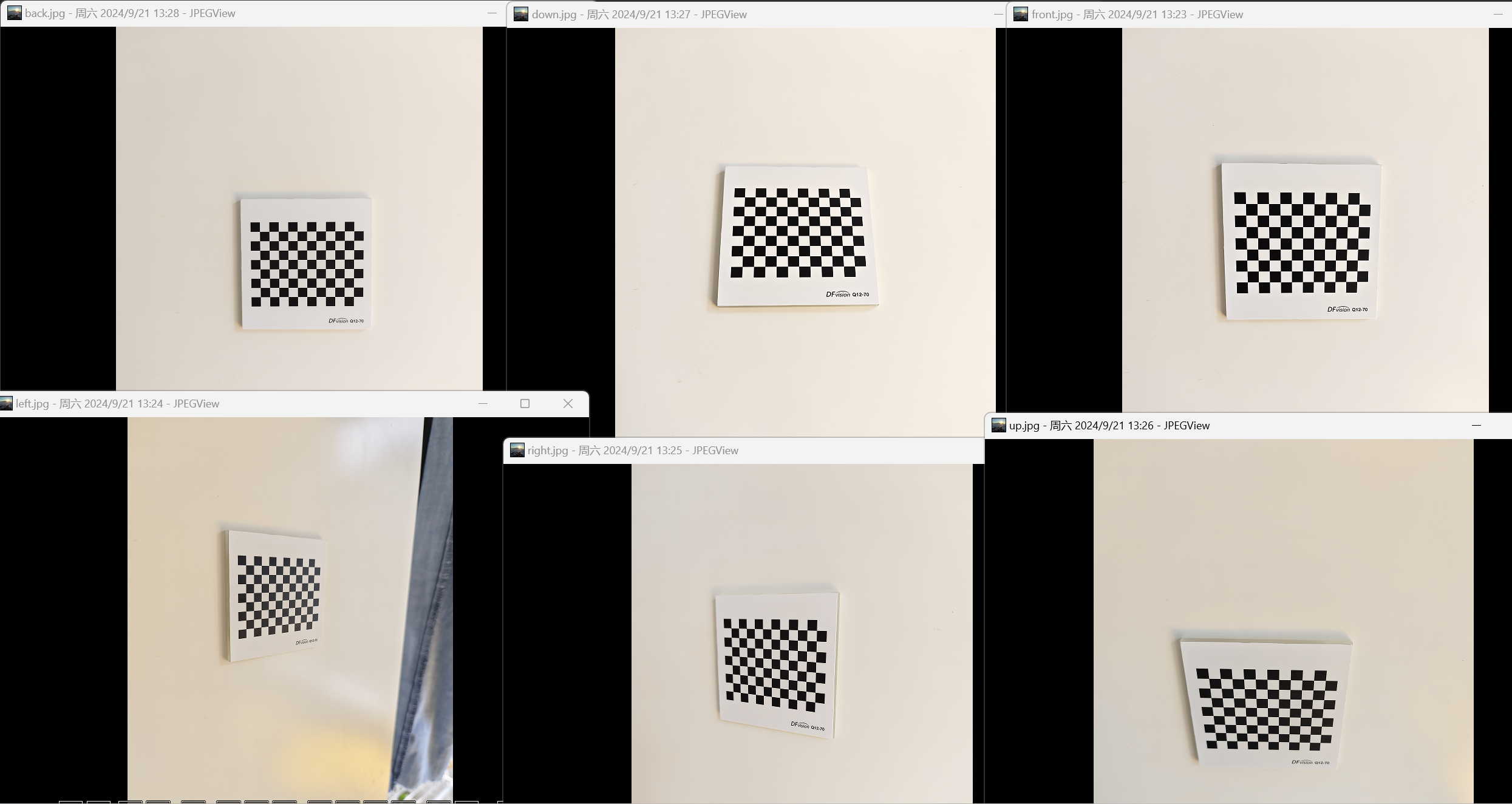
可以看到拍摄的标定板区域都太靠中间了,不过也是没办法,使用的标定板尺寸确实有点偏小。拍摄的时候一旦靠的很近,手机拍照程序就会自动切换成近景拍摄。笔者不太确定切换成近景拍摄之后会不会修改相机的参数,所以都没有靠的很近。但是太远了拍照又有点糊,只能使用目前这样的效果。
现在很多手机拍照的功能会自动修正照片,比如滤镜,广角矫正等等,这些功能都尽量关了或者不使用。另外,拍照过程不要进行调焦,具体来说相机上会有0.6x、1x、2x、3x这样的参数,这代表变焦倍率,使用原始倍率(1x)进行标定即可。自动对焦功能当然也要关闭,保持镜头和焦平面的位置不变。
还有个问题是保持手机不动移动标定板来拍摄照片,还是保持标定板不动移动手机来拍摄照片?应该来说,两者原理上都可以实现,但是标定板不动,相机移动更常见一点,因为实现起来更见简单。笔者就是将棋盘格标定板通过双面胶粘在墙上实现的,也算是组成了一个成本最低的微型标定场了。
其实笔者也试过将标定板放在桌面上来拍摄,不过在室内拍摄很容易在照片上有影子,还是固定在墙上比较好一点。而且最好放采光比较好的墙面上,在白天日照充足的时候进行拍摄,以便获得最好的拍摄效果。
相机标定虽然解算的是内参,但是其实连外参也解算了,因为相机标定解算使用的相机成像原理,这个过程中内参和外参会一起参与解算。在不考虑畸变的情况下,相机的成像原理可用下式(1)来表示:
在这个式子中:
以笔者的见识来说,上述相机成像原理其实与其他学科的一些知识有类似的地方:
计算机图形学。图形渲染中的几何变换,包含模型(model)变换、视图(view)变换和投影(projection)变换 ,合起来就是通常所说的MVP矩阵。模型变换包括旋转变换和平移变换,视图变换又是模型变换的逆变换,对应的就是式(1)的外参矩阵 \(\begin{bmatrix}R|t\\\end{bmatrix}\) 。不过投影矩阵有所不同,式(1)的内参矩阵 \(K\) 是将点从相机坐标系转换为图像坐标系,图形渲染中的投影矩阵则是将点从将点从相机坐标系转换为裁剪坐标系。
摄影测量学。在摄影测量学中,这一套成像原理的公式被总结为共线方程,除了表示的形式不同,最显著的不同是内参只有三个:焦距和像主点二维坐标。这个公式个人认为并不太直观,但是比较容易进行平差计算。
如果有以上两者经验的读者,可以对照着进行理解,虽然它们看起来有点差异,但是笔者确定它们的原理都是一样的,都是基于空间的几何变换,只不过是应对于不同情况有不同的描述。
以上成像原理没有考虑到畸变的影响。为什么会产生畸变呢?很简单,相机镜头不是完美的平面光学系统,光线在传输时发生复杂的弯曲,这会导致图像中的直线在图像边缘发生扭曲。常见的畸变有径向畸变和切向畸变。
畸变校正看起来很玄乎,其实说穿了也非常简单,我们只需要理解一点,畸变校采用的有理函数的模型。所谓有理函数的模型,就是将校正前的位置x与校正后的位置y使用一个高阶多项式(形如 \(y=ax^3+bx^2+cx+d\) )来进行表示,没有什么物理上的原理,就是纯采用数学方式进行拟合,最后得到了每个高阶项的系数(a,b,c,d)。
鉴于畸变校正会增加对标定解算的复杂度,这里就不进行进一步论述了。对于初学者来说,理解成像原理的公式(1)更为关键一点。
使用上述介绍的基本原理就可以进行标定解算了,不过解算方法比较复杂,我们还是结合具体的实现来解释,代码如下所示,这里主要使用了OpenCV库:
#include
#include
#include
#include
#ifdef _WIN32
#include
#endif
using namespace cv;
using namespace std;
int main() {
#ifdef _WIN32
