
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 经过一些实验,我们对 Transformers 智能体构建智能体系统的性能印象深刻,因此我们想看看它有多好!我们使用一个 用库构建的代码智能体 在 GAIA 基准上进行测试,这可以说是最困难、最全面的智能体基准测试……最终我们取得了第一名的成绩!
什么是智能体?
一句话: 智能体是基于大语言模型 (LLM) 的系统,可以根据当前用例的需要调用外部工具,也可以不调用,并根据 LLM 的输出进行后续步骤的迭代。工具可以包括从 Web 搜索 API 到 Python 解释器的任何东西。
形象类比: 所有程序都可以描述为图表。先做 A,再做 B。If/else 分支是图中的岔路口,但它们不会改变图的结构。我们将 智能体 定义为: LLM 输出将改变图结构的系统。智能体决定调用工具 A 或工具 B 或不调用任何工具,它决定是否再运行一步: 这些都会改变图的结构。您可以将 LLM 集成到一个固定的工作流中,比如在 LLM judge 中,但这并不是一个智能体系统,因为 LLM 的输出不会改变图的结构。
下面是两个执行 检索增强生成 的不同系统的插图: 一个是经典的,其图结构是固定的。但另一个是智能体的,图中的一个循环可以根据需要重复。
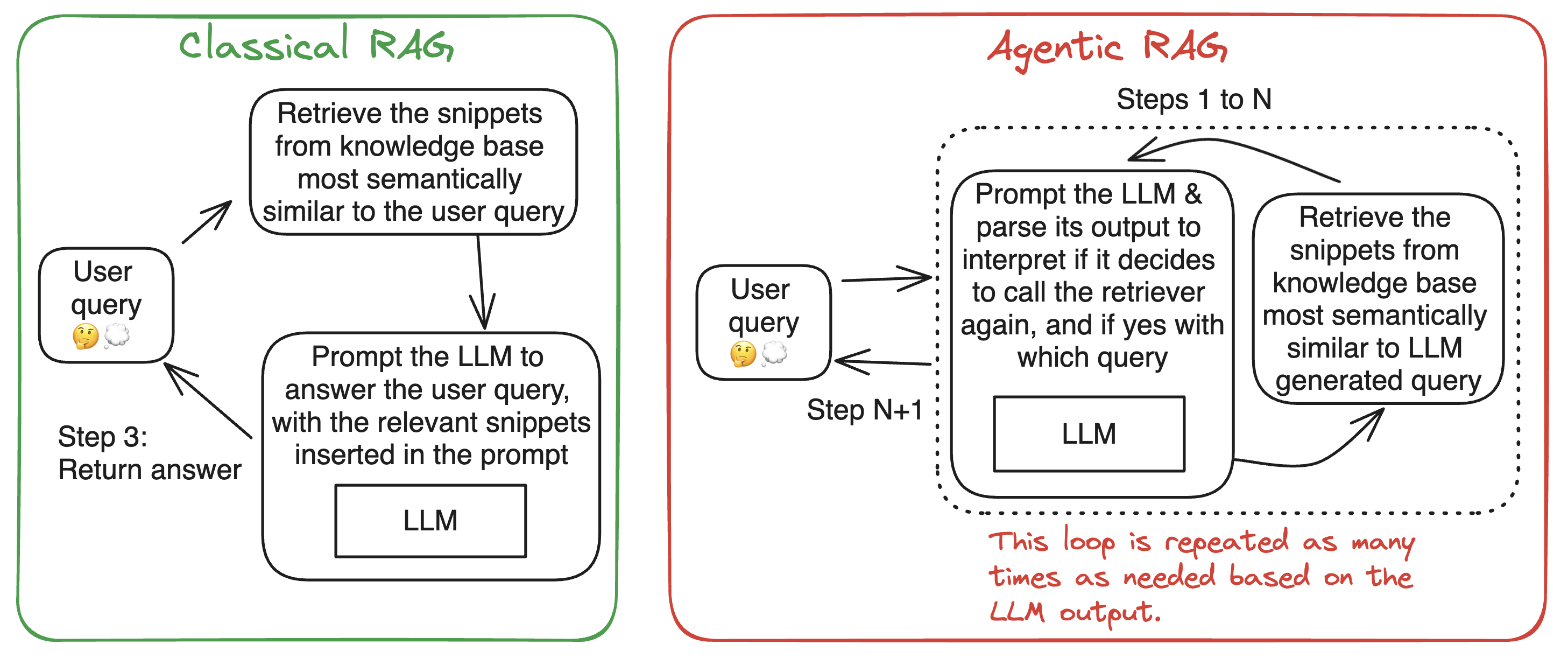
智能体系统赋予大语言模型 (LLM) 超能力。详情请阅读 我们早期关于 Transformers Agents 2.0 发布的博客 。
GAIA 是智能体最全面的基准测试。GAIA 中的问题非常难,突出了基于 LLM 的系统的某些困难。
以下是一个棘手问题的例子:
在 2008 年的画作《乌兹别克斯坦的刺绣》中展示的水果中,哪些是 1949 年 10 月海洋班轮早餐菜单的一部分,该班轮后来作为电影《最后的航程》的漂浮道具使用?请将这些水果按逗号分隔的列表给出,并根据它们在画作中的排列顺时针顺序,从 12 点位置开始。使用每种水果的复数形式。
你可以看到这个问题涉及几个难点:
解决这个问题需要高水平的计划能力和严格的执行力,这恰恰是 LLM 难以应对的两个领域。
因此,它是测试智能体系统的绝佳测试集!
