
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 本篇参考:
https://trailhead.salesforce.com/content/learn/trails/drive-productivity-with-einstein-ai
https://help.salesforce.com/s/articleView?id=sf.generative_ai_trust_layer.htm&type=5
https://blog.salesforceairesearch.com/meet-salesforces-trusted-ai-principles/
https://trailhead.salesforce.com/einstein-ai-trail/
https://trailhead.salesforce.com/content/learn/modules/large-language-models
序言
今年的DreamForce,salesforce针对AI进行更强的推广,针对salesforce从业者来说,AI两个证书免费考试。未来几篇博客主要针对Salesforce AI Specialist证书的考点知识进行讲解,更好的了解Einstein的功能以及如何通过Salesforce AI 更好的赋能我们的企业。虽然前两天考试挂了,很可惜只差一道题,但是感觉里面内容有一些很有趣并且以后有可能会用得到,预计会开几篇内容,根据AI Specialist的主要Topic进行博客的制作。没有题库,不用私聊/留言问题库问题。
本篇所针对的内容是 Einstein Trust Layer,让我们一起了解一下Salesforce如何通过AI进行赋能以及如何解决数据隐私,数据安全等痛点的。
Einstein 生成式AI术语介绍
| 术语 | 描述 |
| Artificial intelligence (AI) | 计算机科学的一个分支,计算机系统使用数据进行推理、执行任务并以类似人类的推理方式解决问题 |
| Bias 偏见 | 由于机器学习过程中的假设不准确,计算机系统中的系统性和可重复性错误会以与系统预期功能不同的方式产生不公平的结果。 |
| Corpus 语料库 | 用于训练LLM的大量文本数据集。 |
| Domain adaptation 领域适应 | 将特定组织的知识添加到提示(Prompt)和基础模型中的过程。 |
| Fine-tuning 微调 | 通过在较小的特定于任务的数据集上进行训练,使预先训练的语言模型适应特定任务的过程。 |
| Generative AI gateway 生成式人工智能网关 | 该网关公开标准化的 API,以便与内部和合作伙伴生态系统中不同供应商提供的基础模型和服务进行交互 |
|
Generative Pre-Trained Transformer (GPT)
生成式预训练 Transformer (GPT) |
一系列语言模型,经过大量文本数据的训练,以便生成类似人类的文本。 |
| Grounding 接地 | 将特定领域的知识和客户信息添加到提示中的过程,为模型提供更准确响应所需的上下文。 |
| Hallucination 幻觉 | 但在给定上下文的情况下,该模型输出的文本实际上不正确或几乎没有意义 |
|
Large language model (LLM)
大语言模型( LLM ) |
一种语言模型,由神经网络组成,该神经网络具有经过大量文本训练的许多参数。 |
| Machine learning 机器学习 | 人工智能的一个子领域,专门研究计算机系统,旨在根据数据的反馈和推断而不是明确的指令来学习、适应和改进。 |
|
Natural Language Processing (NLP)
自然语言处理(NLP) |
人工智能的一个分支,利用机器学习来理解人类书写的语言。大型语言模型是 NLP 的众多方法之一。 |
| Prompt提示 | 对要完成的任务的自然语言描述。 LLM的输入。 |
| Prompt chaining 提示链 | 将复杂任务分解为几个中间步骤,然后将其重新组合在一起的方法,以便人工智能生成更具体、定制和更好的结果。 |
| Prompt design 提示 设计 | 提示设计是创建提示的过程,可提高模型响应的质量和准确性。许多模型都需要特定的提示结构,因此在您使用的模型上测试和迭代它们非常重要。了解哪种结构最适合模型后,您可以针对给定用例优化提示。 |
| Prompt injection提示注入 | 一种通过给予模型某些提示来控制或操纵模型输出的方法。通过这种方法,用户和第三方尝试绕过限制并执行模型未设计的任务 |
| Prompt instructions 提示指示 | 提示指令是输入到提示模板中的自然语言指令。您的用户只需向 Einstein 发送指令即可。说明具有动词-名词结构和LLM任务,例如“撰写不超过 500 个字符的描述”。您的用户指令将添加到应用程序的提示模板中,然后相关的 CRM 数据将替换模板的占位符。提示模板现在是一个接地提示并发送到LLM 。 |
| Prompt template 提示模板 | 带有占位符的字符串,这些占位符将替换为业务数据值,以生成发送到LLM最终文本指令。 |
|
Retrieval-augmented generation (RAG)
检索增强生成 (RAG) |
一种基础形式,使用知识库等信息检索系统来丰富相关上下文的提示,以进行推理或训练。 |
| Semantic retrieval 语义检索 | 允许LLM使用客户 CRM 数据中存在的类似且相关的历史业务数据的场景。 |
| Toxicity 毒性 | 描述多种类型话语的术语,包括但不限于冒犯性、不合理、不尊重、令人不快、有害、辱骂或仇恨的语言。 |
| Trusted AI 可信人工智能 | Salesforce 创建的指南专注于负责任的 AI 开发和实施。 |
Einstein Trust Layer
我们以下方的demo来引出今天的主题。下方的gif是通过Email 选择指定的Prompt Template(后续会讲到) 然后基于gpt4生成的内容,那么从选择到数据生成返回到salesforce,都经历了哪些过程呢?
