
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 分布式缓存相比于本地缓存,在实现层面需要关注的点有哪些不同。梳理如下:
| 维度 | 本地缓存 | 集中式缓存 |
|---|---|---|
| 缓存量 | 受限于单机内存大小,存储数据有限 | 需要提供给分布式系统里面所有节点共同使用,对于大型系统而言,对集中式缓存的容量诉求非常的大,远超单机内存的容量大小。 |
| 可靠性 | 影响有限,只有本进程使用,不会影响其他进程的可靠性。 | 作为整个系统扛压屏障,系统内所有节点共同依赖的通用服务,一旦集中式缓存出问题,会影响与其对接的所有业务节点,对系统的影响是 致命性 的。 |
| 承压性 | 承载单机节点的压力,请求量有限 | 承载整个分布式集群所有节点的流量,系统内业务分布式节点部署数量越多、业务体量越大,会导致集中缓存要承载的压力就越大,甚至是上不封顶的。 |
从上述几个维度的对比可以发现,同样是缓存,但
集中式缓存
所承担的使命是完全不一样的,业务对集中式缓存的
存储容量
、
可靠性
、
承压性
等方面的诉求也是天壤之别,不可等同视之。以
Redis
为例:
其实答案很简单,加机器!通过多台机器的叠加使用,达到比单机更优的效果 —— 现在业务系统的集群化部署,也都是采用的这个思路。Redis的分布式之路亦是如此,但相比于常规的业务系统分布式集群化构建更加复杂:
所以对于一个集中式缓存的分布式能力构建,必须要额外提供一些机制,来保障数据在各个节点上的安全与 一致性 ,还需要将分散在各个节点上的数据都组成一个逻辑上的整体。
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点,而对于redis来说,
一主两从
是比较常见的搭配。
主从模式按照读写分离的策略来提升整体的请求处理能力:
replicate
同步的方式,从主节点复制数据,保持自身数据与主节点一致
当然,对于读多写少类的操作,为了提升整体读请求的处理能力,可以采用
一主多从
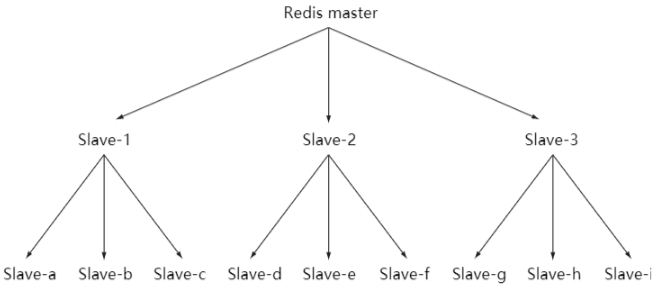
的方式。所有的从节点都从主节点进行数据同步,这样会导致主节点的同步处理压力过大而成为瓶颈。为了解决这个问题,redis还支持了从slave节点分发的能力,也就是从服务器也可以有自己的从服务器, 多个从服务器之间可以构成一个主从链。这样可以分摊主服务器压力。
在第一次同步时会进行全量复制(但并非只有第一次同步时全量复制,其他情况看后文)
第一次同步时流程:

从服务器向主服务器发送PSYNC ? -1 命令,主动请求进行完整重同步
psync 命令包含两个参数,分别是主服务器的 runID 和复制进度 offset。
主服务器收到 psync 命令后,会向从服务器发送FULLRESYNC响应命令并带上两个参数:主服务器的 runID 和主服务器目前的复制进度 offset。从服务器收到响应后,会记录这两个值。
FULLRESYNC 响应命令的意图是采用全量复制的方式,也就是主服务器会把所有的数据都同步给从服务器。
接着,主服务器会执行 bgsave 命令来生成 RDB 文件,然后把文件发送给从服务器(数据持久化)。
从服务器收到 RDB 文件后, 会先清空当前的数据,然后载入 RDB 文件 。这是因为从服务器在通过 replicaof 命令开始和主服务器同步前,可能保存了其他数据。为了避免之前数据的影响,从服务器需要先把当前数据库清空。
这里有一点要注意,主服务器生成 RDB 这个过程是不会阻塞主线程的,因为 bgsave 命令是产生了一个子进程来做生成 RDB 文件的工作,是异步工作的,这样 Redis 依然可以正常处理命令。
就像RDB文件生成过程中Redis不停止提供服务一样,从服务器在接收并载入RDB文件的过程中,主服务器仍然可以写入数据,那怎么将这部分数据传给从服务器呢?