在 GAIA 的 公开排行榜 上,GPT-4-Turbo 的平均成绩不到 7%。最高的提交是一种基于 Autogen 的解决方案,使用了复杂的多智能体系统并利用 OpenAI 的工具调用功能,达到了 40%。
下面让我们继续 ?

我们使用了三种主要工具来解决 GAIA 问题:
a. 网页浏览器
对于网页浏览,我们主要复用了
Autogen 团队的提交
中的 Markdown 网页浏览器。它包含一个存储当前浏览器状态的
Browser
类,以及几个用于网页导航的工具,如
visit_page
、
page_down
或
find_in_page
。这个工具返回当前视口的 Markdown 表示。与其他解决方案 (如截屏并使用视觉模型) 相比,使用 Markdown 极大地压缩了网页信息,这可能会导致一些遗漏。然而,我们发现该工具整体表现良好,且使用和编辑都不复杂。
注意: 我们认为,将来改进这个工具的一个好方法是使用 selenium 包加载页面,而不是使用 requests。这将允许我们加载 JavaScript (许多页面在没有 JavaScript 的情况下无法正常加载) 并接受 cookies 以访问某些页面。
b. 文件检查器
许多 GAIA 问题依赖于各种类型的附件文件,如
.xls
、
.mp3
、
.pdf
等。这些文件需要被正确解析。我们再次使用了 Autogen 的工具,因为它们非常有效。
非常感谢 Autogen 团队开源他们的工作。使用这些工具使我们的开发过程加快了几周!?
c. 代码解释器
我们不需要这个工具,因为我们的智能体自然会生成并执行 Python 代码: 详见下文。
如 Wang et al. (2024) 所示,让智能体以代码形式表达其操作比使用类似 JSON 的字典输出有几个优势。对我们来说,主要优势是 代码是表达复杂操作序列的非常优化的方式 。可以说,如果有比我们现有编程语言更好地严格表达详细操作的方法,它将成为一种新的编程语言!
考虑他们论文中给出的这个例子:
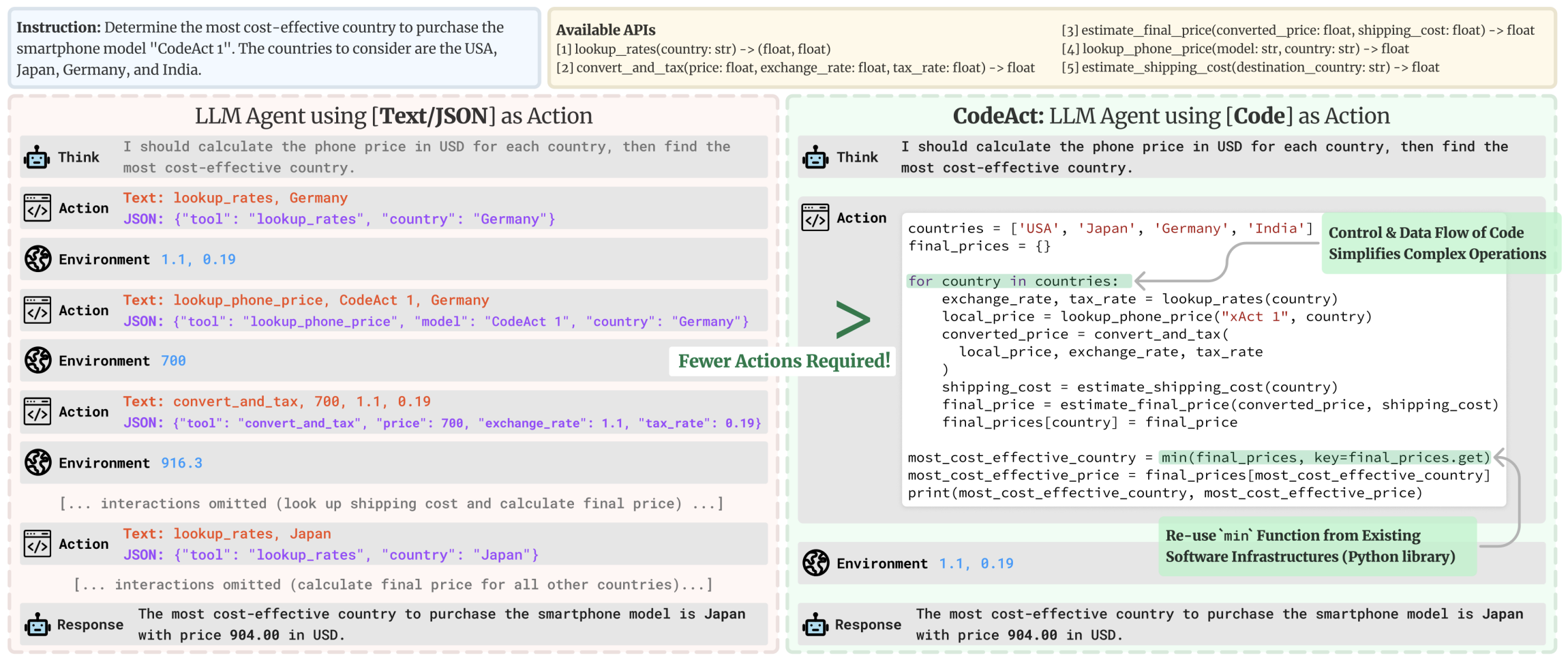
它突出了使用代码的几个优点:
我们在 agent_reasoning_benchmark 上的实验中证实了这些点。
在我们最近的构建 Transformers 智能体的实验中,我们还观察到了一些额外的优势:
LLM 生成的代码直接执行可能非常不安全。如果你让 LLM 编写和执行没有防护措施的代码,它可能会产生任何幻觉: 例如,它可能认为所有你的个人文件需要被《沙丘》的传说副本覆盖,或者认为你唱《冰雪奇缘》主题曲的音频需要分享到你的博客上!