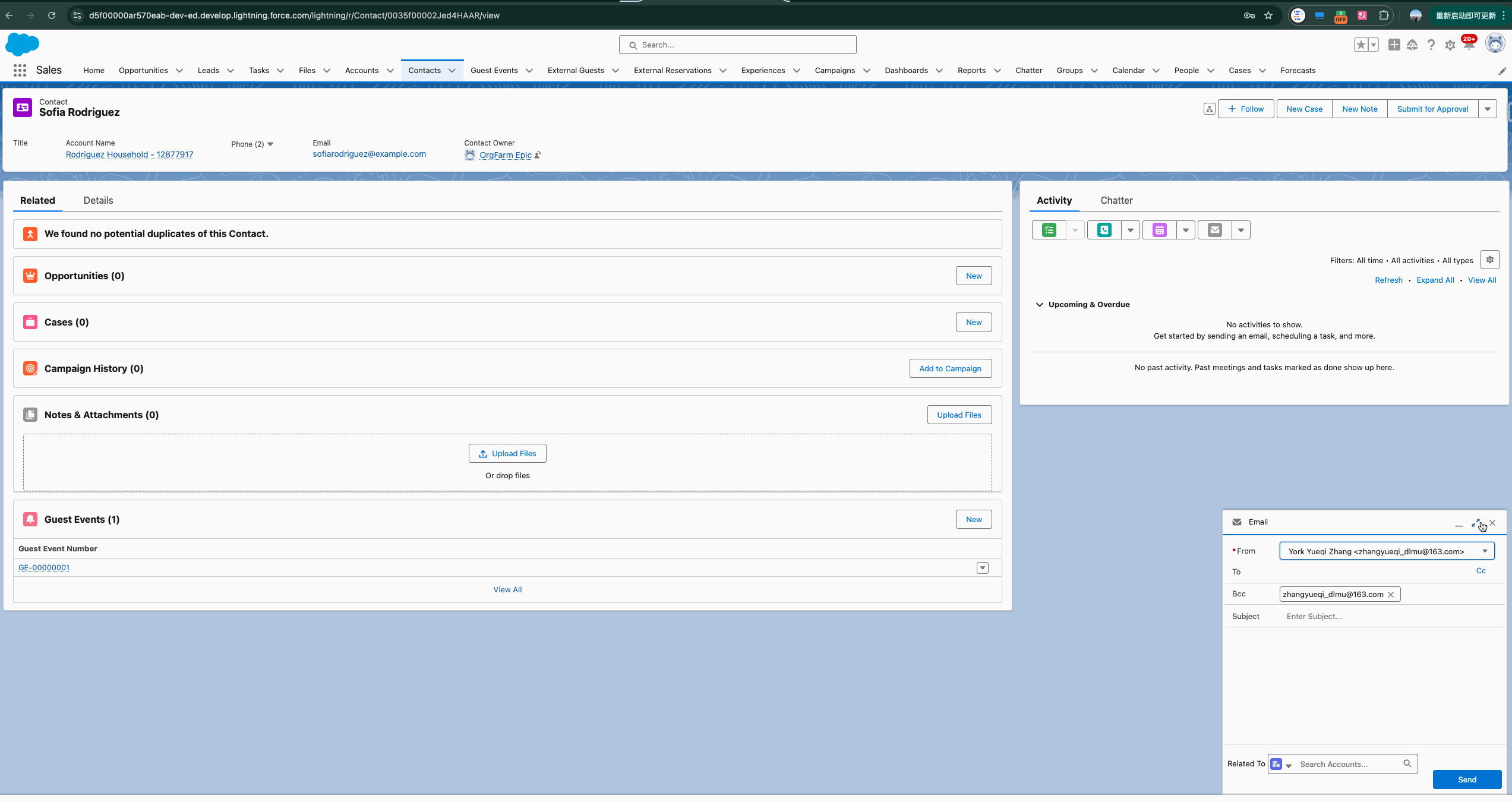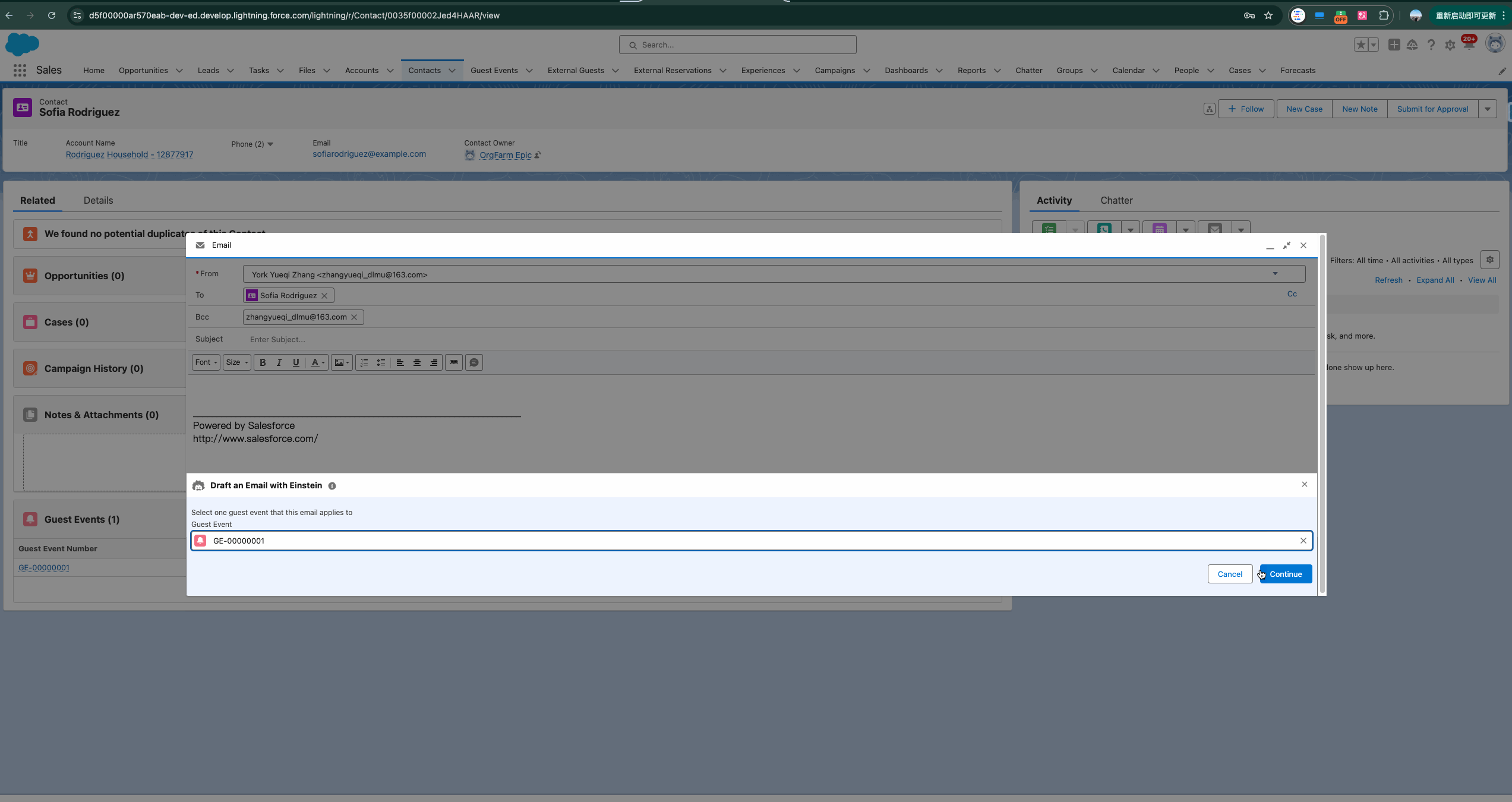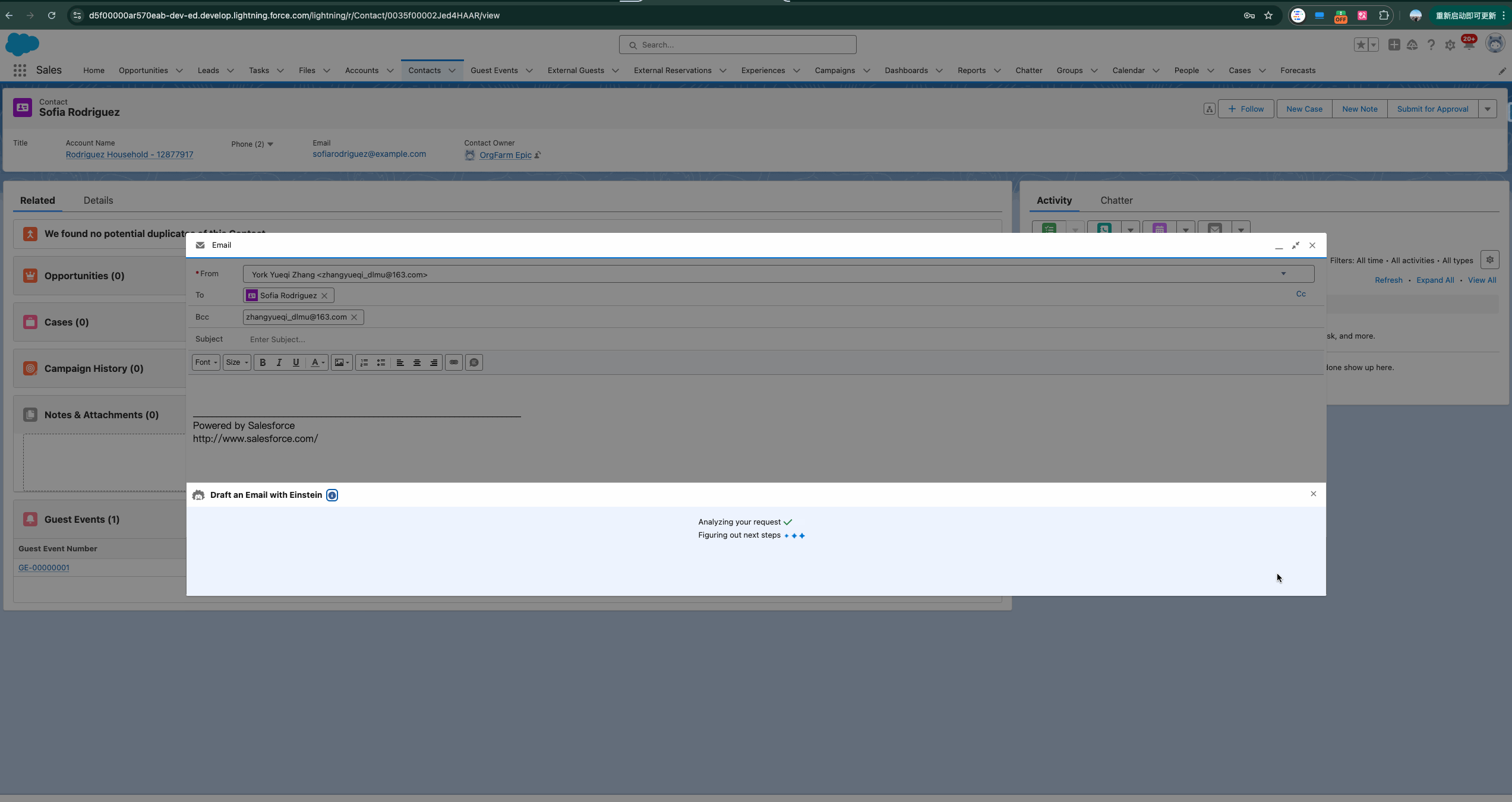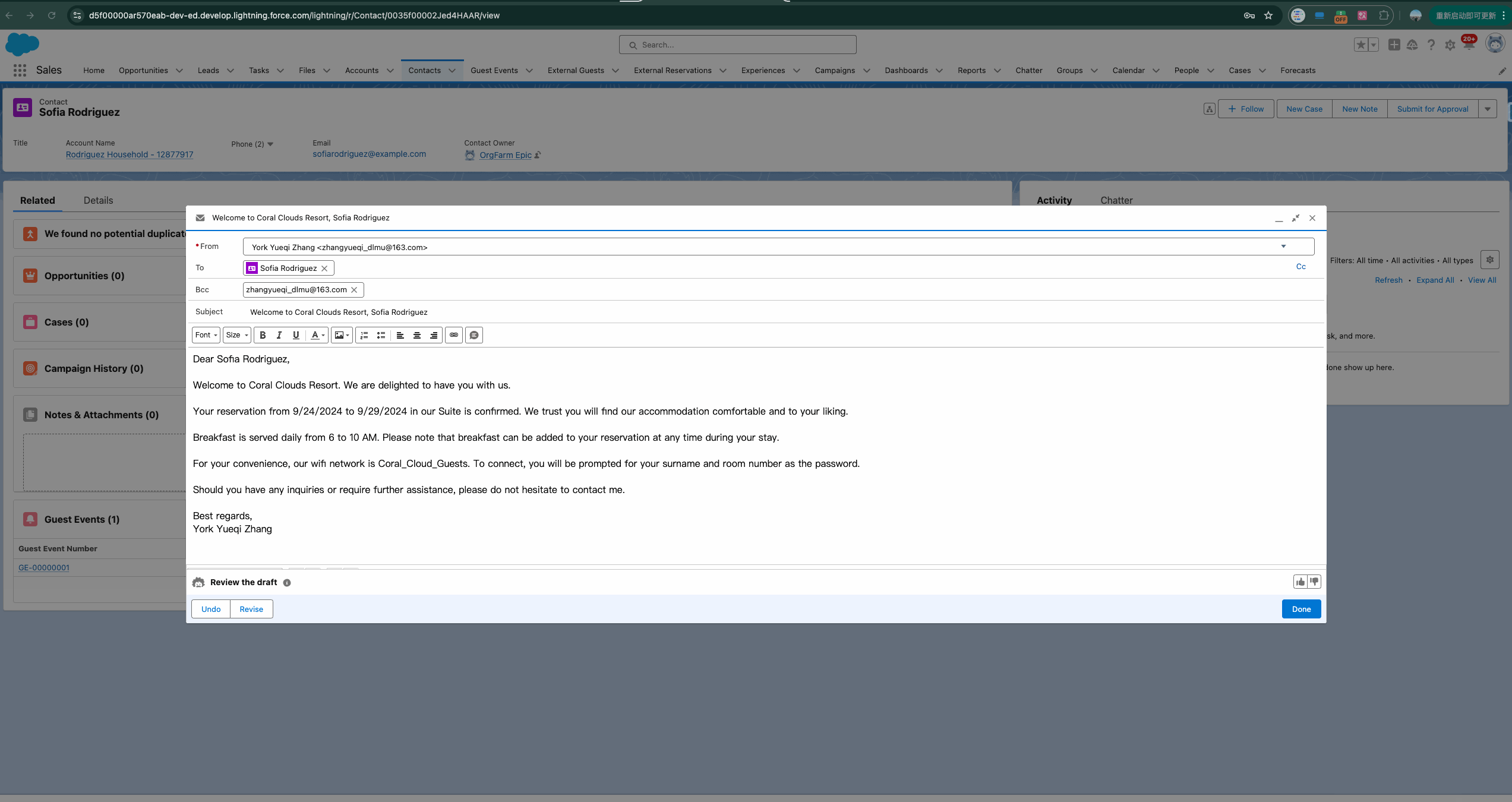
1. Secure Data Retrieval & Grounding 安全数据检索和接地 : 为了让LLM生成更具相关性和个性化的响应,它需要来自 CRM 数据的额外上下文。这个向Prompt提示添加额外上下文的过程就是我们所说的Grounding接地。我们可以使用将字段与 CRM 数据合并merge来建立Prompt提示,这些字段可以是record fields, flows, Apex, Data Cloud DMOs, and related lists。简单来说,接地我们可以理解成prompt template中使用merge field/placeholder进行额外的上下文。