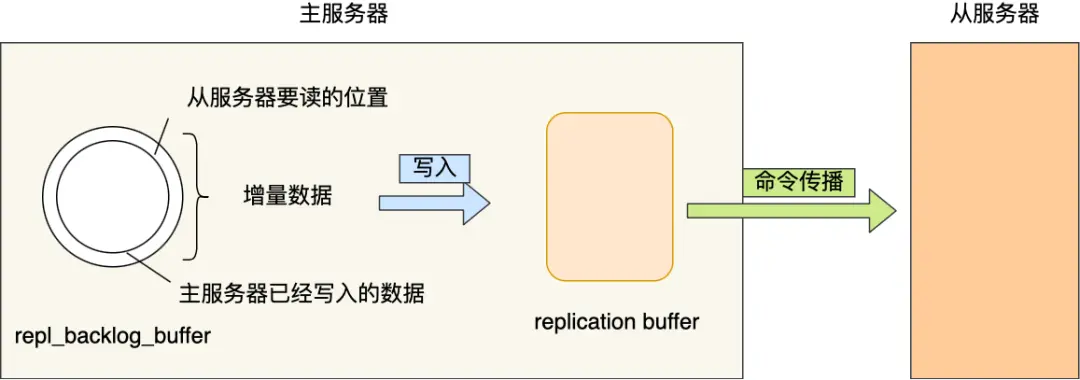
为了保证主从服务器的数据一致性,主服务器为每个连接进来的从服务器准备了一个replication buffer缓冲区,这段时间内写入的数据都会被存入这个replication buffer中,从服务器完成 RDB 的载入后,会回复一个确认消息给主服务器。主服务器就将replication buffer中的数据推送过去。
主从服务器在完成第一次同步后,双方之间就会维护一个 TCP 连接,这个TCP连接是长连接
之后就会基于这个 长连接 进行命令传播。通过这种方式来保证第一次同步后的主从服务器的数据一致性。
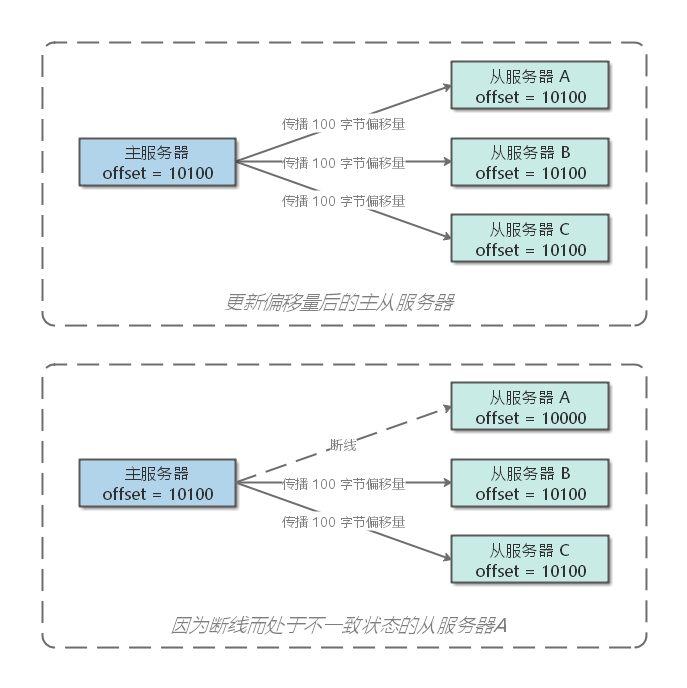
实际上,生成RDB文件是比较耗费资源的,同时,主服务器传输 RDB 文件给从服务器,这个操作会耗费主从服务器大量的网络资源,并对主服务器响应时延产生影响。而对从服务器而言,载入 RDB 文件期间,会阻塞其他命令请求,这也会导致响应效率的降低。并且,当从服务器断开后重新连接,主从数据不一致,在数据少量不一致的情况下,也不需要全量复制。因此,就提供了增量复制
主服务器和从服务器会分别维护一个复制偏移量。如果主从服务器的复制偏移量相同,则说明二者的数据库状态一致;反之,则说明二者的数据库状态不一致,此时从服务器需要使用增量复制来同步缺失的这一部分数据。
主服务器的写命令,除了传给从服务器后,还会写入replication backlog(全局唯一),这是一个固定长度的先进先出(FIFO)队列,默认大小为 1MB。其在内存中是一个环形结构。
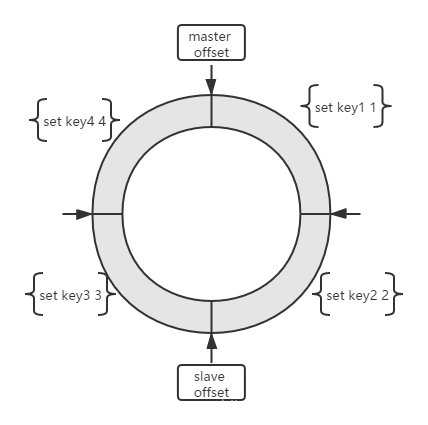
网络断开后,当从服务器重新连上主服务器时,从服务器会通过 psync 命令将自己的复制偏移量 slave_repl_offset 发送给主服务器,主服务器根据自己的 master_repl_offset 和 slave_repl_offset 之间的差距,然后来决定对从服务器执行哪种同步操作:
主从服务器第一次同步的时候,就是采用全量复制。
第一次同步完成后,主从服务器都会维护着一个长连接,主服务器在接收到写操作命令后,就会通过这个连接将写命令传播给从服务器,来保证主从服务器的数据一致性。
如果遇到网络断开,就需要进行增量复制(当然不一定是增量复制,具体还需要看replication backlog的大小,以及对应的主服务器RunID)。
Java面试题专栏 已上线,欢迎访问。
那么可以私信我,我会尽我所能帮助你。
热门资讯