所以对于我们的智能体,我们必须使代码执行安全。通常的方法是自上而下: “使用一个功能齐全的 Python 解释器,但禁止某些操作”。
为了更安全,我们选择了相反的方法, 从头开始构建一个 LLM 安全的 Python 解释器 。给定 LLM 提供的 Python 代码块,我们的解释器从 Python 模块 ast 提供的 抽象语法树表示 开始。它按树结构逐个执行节点,并在遇到任何未明确授权的操作时停止。
例如,一个
import
语句首先会检查导入是否在用户定义的
authorized_imports
列表中明确提及: 如果没有,则不执行。我们包括了一份默认的 Python 内置标准函数列表,如
print
和
range
。任何在此列表之外的内容都不会执行,除非用户明确授权。例如,
open
(如
with open("path.txt", "w") as file:
) 不被授权。
遇到函数调用 (
ast.Call
) 时,如果函数名是用户定义的工具之一,则工具会被调用并传递调用参数。如果是先前定义并允许的其他函数,则正常运行。
我们还做了几个调整以帮助 LLM 使用解释器:
网页浏览是一项非常上下文丰富的活动,但大多数检索到的上下文实际上是无用的。例如,在上面的 GAIA 问题中,唯一重要的信息是获取画作《乌兹别克斯坦的刺绣》的图像。周围的内容,比如我们找到它的博客内容,通常对解决更广泛的任务无用。
为了解决这个问题,使用多智能体步骤是有意义的!例如,我们可以创建一个管理智能体和一个网页搜索智能体。管理智能体应解决高级任务,并分配具体的网页搜索任务给网页搜索智能体。网页搜索智能体应仅返回有用的搜索结果,以避免管理智能体被无用信息干扰。
我们在工作流程中创建了这种多智能体协调:
file_inspector
读取文本文件,带有一个可选的
question
参数,以便根据内容只返回对特定问题的答案,而不是整个文件内容。
visualizer
专门回答有关图像的问题。
search_agent
浏览网页。更具体地说,这个工具只是一个网页搜索智能体的包装器,这是一个 JSON 智能体 (JSON 在严格的顺序任务中仍然表现良好,比如网页浏览,其中你向下滚动,然后导航到新页面,等等)。这个智能体可以访问网页浏览工具:
informational_web_search
page_down
find_in_page
将智能体作为工具嵌入是一种简单的多智能体协调方法,但我们想看看它能走多远——结果它能走得相当远!