安全数据检索意味着Prompt仅基于执行用户有权访问的数据,当我们使用接地,比如 record fields或者related lists,通过安全数据检索,我们可以保证仅基于执行用户有权访问的数据。数据检索过程遵循 Salesforce 中的现有访问控制和权限:
2. Data Masking for the LLM LLM的数据屏蔽 :Einstein 信任层会识别并屏蔽提示中选定的个人身份信息 (PII) 和支付卡行业 (PCI) 数据,然后将其发送到大型语言模型 ( LLM )。数据屏蔽可防止您的敏感数据暴露给LLM ,并将您的敏感 CRM 数据安全地存储在 Salesforce 内。使用模式和上下文来识别敏感数据。然后使用占位符文本屏蔽数据,以防止数据暴露给外部模型。 Einstein Trust Layer 临时存储原始实体及其各自占位符之间的关系。该关系稍后用于对生成的响应中的数据进行解密。此步骤和后续的 Data Demasking相关联。我们也可以使用audit trail来跟踪数据脱敏并查看脱敏数据。audit trail存储在数据云中。除了常规的PII以及PCI字段,salesforce也支持自定义的一些敏感字段的加密/屏蔽。
需要先启用Einstein Generative AI 以及 Data Masking,之后搜索 Einstein Trust Layer便可以进行操作。
我的dev环境没有此项功能,所以没有相关截图。详情参考: https://help.salesforce.com/s/articleView?id=sf.generative_ai_mask_select.htm&type=5
3. Prompt Defense: To help decrease the likelihood of the LLM generating something unintended or harmful, Prompt Builder and Prompt Template Connect API use system policies. System policies are a set of instructions to the LLM for how to behave in a certain manner to build trust with users. For example, we can instruct the LLM to not address content or generate answers that it doesn’t have information about. System policies are one way to defend against jailbreaking and prompt injection attacks.