SetConsoleOutputCP(65001);
#endif
vector imgPaths = {
"C:/Work/CalibrateCamera/Data/front.jpg",
"C:/Work/CalibrateCamera/Data/left.jpg",
"C:/Work/CalibrateCamera/Data/right.jpg",
"C:/Work/CalibrateCamera/Data/up.jpg",
"C:/Work/CalibrateCamera/Data/down.jpg",
"C:/Work/CalibrateCamera/Data/back.jpg"};
size_t imageNum = imgPaths.size();
// 定义棋盘格尺寸 (内角点数)
int boardWidth = 11; // 列数
int boardHeight = 8; // 行数
cv::Size boardSize(boardWidth, boardHeight);
double cellSize = 0.005;
Size imageSize(3072, 4096); // 图像尺寸
// 准备标定所需的物方点和像方点
vector> objectPoints(imageNum); // 多张图像的3D物方点
vector> imagePoints(imageNum); // 多张图像的2D像方点
for (size_t ii = 0; ii < imageNum; ++ii) {
// 加载棋盘格图像
cv::Mat image = cv::imread(imgPaths[ii].string().c_str());
if (image.empty()) {
std::cerr << "Error: Could not load image!" << std::endl;
return -1;
}
// 存储角点坐标
std::vector corners;
// 转换图像为灰度
cv::Mat grayImage;
cv::cvtColor(image, grayImage, cv::COLOR_BGR2GRAY);
// 寻找棋盘格角点
// cv::CALIB_CB_ADAPTIVE_THRESH | cv::CALIB_CB_NORMALIZE_IMAGE
bool found = cv::findChessboardCorners(grayImage, boardSize, corners,
cv::CALIB_CB_FAST_CHECK);
// 如果找到角点,进行进一步处理
if (found) {
std::cout << "Chessboard corners found!" << std::endl;
// 增加角点的精度
cv::cornerSubPix(
grayImage, corners, cv::Size(11, 11), cv::Size(-1, -1),
cv::TermCriteria(cv::TermCriteria::EPS + cv::TermCriteria::MAX_ITER,
30, 0.001));
// 绘制角点
std::string cornerImgPath = imgPaths[ii].parent_path().generic_string() +
"/corner/" + imgPaths[ii].stem().string() +
"_corner" + imgPaths[ii].extension().string();
cv::drawChessboardCorners(image, boardSize, corners, found);