目前有 乱糟糟的一堆 规划策略,所以我们选择了一个相对简单的预先计划工作流程。每隔 N 步,我们生成两件事情:
可以调整参数 N 以在目标用例中获得更好的性能: 我们为管理智能体选择了 N=2,为网页搜索智能体选择了 N=5。
一个有趣的发现是,如果我们不提供计划的先前版本作为输入,得分会提高。直观的解释是,LLM 通常对上下文中任何相关信息有强烈的偏向。如果提示中存在先前版本的计划,LLM 可能会大量重复使用它,而不是在需要时重新评估方法并重新生成计划。
然后,将事实摘要和计划用作额外的上下文来生成下一步操作。规划通过在 LLM 面前展示实现目标的所有步骤和当前状态,鼓励 LLM 选择更好的路径。
这是我们提交的最终代码 。
我们在验证集上得到了 44.2% 的成绩: 这意味着 Transformers 智能体的 ReactCodeAgent 现在总体排名第一,比第二名高出 4 分! 在测试集中,我们得到了 33.3% 的成绩,排名第二,超过了微软 Autogen 的提交,并且在硬核的第 3 级问题中获得了最高平均分。
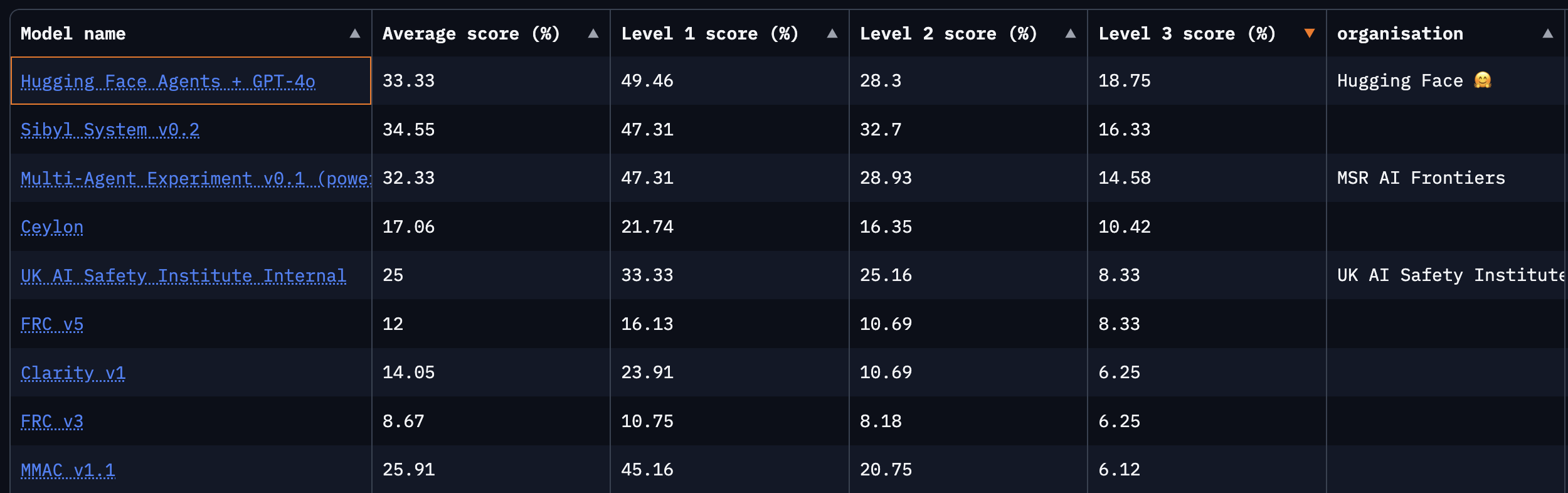
这是一个支持 代码操作效果更好 的数据点。鉴于其效率,我们认为代码操作很快将取代 JSON/OAI 格式,成为智能体记录其操作的标准。
据我们所知,LangChain 和 LlamaIndex 不支持代码操作,微软的 Autogen 对代码操作有一些支持 (在 docker 容器中执行代码 ),但它看起来是 JSON 操作的附属品。因此,Transformers Agents 是唯一将这种格式作为核心的库!
希望你喜欢阅读这篇博客!工作才刚刚开始,我们将继续改进 Transformers Agents,从多个方面入手:
selenium
包,我们可以拥有一个通过 cookie 横幅并加载 JavaScript 的网页浏览器,从而读取许多当前无法访问的页面。
请在未来几个月关注 Transformers Agents!?
现在我们已经建立了智能体的内部专业知识,欢迎随时联系我们的用例,我们将很乐意提供帮助!?
英文原文: https://hf.co/blog/beating-gaia
原文作者: Aymeric Roucher, Sergei Petrov
译者: innovation64
热门资讯