提示 防御: 为了帮助降低LLM生成意外或有害内容的可能性,提示生成器和提示模板连接 API 使用系统策略。系统策略是针对LLM如何以某种方式行事以建立与用户的信任的一组指令。例如,我们可以指示LLM不要处理其没有信息的内容或生成答案。系统策略是防御越狱和提示注入攻击的一种方法。
4. LLM Gateway & Zero Data Retention: 在salesforce端的步骤已经准备完成,接下来 Response Generation 响应生成环节。在提示完成敏感信息保护后,就可以通过LLM网关发送。该网关管理与不同模型提供商的交互,并代表与多个LLMs进行通信的统一、安全的方式。网关和模型提供商使用 TLS 加密来确保数据在传输过程中的安全。Salesforce与外部合作伙伴模型提供商(例如 OpenAI 或 Azure Open AI)制定了零数据保留政策。该策略规定,从 Salesforce 发送到LLM数据不会保留,而是在响应发送回 Salesforce 后删除。
5. Toxicity Detection 毒性检测: 对生成的响应进行毒性扫描。检测过程包括毒性置信度评分,该评分反映了包含有害或不当内容的响应的概率。毒性评分和类别存储在数据云中。我们可以在data cloud中运行report,选择 GenAIGatewayResponse with GenAIContentCategory report, 设置filter: Detector Type 为 toxicity。
6. Data Demasking 数据解密: 我们为在提示过程中屏蔽数据而创建的占位符现在已替换为实际数据。原始实体及其各自占位符之间的关系用于重新水合响应,以便响应在发回时有用且有意义。
7. Feedback and Audit 反馈与审核: 当 Salesforce 中出现响应时,您可以接受、修改或拒绝该响应。您还可以提供明确的反馈。您对响应的明确反馈将作为审核和反馈数据(审核跟踪)的一部分捕获并存储在 Data Cloud 中。根据人工智能功能,您对响应的隐式操作也可以被捕获并存储在数据云中。
Audit Trail also includes the original prompt, masked prompt, scores logged during toxicity detection, the original output from the LLM, and the demasked output.
审核跟踪还包括原始提示、屏蔽提示、毒性检测期间记录的分数、 LLM的原始输出以及屏蔽输出。
Audit and feedback data are stored in your instance of Data Cloud. You have control over how long that data is stored in your instance of Data Cloud. Additionally, audit and feedback data are stored by Salesforce for 30 days for compliance purposes.
审核和反馈数据存储在您的 Data Cloud 实例中。您可以控制数据在 Data Cloud 实例中存储的时间。此外,出于合规性目的,Salesforce 会将审核和反馈数据存储 30 天。
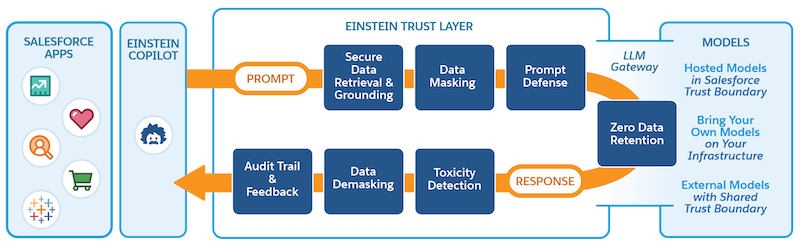
通过以上7个步骤,即完成了基于AI的内容生成一个生命周期。
总结: 篇中主要介绍 Einstein Truest Layer 如何在AI执行过程中保护数据安全以及合规处理,篇中有错误地方欢迎指出,有不懂欢迎留言。
热门资讯