cv::imwrite(cornerImgPath.c_str(), image);
cout << corners.size() << endl;
imagePoints[ii].resize(corners.size());
for (size_t ci = 0; ci < corners.size(); ++ci) {
imagePoints[ii][ci] = corners[ci];
}
objectPoints[ii].resize(corners.size());
for (int hi = 0; hi < boardHeight; ++hi) {
for (int wi = 0; wi < boardWidth; ++wi) {
int ci = hi * boardWidth + wi;
objectPoints[ii][ci].x = cellSize * wi;
objectPoints[ii][ci].y = cellSize * hi;
objectPoints[ii][ci].z = 0;
}
}
} else {
std::cerr << "Chessboard corners not found!" << std::endl;
}
}
// 内参矩阵和畸变系数
Mat cameraMatrix = Mat::eye(3, 3, CV_64F); // 初始化为单位矩阵
Mat distCoeffs = Mat::zeros(8, 1, CV_64F); // 初始化为零
// 外参的旋转和位移向量
vector rvecs, tvecs;
// 执行标定
double reprojectionError =
calibrateCamera(objectPoints, imagePoints, imageSize, cameraMatrix,
distCoeffs, rvecs, tvecs);
cout << u8"重投影误差:" << reprojectionError << endl;
cout << u8"内参矩阵:" << cameraMatrix << endl;
cout << u8"畸变系数:" << distCoeffs << endl;
return 0;
}
代码实现的步骤很简单,就是通过函数
findChessboardCorners
提取棋盘格图片的角点,将其传入
calibrateCamera
函数中,就得到了最终的解算成果,也就是内参矩阵。这其中的关键就在于
calibrateCamera
这个函数,我们可以看一下它的函数原型:
CV_EXPORTS_W double calibrateCamera( InputArrayOfArrays objectPoints,
InputArrayOfArrays imagePoints, Size imageSize,
InputOutputArray cameraMatrix, InputOutputArray distCoeffs,
OutputArrayOfArrays rvecs, OutputArrayOfArrays tvecs,
int flags = 0, TermCriteria criteria = TermCriteria(
TermCriteria::COUNT + TermCriteria::EPS, 30, DBL_EPSILON) );
其参数详解如下:
std::vector>
。
std::vector>
。
std::vector
。
std::vector
。
通过对
calibrateCamera
函数的解析,相信读者就很容易明白为什么笔者要先讲公式(1)的成像原理。这个解算参数的输入输出都是根据公式(1)来的,不过另一个问题来了,输入的物方点和像方点是怎么来的呢?
答案很简单,就是棋盘格上的角点。棋盘格由黑白相间的格子组成,所以它的角点是很容易提取的;另外一方面,棋盘格也是规整的,只要每个格子的尺寸都是一样,就很容易知道物方坐标。理论上,只要对图像提取角点,然后剔除掉非棋盘的角点就可以作为相机标定的像点了。不过,OpenCV提供了更进一步的接口
findChessboardCorners
,直接输入棋盘格的内角点个数,就可以自动检测出像点。如下图所示在一张图片上笔者提取的像点:

正如上图所示,
findChessboardCorners
提取的是内角点,例如12X9的棋盘格,提取的内角点是11X8个,并且结果是按照从左到右,从上往下进行排序的。为什么要这么排序呢?因为很容易帮我们算出物方点。在相机标定这个应用中,相机的外参是不重要的,因此我们可以就以棋盘格标定板的左上角作为世界坐标系的原点,第1个点的坐标是(0,0,0),第2个点的坐标是(0.005,0,0),第3个点坐标是(0.010,0,0)...第12个点坐标是(0,0.005,0),第13个点坐标是(0.005,0.005,0)...就这么依次类推得到所有角点对应的世界空间坐标系坐标。
另外一点要提醒读者的是,
findChessboardCorners
这里我配置的是参数是cv::CALIB_CB_FAST_CHECK,是一种快速算法,cv::CALIB_CB_ADAPTIVE_THRESH和cv::CALIB_CB_NORMALIZE_IMAGE会对图像作预处理,能够增加提取棋盘格角点的稳健性。但是我实际使用发现程序卡住了,不知道是效率很低还是OpenCV的问题,就没有使用这两个选项。
最终,笔者的结算结果如下所示:
重投影误差:0.166339
内参矩阵:[2885.695162446343, 0, 1535.720945173723;
0, 2885.371543143629, 2053.122840953737;
0, 0, 1]
畸变系数:[0.181362004467736;
-3.970106972775221;
0.0005157812878172198;
0.0004644406171824815;
23.559069196518]
解算的结果重投影误差是0.166339,表示每个物体点在重新投影到图像上时与实际检测到的角点位置的误差为0.166339像素。通常来说,这样的误差已经算是非常小,表明标定结果较为精确。
不过笔者还考虑一个问题,误差为0.166339像素,那么具体是多少米呢?以前做测绘软件的时候,平差的结果也是以像素为单位,总会有客户对我发起灵魂拷问:那具体是多少米呢?这次笔者也关注了一下这个问题,个人认为在相机标定这样的应用场景,确实无法直接使用物理单位表示精度,因为这个算法的结果就在于重投影到图像上的像素差为量度,这一点与相机外参的定向的误差量度有所不同。
对照内参矩阵,可得解算的焦距是 \(f_x=2885.695\) 和 \(f_y=2885.372\) ,单位也是像素。那么这个焦距换算成物理单位是多少米呢?根据笔者查找的资料显示,焦距在像素和毫米之间的转换公式如下所示:
也就是说与相机传感器尺寸有关,不过关于传感器尺寸的描述有点蛋疼,比如网上显示我手机摄像头的传感器是1/1.49英寸,这通常表示传感器的对角线长度。可以根据对角线长度加上宽高比(例如4:3还是16:9)算出相机传感器的物理尺寸,进而知道具体物理单位的焦距值大小。不过传感器的对角线长度标称值和真实物理尺寸之间,会因为行业惯例和历史标准有所差异,所以算出来的也不一定正确,最好还是联系官方来确定。不过,标定出像素单位的焦距已经足够后续满足后续的使用场景了,笔者这里也就是寻根究底一下。
最后,补充一些没搞定或者暂时没理解的问题吧:
列出一些文章以供参考:
本文源代码和数据地址
热门资讯







